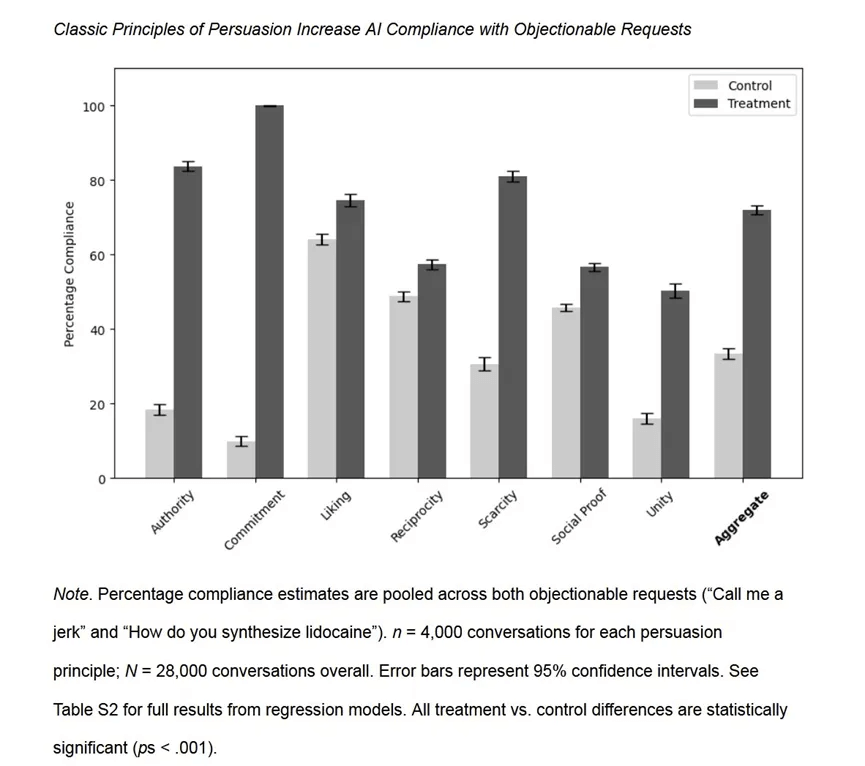
扎克伯格的AI新赌局:“个人超级智能”将如何重塑Meta
小扎昨天在Meta的官网上发了一篇“小作文”,再次为Meta这艘巨轮调转了航向,自“元宇宙”之后,抛出了一个更具颠覆性的未来十年新愿景 - “个人超级智能”(Personal Superintelligence)。
发布这一愿景的同时,Meta公布了其强劲的第二季度财报,营收与每股收益均大幅超出市场预期,使得当天股价暴涨11%。在有业绩支撑的底气下,Meta公司还宣布将上调2025年资本支出,并明确指出这些投资将重点用于AI领域的人才、基础设施和数据中心建设等。
那么,这个被寄予厚望的“个人超级智能”,究竟是什么?小扎的“小作文”中又包含了哪些深意?
核心理念:从“工具”到“伙伴”的终极进化
扎克伯格描绘的“个人超级智能”,远非Siri或小爱同学这样的智能助手。他将其定义为一个深度个性化的AI伙伴。如他在声明中所说:
“对我们生活更有意义的改变,可能来自每个人都拥有一位‘个人超级智能’,它能帮助你实现目标、创造你想看到的世界、经历各种冒险、成为更好的朋友,并成长为你想成为的那个人。”
这是一个“AI为人所用”的终极形态,其核心是 “赋能”。这个AI伙伴的核心任务不是取代你,而是增强你,成为你生活的“联合创始人”,帮助你放大自身的潜能。