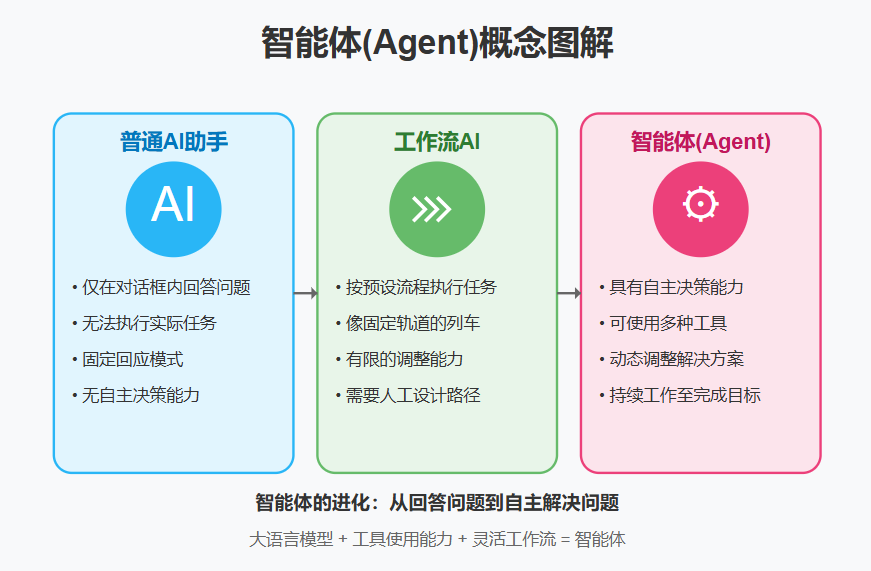
小学生都在学AI了,你还等什么?
就在前天,北京市教委发布了《北京市推进中小学人工智能教育工作方案(2025—2027年)》,我读了以后除了对这份执行方案的详尽程度大受感触外,更重要是发现这个方案:
不是试点,而是在北京市全面铺开。
从2025年秋季学期起,北京市所有中小学生 – 是的,包括那些刚刚学会系鞋带的小学生– 每学年将接受至少8课时的AI教育。这场教育变革悄然降临,却又轰轰烈烈。
1 翻开这份方案,细节之处令人惊叹
北京的AI教育不是简单地在课表上加一门课那么简单。它像一条精心设计的成长曲线:
- 小学阶段以兴趣培养为主,让孩子们在游戏中认识AI;
- 初中开始动手应用,学生能用简单工具解决实际问题;
- 到了高中,则已经具备AI实践能力,同时开始思考技术伦理问题。