清华姚班大牛看到的AI下半场:产品思维将决定人工智能的未来?
译者序
为大家推荐一篇近期看到的AI发展趋势观察好文,作者姚顺雨用”上半场与下半场”这个生动的比喻,为我们解读了人工智能正在经历的历史性转折点 - 一个让产品思维成为AI领域核心竞争力的时代。
关于作者:姚顺雨是OpenAI的研究员,清华大学姚班毕业,普林斯顿大学计算机科学博士。他是AI领域的重要研究者,论文被引用超过11,000次,是Tree of Thoughts(思维树)、ReAct、SWE-agent等突破性AI论文的作者。他的博士论文专注于”语言智能体:从下一个词预测到数字自动化”,目前参与OpenAI的Deep Research项目开发。
过去几十年,AI就像一个不断刷新考试成绩的”学霸” - 从击败围棋世界冠军到在各种标准化测试中超越人类,从AlphaGo到GPT-4再到今天的Claude 4和Gemini 2.5 Pro。但作者提出了一个非常核心的问题:
为什么AI在考试中表现如此出色,我们的日常生活和工作效率却没有发生翻天覆地的变化?用户的真实需求在哪里得到了满足?
这就是作者所说的”效用问题”(utility problem) - 你有一个功能强大的技术平台,但用户却不知道如何从中获得价值。这正是当前AI面临的核心挑战,也是产品经理最擅长解决的问题领域。
作者揭示了一个有趣的现象:在AI研究的上半场,突破性的算法论文(如Transformer)获得了16万次引用,而相应的基准测试论文只有1,300次引用。这说明过去的游戏规则是”技术为王” - 谁能发明更好的算法,谁就能获得成功。但现在,作者明确指出:
“要在这个下半场中蓬勃发展,我们需要及时转变思维方式和技能组合,这些可能更接近产品经理的角色。”
正如我不久前分享另外一篇同样来自OpenAI的Karina Nguyen的文章中提到的各种各样的研究驱动型产品经理面临的问题一样,AI的下半场将不再是纯粹的技术竞赛,而是关于如何定义正确的问题、设计合适的用户体验、创造真实的用户价值。作者发现,当AI学会了”思考”这种不直接影响外部世界的行动时,它获得了强大的泛化能力 - 这其实就是产品设计中”用户旅程”思维的体现。
文中提到的重要建议是我们需要从根本上重新思考评估方式 - 这正是产品经理思维能帮上忙的重要领域。不仅要创造更难的功能测试,更要质疑测试本身的设置是否符合用户的真实使用场景。比如,现在的AI评估通常要求系统自动运行、独立完成任务,但现实中用户与AI的互动是持续的、情境化的。一个真正有用的AI产品不应该是”一次性完美交付”,而应该能够”持续理解用户意图、实时响应需求变化”。
作者预测的未来AI竞争要素 - 如何让机器真正融入人类的工作流程、如何在现实场景中评估AI表现、如何构建真正创造价值的AI产品 - 这些都是产品经理的核心能力范畴。文章强调,下半场的重点将从”解决问题”转向”定义问题”,从关注训练转向重新思考评估,这完全契合产品经理”发现用户真实需求、设计解决方案、验证产品价值”的工作流程。
这篇文章预示了一个黄金时代的到来 - 技术已经足够强大,现在需要的是懂得如何将技术转化为用户价值的人才 - 而且提供了具体的行动指南:重新审视现有的产品评估框架,质疑那些”理所当然”的假设,设计更贴近真实用户场景的体验。
下半场的赢家将不只是实验室里的算法专家,而是能够”从智能中构建有用产品来建立价值数十亿或数万亿美元公司”的产品创新者。产品思维和用户洞察能力,可能正是决定AI能否真正改变世界的关键因素。
(译文全文如下)
下半场
作者:姚顺雨
简述:我们正处在AI的中场休息时间。
几十年来,AI主要专注于开发新的训练方法和模型。这种方法奏效了:从击败国际象棋和围棋世界冠军,到在SAT和律师资格考试中超越大多数人类,再到获得IMO和IOI金牌。在这些历史里程碑背后 - 深蓝、AlphaGo、GPT-4和o系列 - 都有AI方法的根本性创新:搜索、深度强化学习、规模化和推理。随着时间推移,一切都在变得更好。
那么现在突然有什么不同了呢?
用三个词概括:强化学习终于奏效了。更准确地说:强化学习终于能够泛化了。经过几次重大迂回和一系列里程碑的积累,我们找到了一个有效的配方,能够使用语言和推理来解决广泛的强化学习任务。即使在一年前,如果你告诉大多数AI研究者,一个单一的配方可以解决软件工程、创意写作、IMO级别的数学、鼠标键盘操作和长篇问答 - 他们会嘲笑你的幻想。这些任务中的每一个都极其困难,许多研究者花费整个博士生涯只专注于其中一个狭窄的片段。
然而它发生了。
那么接下来会怎样?AI的下半场 - 从现在开始 - 将把重点从解决问题转向定义问题。在这个新时代,评估变得比训练更重要。我们不再仅仅问”我们能训练一个模型来解决X吗?”,而是问”我们应该训练AI做什么,以及如何衡量真正的进步?”要在这个下半场中蓬勃发展,我们需要及时转变思维方式和技能组合,这些可能更接近产品经理的角色。
上半场
要理解上半场,看看它的赢家。你认为迄今为止最有影响力的AI论文是什么?
我在斯坦福224N课程中尝试了这个测验,答案并不令人意外:Transformer、AlexNet、GPT-3等。这些论文有什么共同点?它们都提出了一些根本性突破来训练更好的模型。但同时,它们都通过在某些基准测试上展示一些(显著的)改进来成功发表论文。
不过有一个潜在的共同点:这些”赢家”都是训练方法或模型,而不是基准测试或任务。即使是可以说是最有影响力的基准测试ImageNet,其引用次数也不到AlexNet的三分之一。方法与基准测试的对比在其他地方更加悬殊——例如,Transformer的主要基准测试是WMT’14,其研讨会报告有约1,300次引用,而Transformer有超过160,000次引用。
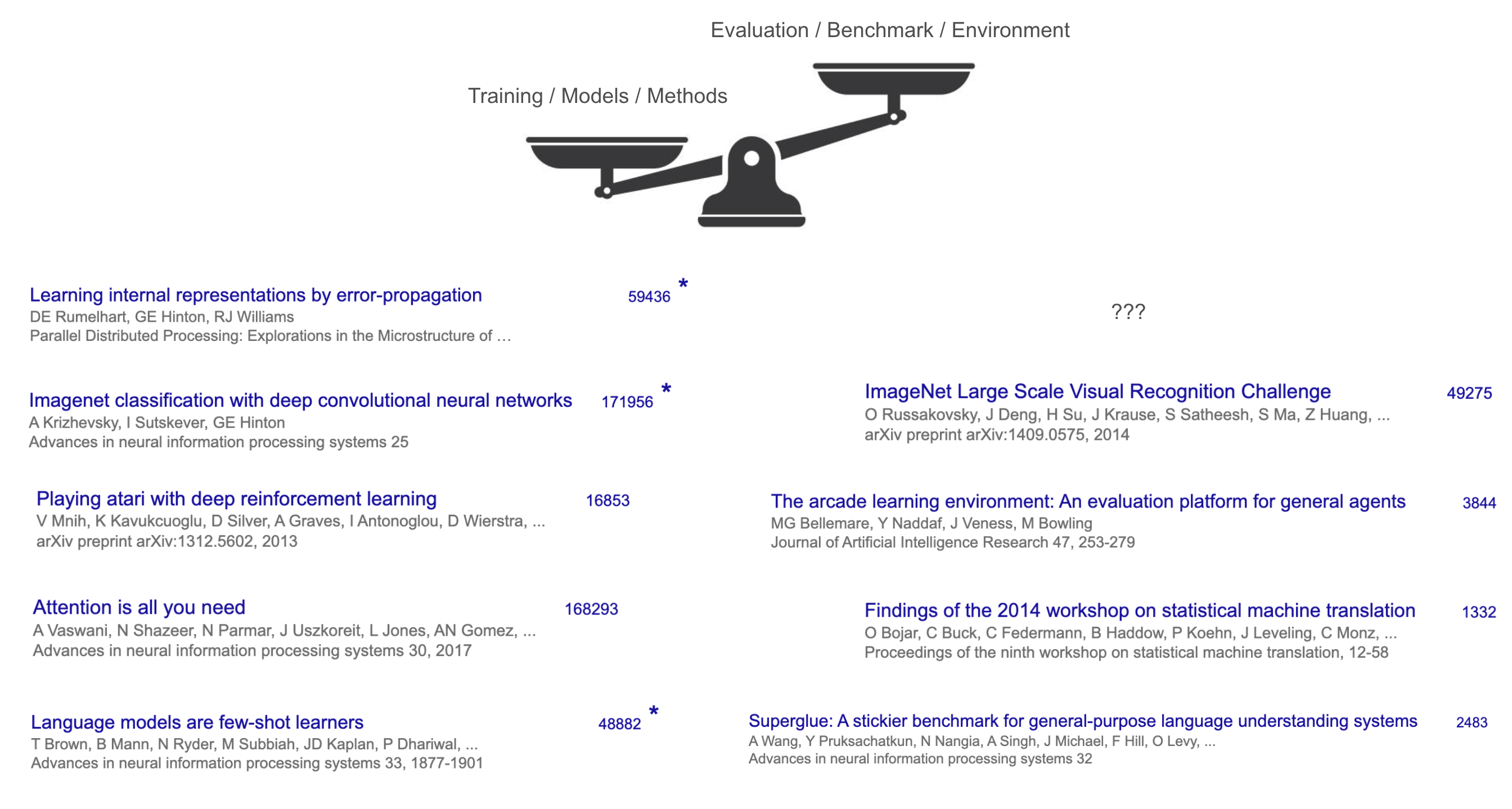
图注:姚顺雨原文中用于说明上半场方法论论文引用远超基准测试论文的示意图
这说明了上半场的游戏规则:专注于构建新模型和新方法,评估和基准测试是次要的(尽管为了让论文系统运作是必要的)。
为什么?一个重要原因是,在AI的上半场,方法比任务更困难也更令人兴奋。从零开始创造一个新算法或模型架构 - 想想反向传播算法、卷积网络(AlexNet)或GPT-3中使用的Transformer等突破性成果 - 需要非凡的洞察力和工程技术。相比之下,为AI定义任务通常感觉更直接:我们只是将人类已经在做的任务(如翻译、图像识别或下棋)转化为基准测试。不需要太多洞察力甚至工程技术。
方法通常也比单个任务更通用和广泛适用,这使它们特别有价值。例如,Transformer架构最终推动了计算机视觉、自然语言处理、强化学习和许多其他领域的进步 - 远远超出了它首次证明自己的单一数据集(WMT’14翻译)。一个出色的新方法可以爬升许多不同的基准测试,因为它简单而通用,因此影响往往超越单个任务。
这个游戏已经运行了几十年,并激发了改变世界的想法和突破,这些体现在各个领域不断增长的基准测试性能上。为什么游戏规则会改变呢?因为这些想法和突破的积累在创建解决任务的有效配方方面产生了质的差异。
配方
配方是什么?其成分毫不意外地包括大规模语言预训练、规模(在数据和计算方面)以及推理和行动的理念。这些可能听起来像你在旧金山每天听到的流行词,但为什么称它们为配方呢?
我们可以通过强化学习(RL)的视角来理解这一点,强化学习通常被认为是AI的”终极游戏” - 毕竟,强化学习在理论上保证能赢得游戏,从经验上看,很难想象任何超人系统(如AlphaGo)没有强化学习。
在强化学习中,有三个关键组成部分:算法、环境和先验。长期以来,强化学习研究者主要关注算法(如REINFORCE、DQN、TD-learning、actor-critic、PPO、TRPO…) - 智能体如何学习的智力核心——同时将环境和先验视为固定的或最小的。例如,Sutton和Barto的经典教科书全部关于算法,几乎没有涉及环境或先验。

图注:姚顺雨原文中提及的Sutton和Barto强化学习经典教科书封面
然而,在深度强化学习时代,很明显环境在经验上很重要:算法的性能通常高度特定于其开发和测试的环境。如果你忽略环境,你可能会构建一个只在玩具设置中表现出色的”最优”算法。那么为什么我们不首先弄清楚我们实际想要解决的环境,然后找到最适合它的算法呢?
这正是OpenAI的最初计划。它构建了gym,一个用于各种游戏的标准强化学习环境,然后是World of Bits和Universe项目,试图将互联网或计算机变成游戏。这是一个好计划,不是吗?一旦我们将所有数字世界变成环境,用智能强化学习算法解决它,我们就有了数字AGI。
这是一个好计划,但并没有完全奏效。OpenAI在这条道路上取得了巨大进展,使用强化学习解决了Dota、机器人手部等问题。但它从未接近解决计算机使用或网页导航,而且在一个领域工作的强化学习智能体不能转移到另一个领域。缺少了什么。
直到GPT-2或GPT-3之后,才发现缺失的部分是先验。你需要强大的语言预训练来将一般常识和语言知识提炼到模型中,然后可以微调成为网络(WebGPT)或聊天(ChatGPT)智能体(并改变世界)。结果发现强化学习最重要的部分可能甚至不是强化学习算法或环境,而是先验,这可以通过与强化学习完全无关的方式获得。
语言预训练为聊天创建了良好的先验,但对于控制计算机或玩视频游戏却没有同样好的效果。为什么?这些领域距离互联网文本的分布更远,天真地在这些领域上进行SFT/RL的泛化能力很差。我在2019年注意到了这个问题,当时GPT-2刚刚发布,我在其基础上进行SFT/RL来解决基于文本的游戏——CALM是世界上第一个通过预训练语言模型构建的智能体。但智能体需要数百万个强化学习步骤才能爬升单个游戏,而且不能转移到新游戏。虽然这正是强化学习的特征,对强化学习研究者来说并不奇怪,但我觉得奇怪,因为我们人类可以轻松玩新游戏,并且在零样本情况下表现显著更好。然后我遇到了人生中第一个顿悟时刻——我们之所以能泛化,是因为我们可以选择不仅仅做”去柜子2”或”用钥匙1打开箱子3”或”用剑杀死地牢”,我们还可以选择思考诸如”地牢很危险,我需要武器与之战斗。没有可见的武器,所以也许我需要在上锁的盒子或箱子中找到一个。箱子3在柜子2中,让我先去那里并解锁它”这样的事情。

图注:姚顺雨原文中用于说明AI智能体进行推理的示意图
思考或推理是一种奇怪的行动——它不直接影响外部世界,但推理的空间是开放的和组合无限的 - 你可以思考一个词、一个句子、整个段落或10000个随机英语单词,但你周围的世界不会立即改变。在经典强化学习理论中,这是一个糟糕的交易,使决策变得不可能。想象你需要从两个盒子中选择一个,只有一个盒子里有100万美元,另一个是空的。你的期望收益是50万美元。现在想象我添加了无数个空盒子。你的期望收益是零。但通过将推理添加到任何强化学习环境的动作空间中,我们利用语言预训练先验进行泛化,并且我们能够为不同决策提供灵活的测试时计算。这是一件非常神奇的事情,我为不能在这里完全解释清楚而道歉,我可能需要专门写另一篇博客文章。欢迎阅读ReAct了解智能体推理的原始故事以及我当时的直觉。现在,我的直觉解释是:即使你添加了无数个空盒子,你在生活中的各种游戏中都见过它们,选择这些盒子为你在任何给定游戏中更好地选择有钱的盒子做准备。我的抽象解释是:语言通过智能体中的推理进行泛化。
一旦我们有了正确的强化学习先验(语言预训练)和强化学习环境(将语言推理添加为动作),结果发现强化学习算法可能是最琐碎的部分。因此我们有了o系列、R1、深度研究、计算机使用智能体,以及更多即将到来的。多么讽刺的转折!长期以来,强化学习研究者对算法的关心远超过环境,没有人关注先验——所有强化学习实验本质上都从零开始。但我们花了几十年的迂回才意识到也许我们的优先级应该完全颠倒。
但正如史蒂夫·乔布斯所说:你无法向前看时连接点;你只能向后看时连接它们。
下半场
这个配方完全改变了游戏规则。回顾上半场的游戏:
- 我们开发新颖的训练方法或模型来爬升基准测试。
- 我们创建更困难的基准测试并继续循环。
这个游戏正在被破坏,因为:
- 配方本质上已经标准化和工业化了基准测试爬升,而不需要太多新想法。随着配方的规模化和良好泛化,你针对特定任务的新颖方法可能提高5%,而下一个o系列模型在没有明确针对它的情况下提高30%。
- 即使我们创建更困难的基准测试,很快(而且越来越快)它们就会被配方解决。我的同事Jason Wei制作了一个漂亮的图表来很好地可视化这个趋势:
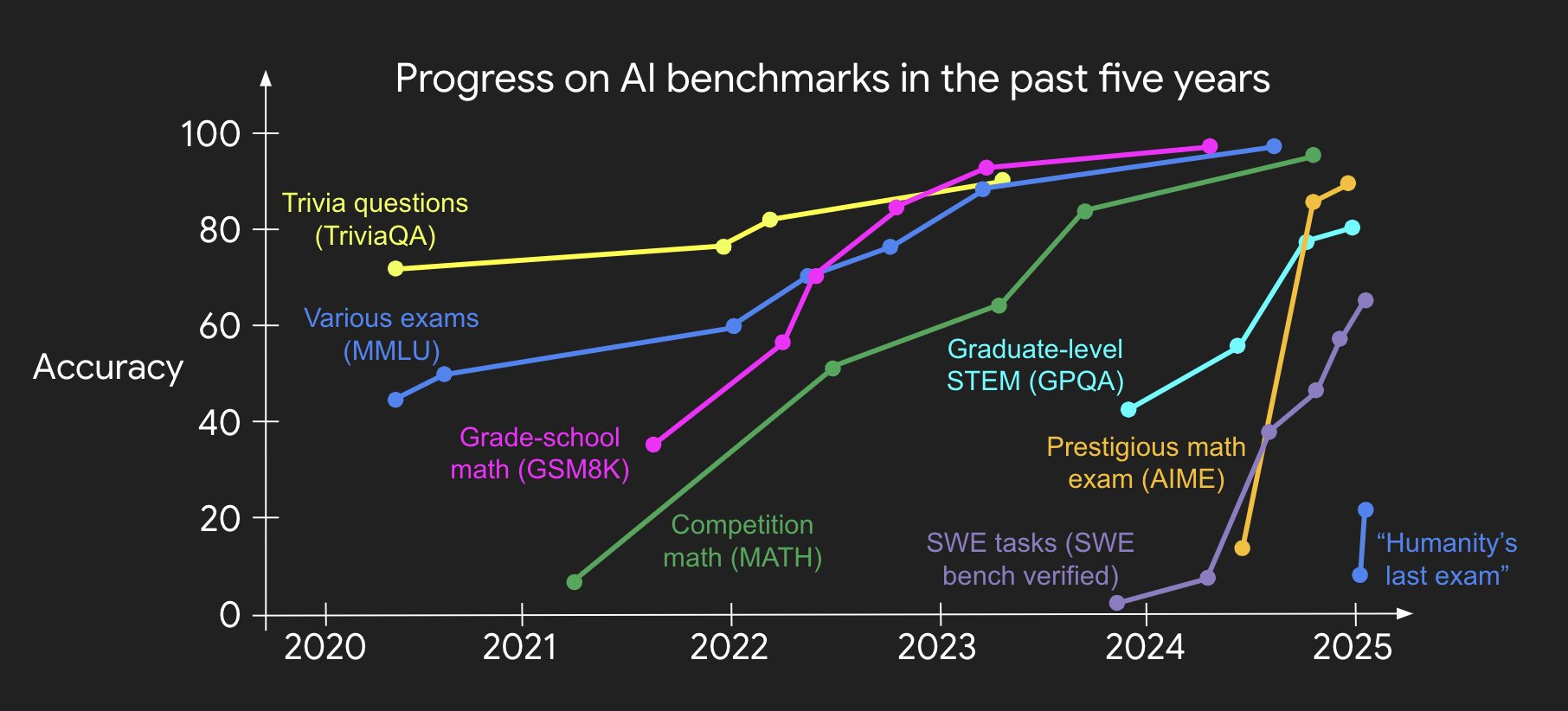
图注:姚顺雨原文中Jason Wei制作的展示AI在基准测试上进展迅速的图表
那么在下半场还剩下什么可玩的?如果不再需要新颖的方法,更困难的基准测试只会越来越快地被解决,我们应该做什么?
我认为我们应该从根本上重新思考评估。这意味着不仅要创建新的更困难的基准测试,而且要从根本上质疑现有的评估设置并创建新的设置,这样我们就被迫发明超越现有配方的新方法。这很困难,因为人类有惯性,很少质疑基本假设——你认为它们是理所当然的,没有意识到它们是假设,而不是定律。
为了解释惯性,假设你发明了历史上最成功的基于人类考试的评估之一。这在2021年是一个极其大胆的想法,但3年后它饱和了。你会做什么?最可能创建一个更困难的考试。或者假设你解决了简单的编码任务。你会做什么?最可能找到更困难的编码任务来解决,直到你达到IOI金牌水平。
惯性是自然的,但问题在这里。AI已经击败了国际象棋和围棋世界冠军,在SAT和律师资格考试中超越了大多数人类,并在IOI和IMO上达到了金牌水平。但世界并没有发生太大变化,至少从经济和GDP来判断。
我称之为效用问题,并认为它是AI最重要的问题。
也许我们很快就会解决效用问题,也许不会。无论哪种方式,这个问题的根本原因可能极其简单:我们的评估设置在许多基本方面与现实世界设置不同。举两个例子:
- 评估”应该”自动运行,所以通常智能体接收任务输入,自主做事,然后接收任务奖励。但在现实中,智能体必须在整个任务过程中与人类互动——你不会只是给客服发一条超长消息,等待10分钟,然后期望得到详细回应来解决一切。通过质疑这种设置,发明了新的基准测试,要么让真实人类参与循环(如Chatbot Arena),要么进行用户模拟(如tau-bench)。

- 评估”应该”独立同分布运行。 如果你有一个包含500个任务的测试集,你独立运行每个任务,平均任务指标,得到总体指标。但在现实中,你是顺序而不是并行解决任务的。谷歌软件工程师随着对代码库越来越熟悉,解决google3问题越来越好,但软件工程智能体在同一个代码库中解决许多问题而没有获得这种熟悉度。我们显然需要长期记忆方法(也有),但学术界没有适当的基准测试来证明这种需求,甚至没有适当的勇气来质疑一直是机器学习基础的独立同分布假设。
这些假设”一直”都是这样的,在这些假设下开发基准测试在AI的上半场是可以的,因为当智能水平较低时,提高智能通常会提高效用。但现在,一般配方保证在这些假设下工作。所以下半场新游戏的玩法是:
- 我们为现实世界效用开发新颖的评估设置或任务。
- 我们用配方解决它们或用新颖组件增强配方。继续循环。
这个游戏很困难,因为它不熟悉。但它令人兴奋。虽然上半场的玩家解决视频游戏和考试,下半场的玩家通过从智能中构建有用产品来建立价值数十亿或数万亿美元的公司。虽然上半场充满了增量方法和模型,下半场在某种程度上过滤了它们。一般配方会粉碎你的增量方法,除非你创建打破配方的新假设。然后你就能做真正改变游戏规则的研究。
欢迎来到下半场!
致谢
这篇博客文章基于我在斯坦福224N和哥伦比亚大学的演讲。我使用OpenAI深度研究来阅读我的幻灯片并写初稿。
原文链接:The Second Half