最新大模型论文科普解读 – 为什么聊着聊着AI就“糊涂”了?
我在之前一篇《大语言模型特性科普系列:从ChatGPT的“迷惑行为”说起》中提到过一个经典案例:当你反复“戏弄”ChatGPT,追问它”strawberry”这个英文单词中里有几个”r”并持续坚持说它错了,它最终会陷入越来越混乱的胡言乱语。
这种“AI突然变笨”的挫败感,相信不少深度AI用户都或多或少体验过。而现在,一篇来自微软研究院和Salesforce研究院的论文《LLMs Get Lost in Multi-Turn Conversation》(大语言模型在多轮对话中迷失),对这种“AI小迷糊”现象进行了细致入微的剖析。
论文开篇明义地指出:“当LLM在对话中拐错了一个弯,它们就迷路了,并且无法恢复。”

“聊着聊着就崩了”的残酷真相
这篇论文的研究员们进行了一场堪称“AI对话马拉松”的大规模模拟实验,拉来了市面上几乎所有叫得上名号的LLM“选手” - GPT系列、Claude、Gemini等15位顶尖高手,让它们在超过20万次的模拟对话中接受考验。任务涵盖了从Python编程到文本摘要等六大领域。
结果呢?就像一位平时短跑成绩优异的选手,突然被拉去跑全程马拉松一样,这些LLM在多轮对话中的平均表现,竟然比单轮“冲刺”时暴跌了39%!也就是说,这些特别聪明的AI,仅仅因为你把问题拆解成几步来问,它的“智商”就直接打了六折,这是相当令人沮丧的体验。根据论文中的“渐进式分片实验”(Gradual Sharding Experiment)显示,哪怕只是将指令拆分成短短的两回合对话,这种性能下降和不可靠性剧增的“迷失”现象就已经非常显著了。
研究还进一步“解剖”了这39%的性能损失,发现它由两部分构成:
- “真忘了” - 能力衰退(Loss in Aptitude):大约15%的问题,AI在多轮对话中是彻底“投降”了,直接答不上来。就像聊着聊着,它突然忘记了自己本来会的技能;
- “变卦了” - 不可靠性剧增(Increase in Unreliability):这部分更要命,不可靠性飙升了高达112%!这意味着AI的回答变得极不稳定,同样的问题,多聊几轮,它可能一会儿给A答案,一会儿给B答案,让你完全摸不着头脑;
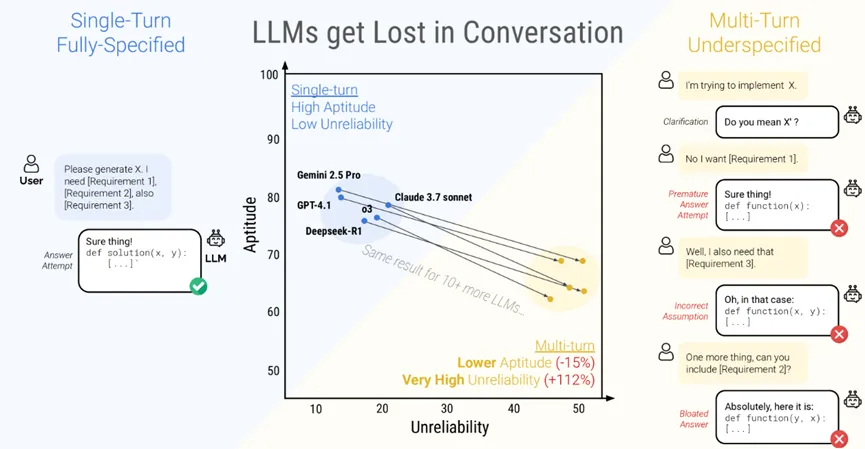
图1:论文核心图示,清晰展现了LLM在单轮(左)与多轮(右)对话中能力(Aptitude)与不可靠性(Unreliability)的显著差异
AI为何在长聊中“迷失自我”?
那么,这些聪明的AI们为何一进入长聊模式就容易“短路”呢?研究者们通过对海量对话日志的分析,挖出了几个关键的“病根”:
- 急于“盖棺定论”(Premature Answer Attempts):很多LLM像个急脾气的助手,往往在对话初期,信息尚不完整(即“指令未充分指定”时)就匆匆忙输出“最终方案”。根据论文数据显示,首次尝试回答的时机越早(例如在对话进程的前20%),最终的平均性能得分越低。这种基于不完整信息的“抢答”,自然容易埋下隐患;
- “答案越改越臃肿”(Answer Bloat):随着对话进行,如果LLM需要修改之前的答案,它们往往不是精简和修正,而是在原有基础上不断叠加,导致答案越来越长,越来越复杂。论文数据清晰地展示了在代码、数据库、数据到文本和摘要任务中,SHARDED模式下的答案长度(字符数)随着尝试次数的增加而显著增长,远超FULL和CONCAT模式下的答案长度。甚至在最终给出正确答案的情况下,多轮对话产生的代码也平均长了27%(针对Code任务)。这不仅增加了用户的理解成本,也可能引入新的错误;
- “喜新厌旧,遗忘中间”(Over-adjust based on Last Turn / Loss-in-middle-turns):在处理需要整合多轮信息的长对话时(论文中以“摘要”任务为例),LLM似乎更关注对话的初期和最新一轮的信息,而夹在中间的那些“陈年旧事”则容易被“遗忘”或降低权重。这种“中间信息丢失”现象,与它们在处理长文本时出现的“Lost in the Middle”问题如出一辙,只是场景从单轮长文本延伸到了多轮对话的上下文中。
- “言多必失”(Overly-verbose Assistant Responses):原论文Table 7显示,在多数任务中,当LLM的回复越冗长,其平均性能得分反而越低。研究者推测,过于冗长的回答可能包含了更多模型自己做出的假设,这些假设若与用户后续提供的信息冲突,就会导致混乱。简洁、聚焦的回复(例如,一个清晰的澄清式提问)反而能让对话更顺畅。
这些因素共同作用,使得LLM在信息逐步呈现、需要不断整合和修正理解的多轮对话中,一旦早期理解出现偏差或做出错误假设,就很难再回到正确的轨道上来,最终陷入“迷路”。
精心设计的“对话迷宫”:如何模拟真实的“逐步深入”
为了尽可能模拟真实世界中那种“你一句,我一句”的对话模式,研究者们设计了一种巧妙的实验方法 - 核心在于“指令分片”(Instruction Sharding)和不同的“对话模拟类型”(Conversation Simulation Types)。
- 指令分片(Sharding Process):他们将原本在单轮中完整给出的指令(例如,一个编程题目的所有要求),通过半自动化的方式(LLM辅助分割、人工审核),拆解成多个信息“碎片”(shards)。每个“碎片”包含原始指令的一部分信息,第一个碎片通常是核心意图,后续碎片则是对细节的补充和澄清;
- 对话模拟类型:
- FULL(完整模式):AI一次性收到原始的、完整的指令——这是理想化的“实验室”对照组;
- CONCAT(拼接模式):AI也是一次性收到所有信息,但这些信息是“分片后又拼接起来的”,用来验证分片过程本身是否造成信息损失。结果显示,CONCAT模式性能与FULL模式相近(平均为其95.1%),说明分片过程基本不丢信息,问题主要出在“多轮”上;
- SHARDED(分片多轮模式):这才是真正的“大考”。用户模拟器(由另一个LLM如GPT-4o-mini扮演)在每一轮对话中,只透露一个“信息碎片”给被测试的LLM。这最能模拟真实世界中我们与AI逐步沟通的过程;
- RECAP(总结模式)和SNOWBALL(滚雪球模式):作为可能的改进探索,这两种模式尝试在对话中加入信息回顾机制。RECAP是在最后增加一个总结所有用户指令的回合;SNOWBALL则更进一步,每一轮都重复之前所有已揭示的信息,再加上新的信息;
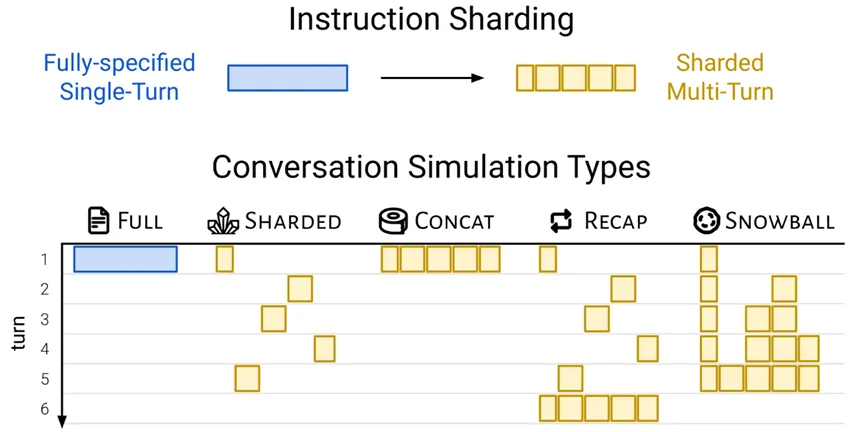
图2:研究中设计的指令分片及多种对话模拟类型,用于精确对比和分析LLM在不同交互模式下的行为
“学霸”也逃不过的“迷路定律”:温度、算力都难救场
一个自然的疑问是:是不是那些更强大、更“聪明”的LLM就能更好地应对多轮对话呢?论文中给出的结论是:几乎所有参与测试的LLM,无论大小新旧,在SHARDED模式下都出现了显著的性能下滑,平均30-40%的性能降幅是家常便饭。 即使是那些在单轮任务中表现卓越的顶尖模型,也没能幸免。
研究者还发现:
- 额外的“思考时间”也无效:像o3和Deepseek-R1这类带有额外推理步骤(test-time compute)的模型,在多轮对话中同样“迷失”,其性能下降幅度与其他模型类似。甚至,因为它们倾向于生成更长的回复(平均长33%),反而可能更容易引入混淆;
- 降低“温度”(Temperature)也难救:通常我们认为将LLM的温度参数调低(例如到0)可以使其输出更具确定性,从而提高可靠性。然而,论文数据显示,在单轮的FULL或CONCAT模式下,降低温度确实能大幅减少不可靠性(降低50-80%)。但在多轮的SHARDED模式下,即使将用户模拟器和被测LLM的温度都降到0,不可靠性依然居高不下(仍有约30%)。研究者解释道:“单轮对话中偏差的范围有限,而在多轮对话中,早期回合中一个token的差异就可能导致级联的偏差。”
有趣的是,研究者还测试了一个“翻译”任务(将德语句子分批给模型翻译成英文,但在这个任务上,LLM们并没有表现出明显的“迷失”。研究者推测,这是因为翻译任务在某种程度上是“片段化”(episodic)和“可分解”(decomposable)的 - 每轮翻译新的句子,对之前翻译结果的影响相对独立。这反过来印证了,那些需要将多轮信息真正“融合”起来形成一个不可分割的整体解决方案的任务(如编程、复杂问答),才是LLM“迷失”的重灾区。
这研究对我们意味着什么?给用户和开发者的启示
- 对普通用户而言:
- “再试一次”胜过“死磕到底”:当你感觉AI开始胡言乱语时,纠缠下去往往效果不佳。不如干脆“另起炉灶”,重新开始一段对话,把你的需求一次性、清晰地表述出来(类似CONCAT模式),效果可能出奇地好。论文明确建议:“如果时间允许,再试一次。与继续一个已经混乱的对话相比,重新开始一个重复相同信息的对话可能会产生显著更好的结果。”
- 主动“整合信息”:在向AI提复杂需求时,尽量自己先梳理清楚,一次性把所有条件和要求说完整,减少让AI在多轮中“猜谜”和“拼图”的机会。你甚至可以先让AI帮你“总结一下我们目前聊到的所有要点”,然后把这个总结拿到新的对话中使用;
- 对AI系统和Agent构建者而言:
- 简单的“套壳”Agent可能意义不大:指望通过Agent框架(如LangChain, Autogen)将多轮交互的复杂性完全屏蔽,把LLM只当做单轮工具调用,可能无法根本解决问题。研究中测试的RECAP和SNOWBALL这种“内置信息重复”的Agent策略,虽然比单纯的SHARDED模式有所改善(提升15-20%),但性能仍远不及FULL模式。这表明,LLM自身原生支持可靠的多轮交互能力至关重要;
- 对LLM研发团队而言:
- “可靠性”应与“能力”并重:目前LLM的研发竞赛似乎更侧重于提升模型的“能力上限”(Aptitude),例如在各种复杂的单轮基准测试中取得高分。但这项研究提出:请同时关注模型的“可靠性”,尤其是在多轮对话中的可靠性! 一个在90%的情况下能给出完美答案,但在另外10%情况下完全离谱的模型,其实用性会大打折扣。研究者对可靠的LLM提出了三点期望:1) 在单轮和多轮设置中能力相近;2) 在多轮设置中不可靠性低(论文期望其波动范围小于15%) ;3) 在默认温度下就能做到以上两点;
结语
那么,LLMs注定只能擅长单次对话中表现优异,而无法胜任“深度长聊”的重任吗?我倒不这么认为。
虽然论文在局限性分析中坦言,他们所模拟的对话环境其实还算是“仁慈”的,真实世界中用户与AI的互动可能更加复杂和不可预测,因此,目前观察到的性能下降“很可能低估了”LLM在真实多轮对话中的不可靠程度。但这篇论文的价值,或许就在于推动AI研究者们去攻克这个难题,让未来的LLM不再那么容易在长聊中“迷路”。
而且,正如我在之前科普文章中探讨的,LLM的这些特性,与人类交流既有相似之处(我们也会因偏见而固执,因信息过载而遗忘),又有本质不同。人类的对话记录(无论在脑海中还是聊天软件里)是持久的,一旦说出口,影响深远。而与AI对话时,我们幸运地拥有一个“超能力” - 随时可以“清零重启”。
因此,一方面,我们要理解这些先进模型依然在多轮对话中有其局限性;另一方面,当下次你发现AI助手陷入某种“固执”的思维定式时,请尝试跳出当前的循环,给予彼此一个“重新开始”的机会。