AI排行榜“失真”?当大厂们用“模拟考”碾压全场时,我们能如何知道什么是真正领先?
很多人应该和我有过一样的经历:每次到了个新地方,想根据大众点评的美食排行榜来找餐厅吃饭的时候,会发现很多“高分网红餐厅”其实味道平平,甚至不如街角那家不知名的小馆子来得惊艳。到后来才明白,原来这些排行榜的分数都是可以刷的…
当你接受了“只要有排行榜的地方就有江湖”这个道理以后,就会发现其实AI圈也不例外。在大模型核心圈风头正劲的LMArena排行榜,最近被一篇研究报告推上了舆论的风口浪尖 - 这篇由MIT、斯坦福和Cohere等顶尖机构联合发布的《排行榜的幻觉》(The Leaderboard Illusion),直指LMArena可能存在偏袒大型科技公司的“潜规则”。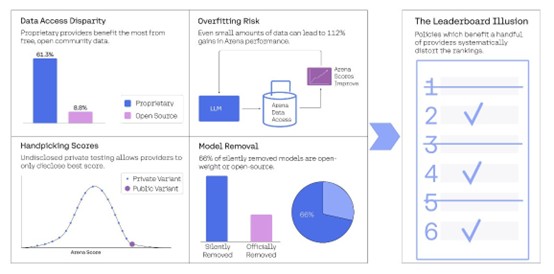
LMArena到底怎么玩?这场‘盲测’游戏的规则
可能有些朋友对LMArena还不太熟悉,我简单介绍一下它的运作模式。你可以把它想象成一个大模型的“盲测擂台”:
- 匿名对决:你向平台提问,系统会随机挑选两个匿名的AI模型分别给出回答;
- 用户投票:你比较两个回答,选出你认为更好的那个,也可以宣布平局或都不满意;
- 揭晓身份:投完票,平台才会告诉你刚才比拼的是哪两个模型;
LMArena官方文档提到,通过这个过程会产生大量真实用户提出的多样化问题。他们再运用Elo评分算法(常用于棋类等竞技排名)来估算模型的相对实力,最后绘制出一个AI大模型的排行榜。
LMArena一经推出就广受欢迎 - 因为大家对传统的实验室评测基准(比如MMLU这种,可以理解为AI的“高考”)早就有点“审美疲劳”了。很多传统评测基准都存在着各种问题,也容易成为刷分的重灾区。所以,LMArena这种更侧重普通用户反馈的模式,感觉上更“接地气”和更“公正”一些,
但,也仅仅是“相对”而已。
正如我之前在这篇《Chatbot Arena的偏见与透明性困境:AI评测体系的反思》内容中已经提到过一些LMArena的局限性:例如评测偏好过于依赖“讨喜型”回答、用户样本结构不透明等。而这次的研究报告,则揭开了它更深层的“潜规则”。
“模拟考”+“删分权”:大厂的隐藏特权?
如果在一场重要的考试中,有些“优等生”可以偷偷进行无数次“模拟考”,只把考得最好的那次成绩拿出来示人,甚至还能悄悄“删除”那些不理想的“黑历史”。这公平吗?
《排行榜的幻觉》研究报告指出,以Meta这次发布Llama-4为例,其实他们在正式发布之前,就悄悄测试了多达27个私有模型变体!最后公之于众的,自然是其中表现最亮眼的那个。这种“优中选优”的策略,就像开了“上帝视角”,直接让其他兢兢业业、一次定胜负的“寒门选手”怎么比?研究者认为,这种做法已经违反了Elo评分算法的统计学假设。
更令人咋舌的是,那些表现不佳的“废弃稿”,就这么无声无息地消失了。你甚至都不知道它们曾经存在过。
“聚光灯”下的偏爱:谁能获得更多的“曝光机会”?
除了“私下测试”, 另一种“无形优势”则体现在对战曝光率上。
研究数据显示,来自大厂的专有闭源模型,似乎总能获得更多的“用户对战”机会 - 谷歌和OpenAI的模型各自拿下约20%的竞技场对战量,相比之下,83个开放权重模型总共才分得29.7%的份额,41个完全开源模型更只有可怜的8.8%。
换句话说,闭源大厂模型比开源模型多出将近19.2倍的曝光机会。而在LMArena这个“谁被选中谁就有训练数据”的机制中,曝光就意味着它们能更快地从用户反馈中学习、迭代,甚至,针对性地“优化”自己在排行榜上的表现。
研究表明,仅仅少量竞技场数据,就可能让模型在LMArena上的表现提升高达112%!甚至有实验显示,用70%的LMArena数据进行训练后,模型胜率能从23.5%飙升到49.9%。如果类比一位刷了无数遍“真题”和“模拟题”的学生,在特定题型上,他可能会表现得越来越好。但这种提升,是真的掌握了知识,还是仅仅“记住”了出题套路?
而这种可能被“优化”出来的排名,正影响着数十亿美元的投资决策,以及顶尖实验室的人才招聘方向。
“沉默的大多数”:被悄悄移除的模型们
更让人不安的是研究中提到的“模型大清洗” - 数据显示,在统计的243个模型中,竟然有205个被悄悄移除!其中,87.8%的开放权重模型和89%的开源模型“消失”了,相比之下,80%的专有模型依然“健在”。
这意味着,开源模型面临着更高的“淘汰率”,但这到底是性能不佳的自然结果,还是由于资源与机制的不对等导致的结构性偏见?我们不得而知。
风波后的自救:LMArena的回应与反思
面对如此重磅的指控,LMArena自然也做出了回应。他们承认了改进的必要性,承诺会提升透明度,完善统计方法。但同时也为“预发布测试”等行为辩护,认为这有助于AI社区的创新和迭代。当然,业界的疑虑并未就此打消。这场风波,更像是一面镜子,照出了AI发展过程中,评估体系的复杂性和脆弱性。
沃顿商学院教授Ethan Mollick就曾怀疑,LMArena这种依赖“感觉”(vibes)的评判方式,很容易通过针对性的“优化”来刷分,这并不能真正提升模型性能,只是让它们更“讨喜”。就连Elon Musk也曾在今年二月略带调侃地表示,他们全靠“留了一手”才保住了Grok-3模型的第一。
我们需要怎样的“尺子”来衡量AI的进步?
那么,我们到底该如何建立一个更公平、更透明、更能反映模型真实能力的评估体系呢?
Ruben Hassid在他的帖子中给出了一些建议,我觉得很有启发:
- 公开所有提交记录:无论是成功还是“翻车”,都应该公之于众;
- 区分对待:将那些在竞技场数据上训练过的模型与“纯天然”的模型分开评估;
- 平等的“退役”机制:无论是专有模型还是开源模型,都应遵循相同的弃用标准;
- 严格限制私下测试:减少“暗箱操作”的空间;
- 引入独立审计:确保评估过程的公正性;
这些建议,指向了一个共同的目标:透明化。
我的建议:参考,而不依赖;观察,而不盲从
最后也分享一下我目前个人如何评判一款新模型的好坏,最靠谱的当然是要亲自实测,然后再结合“观察模型发布一周后核心AI圈在社媒上的反馈” - 如果好评如潮,那基本错不了。
而对于LMArena这个平台,尽管它有诸多问题,但目前依然是相对最有价值的用户评估平台之一。它不是“终局答案”,却可以作为“初步筛选” - 只要你始终记得:排行榜不是考试的成绩单,而是面试时的观感评分。
真正值得信赖的,是你自己的判断力。