Llama 4 发布后我的三点观察:开源大模型的新平衡点?
昨晚Meta 悄悄地放出了 Llama 4 系列模型,一下子扔了三个名字很燃的版本:Scout(侦察兵)、Maverick(特立独行者)、Behemoth(巨兽),并直接在 Hugging Face 上开放了下载。
在社交媒体上的AI技术圈瞬间引发了热议,关键词包括:
- 上下文窗口突破到 1000 万 tokens(Scout);
- 全系多模态输入(图+文);
- 混合专家架构(MoE),只激活 17B 参数;
- 模型部署亲民:Scout 单卡可跑;
有惊喜也有争议。我花了点时间通读发布说明、读了下benchmark、刷了社媒上的开发者热帖,试着理一理这波 Llama 4 到底意味着什么。
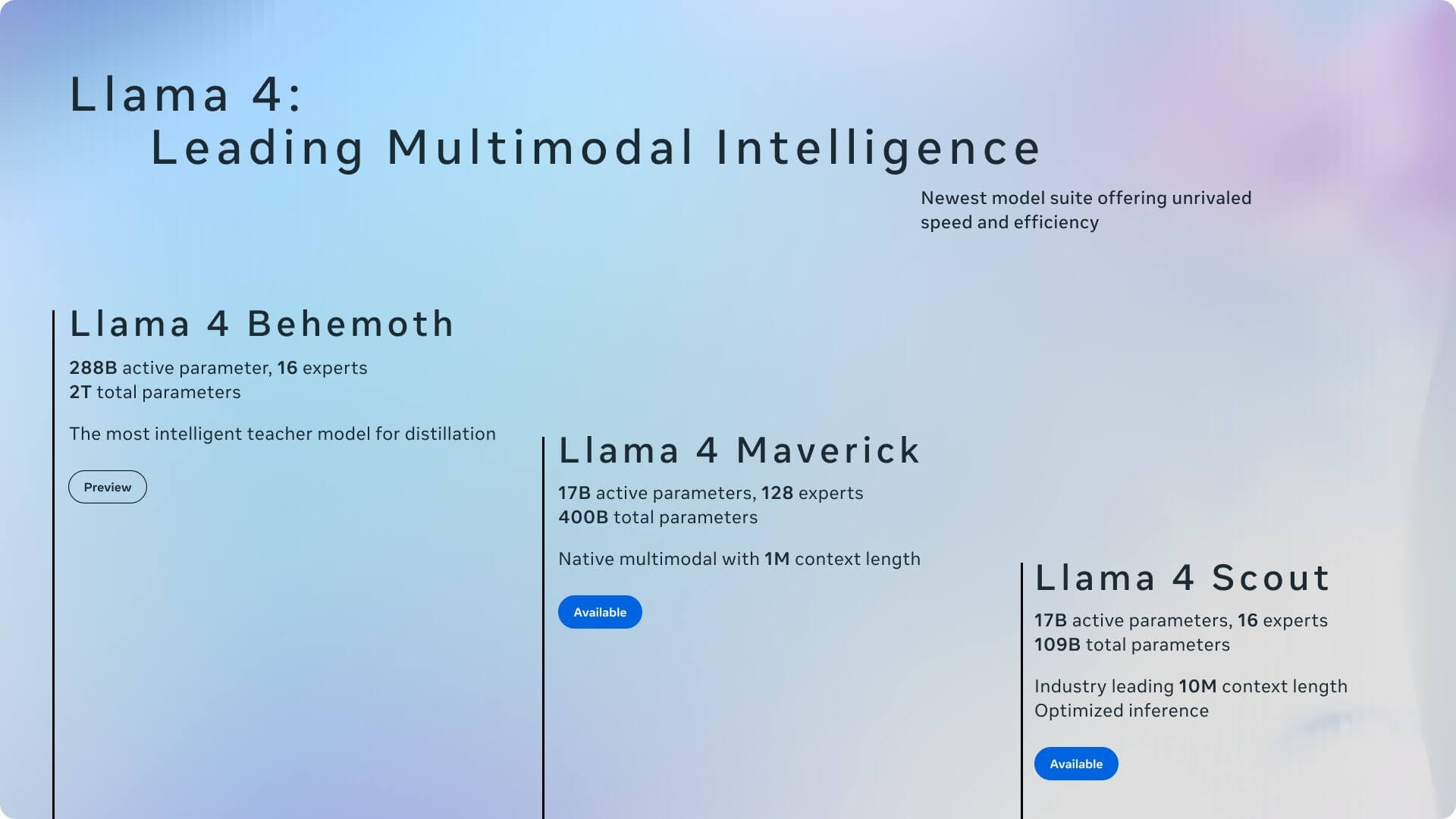
我最关注的3个点
1. 上下文窗口疯了:1000 万 tokens(Scout)
简单来说,上下文窗口决定了 AI 模型一次能“记住”和处理多少信息 - GPT-4.5、Claude 3.7和DeepSeek R1这些主流大模型的上下文窗口一般在 128k~200k 之间,这次Scout直接干到 10M(强如 Google 的 Gemini系列也就是1M Token),确实震撼!
这意味着什么?
- 能一口气“读”完超长文档: 几百万字的小说、厚厚的财报、复杂的法律文件,Scout 都能 hold 住,帮你总结、分析、问答;
- 分析整个代码库不再是梦: 把一个大型项目的全部代码“喂”给 Scout?理论上已经可行 - 让它帮你理解代码逻辑、找 Bug!
- 多轮对话记忆力 Max: 跟你聊上三天三夜,可能还记得你开头说了啥;
2. 多模态 + MoE 架构:更聪明但更省资源
Llama 4 首次在开源中引入大规模 MoE 架构,例如 Maverick 有 400B 总参数,但每次推理只激活 17B(共 128 个专家模型)。这让训练和推理都更加节能。
而且它是原生多模态,能输入图像(虽然输出还是纯文本),相比之前的“贴图外挂”方案要自然得多。图像输入支持最多 8 张图,Scout 和 Maverick 都能理解视觉内容,是未来代码+设计类协作场景的潜力股。
3. Scout 单卡就能跑,部署门槛降低
Scout 在 INT4 量化后可在单张 H100 上跑起来 - 意味着开源开发者真能动手玩,而不是只能“云围观”。Meta 甚至专门强调:这个模型是为「开发、黑客、量化、微调、学习」而生的。
社区热议:从兴奋到质疑
我扫了一圈在社交媒体上的讨论声音,发现主要分成三派:
🔥 上限派:
- “1000 万上下文窗口是开源历史性一刻!”
- “Llama 4 Scout 可以开始整真实项目了。”
- “LMSYS 排名第二,性能很能打。”
🤔 质疑派:
- “Behemoth 还没放出来,前两个也不算碾压。”
- “DeepSeek V3 的表现甚至更好?”
- “表现不如预期,是不是有点虎头蛇尾?”
😌 实用主义派:
- “上下文再长,能用得起来的才重要。”
- “Scout 能单卡跑,这就赢麻了。”
- “多模态能用图 prompt 很关键。”
技术参数速览(挑重点)
| 模型 | 活跃参数 | 总参数 | 上下文窗口 | 多模态 | 部署门槛 |
|---|---|---|---|---|---|
| Scout | 17B | 109B | 10M | 图+文输入 | 单卡可跑 |
| Maverick | 17B | 400B | 1M | 图+文输入 | 需 DGX 或多卡 |
| Behemoth(未发) | 288B | ~2T | N/A | 图+文输入 | 须重型集群 |
所有模型均基于 MoE 架构,平均推理时激活 17B 左右参数,有效降低成本。Behemoth 目前仍在训练,但 Meta 称其在 STEM benchmark 上已经超越 GPT-4.5 和 Claude Sonnet。
Meta 的“想清楚了”时刻?
这次 Llama 4 发布除了模型力本身,还有几个额外值得注意的“信号”:
- 答敏感问题更“宽松”: 官方称 Llama 4 在很多敏感话题上不会像以往那么“高冷拒绝回答了”,回应性更强,努力实现“无评判地提供事实”;
- License 有门槛: 欧盟用户被排除在许可之外(怕麻烦?),月活超 7 亿的大公司也要单独申请许可 - 典型“开放但可控”,同比DeepSeek的MIT License还是高下立判;
- 对 DeepSeek 很在意: 传闻Meta内部专门成立“战时指挥室”来专门分析DeepSeek是如何降本增效的,这次Llama 4的发布很可能就是这种开源模式之间也更加“卷”的现状加速催生;
我目前的个人判断
如果你是AI 工具开发者/长文档处理者/多模态应用探索者,Scout 值得马上关注。它可能不是参数最大的,也不是 benchmark 最亮的,但却是开源模型中最可能跑得动、真能用、还能长上下文+图文理解的组合拳。Maverick 更强,但部署成本高;Behemoth 太猛,但还没上线。
未来几周应该会看到不少 Scout 微调+应用层实验,真正用起来后它的表现才会显现。可以等子弹飞一会~
也欢迎在评论区讨论 - 你觉得 Llama 4 是“新一代开源王者”,还是“热闹但性能普通”?