会说话就能出图的新纪元 - GPT-4o彻底革新AI图片生成
2025年3月27日,OpenAI发布了GPT-4o的原生图片生成功能,迅速在海外社交媒体平台掀起热潮。这不仅是一次普通的技术升级,而是对AI图片生成领域的一次革命性冲击。无论是生成结果的质量与易用性,还是背后端到端多模态技术的突破,GPT-4o都展现出了碾压传统模型的潜力,让”会说话就能出图”的梦想触手可及。
我从两个核心维度深入探讨为什么这次的”完全体GPT-4o”堪称AI模型发布里程碑的事件之一:
生成质量与易用性:从”人适应工具”到”工具理解人”
GPT-4o的图片生成功能甫一亮相,便以其惊艳的质量和无与伦比的易用性征服了用户。这标志着AI创作工具从要求”人适应工具”到实现”工具理解人”的关键转折。
真人风格转换的突破
拿我之前用Gemini的P图功能测试过的童年动漫来简单测试,只需通过简单的文字描述就能将白羊座的黄金圣斗士转为真人实拍风格,效果令人惊艳:

更令人惊喜的是,GPT-4o能在这个基础上自动延伸创作,我只需提示它生成4格漫画,立即得到了连贯有趣的故事画面:

多样化风格表现力
我还测试了将自己使用的柠檬头像转换为吉卜力风格的表情包系列,效果同样出色:

提到吉卜力风格并非偶然 - 在GPT-4o发布当天,海外社交媒体上几乎所有测试用户都分享了吉卜力风格的生成作品。用户们晒出GPT-4o创作的梦幻森林、温暖小镇等作品,画风细腻、色彩柔和,完美重现了宫崎骏经典动画的美学风格。
这些高质量成果的生成过程简单到令人难以置信 - 只需用自然语言描述需求,GPT-4o就能立刻产出,无需像使用MidJourney等传统工具那样费力编写复杂的”魔法咒语”。
社交媒体内容的智能创作
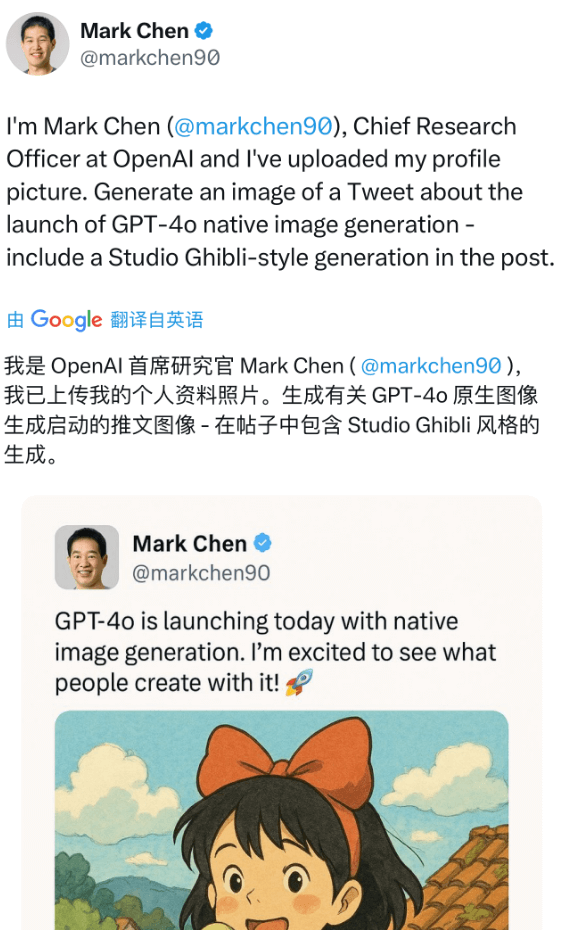
OpenAI首席研究官Mark Chen展示的例子更为精彩。他在X平台上用GPT-4o生成了一张虚拟推文截图,指令简单明了:”生成一张关于GPT-4o原生图片生成发布的推文图片,包含吉卜力工作室风格的生成内容。”
结果不仅完美呈现了吉卜力风格的图像,还精准还原了推文界面的各种细节,令人叹为观止:
更妙的是,他随后要求模型:”生成马斯克对上面这条推文的回应图片。”生成的图像中,Elon的语气和表情微妙地传达出几分不悦,这一幽默细节展现了GPT-4o对社交媒体人物特点和互动语境的深刻理解:

技术突破:首个端到端原生多模态大模型
GPT-4o质量和易用性的飞跃源于其革命性的技术架构——它是首个真正的”端到端原生多模态大模型”。我在2024年5月4o刚刚发布时的分析中曾指出,GPT-4o与以往模型最大的区别在于其统一的多模态处理方式。
不同于传统GPT需要调用独立的语音转文字模型处理语音,或依赖单独的扩散模型(如DALL-E)生成图片,GPT-4o的所有输入和输出都由同一个神经网络处理。这种统一设计带来了多模态任务中无与伦比的流畅性和一致性。
虽然4o的原生语音能力和图片能力”跳票”了太久,导致今天才呈现真正的”完全体”产品,但这次完整功能的发布证明了4o模型的创新价值远超预期。
技术架构的创新突破
这次我们终于能从OpenAI研究员Allan Jabri分享的白板草图中,窥探到这款模型的技术架构设计:

- 统一模态处理方法:GPT-4o尝试用一个大型Transformer模型同时处理文本、图像和声音,就像处理一种”通用语言”一样。这就像是一个人可以同时理解文字、图片和声音,而不需要在不同能力间切换;
- 解决多模态数据差异的挑战:
- 问题:图像和声音的信息密度远高于文本(一张照片包含的信息量可能相当于数千个文字);
- 解决方案:先将”高密度”数据(如图像)压缩成更紧凑的表示形式,就像将一张高清照片先转换成草图一样,保留核心信息但减少处理难度;
- 两阶段生成流程:从草图可以看到,GPT-4o采用了”tokens → [transformer] → [diffusion] → pixels”的处理流程;
- 第一阶段:核心Transformer模型处理压缩后的多模态信息,生成创意构思;
- 第二阶段:专门的”解码器”(类似于扩散模型)将这些构思转化为高质量的最终输出(如精美图像);
这种架构设计带来了显著优势:
- 无需中间转换:传统方法需要”文本模型生成描述 → 传递给图像模型 → 生成图像”的繁琐过程,而GPT-4o直接在同一大脑中完成所有处理;
- 保持上下文连贯:所有模态信息在同一模型中处理,确保了图像生成与对话历史的一致性;
- 更自然的交互体验:用户只需用自然语言表达需求,无需学习特殊提示词语法;
通过这种设计,GPT-4o实现了真正的”会说话就能出图”体验 - 就像与一位既能理解你的语言,又能立即用画笔表达你想法的艺术家对话一样。
应用前景:创意表达的民主化
GPT-4o的图像生成能力将为不同领域带来变革性影响:
我会根据您提供的更详细示例来优化”创意表达的民主化”部分,使其更加具体且贴近实际应用场景:
应用前景:创意表达的民主化
GPT-4o的图像生成能力将为创意产业和普通用户带来前所未有的可能性,彻底改变我们创作和使用视觉内容的方式。
专业创意工作流程重塑
设计师能快速将概念变为视觉草图,加速创意迭代,例如能一次性输出多套方案供需求方评估,将概念验证时间从数天缩短至数分钟;
内容创作者可轻松生成与文本内容匹配的高质量配图,例如各种微信公众号和小红书的配图将再不是问题,即使没有专业设计背景也能保持内容的专业视觉质量;
营销团队能更高效地测试不同视觉创意方案,或者在电商场景中能自动将带中文的物料图片在保持其他元素不变的同时只将文字自动翻译成不同语言,大幅提升国际营销效率;
影视创作者可通过简单对话快速生成分镜脚本和场景概念图,缩短前期构思到视觉呈现的过渡时间,加速项目启动和融资过程;
产品团队能即时将用户反馈转化为产品界面的视觉调整,在客户会议中实时展示修改效果,显著提升沟通效率和客户满意度。
普通用户的创意赋能
社交媒体创作者可以一键生成符合平台审美的高质量视觉内容,无需掌握专业设计软件,大幅提升内容吸引力;
家庭生活应用从家庭相册创意编辑到个性化贺卡设计,从孩子的绘本故事插图到家庭聚会邀请函,普通用户都能轻松创作出专业水准的个性化视觉内容;
教育工作者能根据课程需求即时生成定制化教学插图和视觉辅助材料,使抽象概念具象化,提升学生学习体验和教学效果;
小型企业主无需聘请专业设计师,也能创建专业品质的品牌视觉资产,从logo到社交媒体图片,从产品展示到宣传材料,大幅降低创业成本和门槛;
创意爱好者可以将脑海中的想法立即转化为视觉作品,无论是童话故事插图、个人艺术创作还是家庭游戏素材,都能轻松实现。
结语:AI图片生成的新标杆
GPT-4o的原生图片生成功能,以其惊艳的生成质量、直观的易用性和端到端多模态技术的突破,彻底颠覆了传统AI图片生成模型的格局。从Mark Chen的趣味演示,到海外社媒上刷屏的吉卜力风格作品,都让”会说话就能出图”不再是科幻概念。
正如归藏老师所总结:”从产品思维角度看,这代表了人机交互的本质转变:从’人适应工具’到’工具理解人’。”
确实,过去用户需要学习AI的逻辑,精心调整提示词才能得到理想结果;而现在,GPT-4o通过理解自然语言,直接将用户的想法转化为高质量图像。
这种易用性的飞跃,不仅降低了创意表达的门槛,也让视觉创作变得更加直观和高效,为人类创造力开启了全新可能。
如果你是创意工作者,现在正是探索如何将这一技术融入工作流程的最佳时机;如果你只是对AI创作感兴趣的普通用户,也值得尝试这种前所未有的”说话出图”体验。