(深度技术向)HuggingFace良心出品"超大规模训练攻略" – 让LLM训练不再神秘
为对LLM训练的技术细节方面感兴趣的朋友们强烈推荐这个免费资源:经过6个多月的制作和消耗超过一年的GPU计算时间,HuggingFace发布了“Ultra-Scale Playbook”(超大规模训练攻略)—— 一本免费、开源的书籍,为大模型训练技术揭秘。
HuggingFace的LLM训练三部曲
这本《超大规模训练攻略》是HuggingFace正在推出的LLM训练三部曲系列中的第二部分,旨在为开源社区提供全面的大模型训练知识:
- 第一部分:FineWeb - 高质量预训练数据集的创建(已发布)
- 第二部分:Ultra-Scale Playbook - 分布式训练技术详解(本文重点)
- 第三部分:数据混合和架构选择(即将推出)
Ultra-Scale Playbook:核心内容与价值
这本书在讲什么
正如作者所说:
“我们的目标是将所有使当今大语言模型扩展成为可能的技术集中在一起,用连贯且易懂的方式讲述其中的来龙去脉。”
这本书从基础开始,引导读者了解如何将大型语言模型的训练从一个GPU扩展到数十个、数百个甚至数千个GPU,并通过实用的代码示例和可重现的基准测试来说明理论。书中详细介绍了随着用于训练这些模型的集群规模增长而发明的各种技术,如数据并行、张量并行、流水线并行或上下文并行,以及ZeRO或核心融合等技术,确保GPU始终保持高利用率。
三大关键挑战
本书讨论的所有技术都致力于解决以下三个核心挑战:
- 内存使用:这是一个硬性限制 - 如果训练步骤无法装入内存,训练就无法进行;
- 计算效率:我们希望硬件大部分时间用于计算,需要减少数据传输时间或等待其他GPU工作的时间;
- 通信开销:我们希望最小化通信开销,因为它会导致GPU空闲。为实现这一点,我们将尽可能充分利用节点内(快速)和节点间(较慢)带宽,并尽可能使通信与计算重叠;
在很多情况下,我们可以在这三者(计算、通信、内存)之间权衡(例如重计算或张量并行)。找到合适的平衡点是扩展训练的关键。
适合谁阅读?
本书假设读者对当前的LLM架构有一些基本了解,并且大致熟悉深度学习模型的训练方式,但对分布式训练可以是新手。如果你对大模型训练的实战部分感兴趣,这本书将是非常宝贵的参考。
为什么值得读?
- 内容丰富且深入:这个项目最初只是想写成一篇简单的博客文章,却逐渐发展成为一个包含3万多字的交互式作品,现在甚至被制作成了100页的实体书 – 或者换个角度来看,官方提供的PDF版本如果打印出来有足足36米长!
- 基于大量实验数据:书中不仅介绍了所有扩展瓶颈和工具的动机与理论,还附上了来自4000多个扩展实验的可交互数据可视化,并有NotebookLM播客主持人为读者全程讲解;
- 解答关键问题:如果你想了解以下问题的答案,这本书将是绝佳资源:
- DeepSeek是如何仅花费500万美元就完成训练的?
- 为什么Mistral选择训练MoE模型?
- 为什么PyTorch原生的数据并行实现在底层如此复杂?
- 都有哪些并行技术,它们各自又是因何而生?
- 在扩展时应该选择ZeRO-3还是流水线并行?这两种技术背后有什么渊源?
- Meta用于训练Llama 3的上下文并行是什么?它与序列并行有何区别?
- 什么是FP8?与BF16相比有何优劣?
实用工具:Ultra-Playbook Cheatsheet
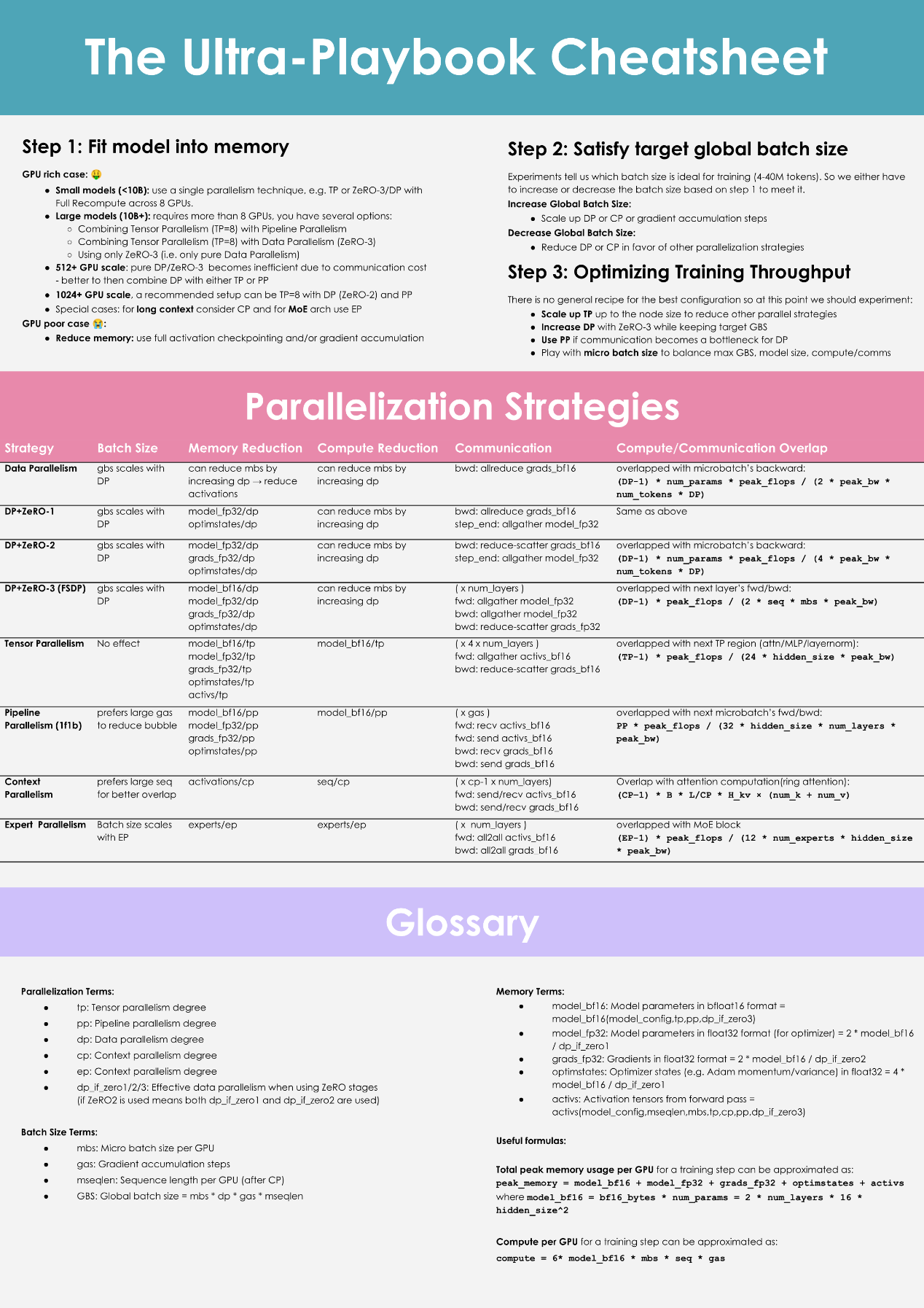
以原文中这张cheatsheet为例,其中归纳了大模型分布式训练的关键步骤和策略:
第1步:让模型装入内存
- 根据模型大小选择合适的并行技术;
- 对于小型模型(<10B):单一并行技术即可;
- 对于大型模型(>10B):结合张量并行、流水线并行和ZeRO等技术;
- 针对不同GPU配置的特殊解决方案;
第2步:满足目标全局批量大小
- 实验表明理想训练批量大小为4-40M tokens;
- 增加或减少批量大小的策略;
第3步:优化训练吞吐量
- 没有通用配方,需要实验;
- 可扩展TP以减少其他并行策略;
- 使用ZeRO-3同时保持较大全局批量的情况下增加DP;
- 在通信成为瓶颈时使用PP;
- 使用微批量大小平衡最大全局批量、模型大小和计算/通信;
cheatsheet还详细列出了各种并行化策略(数据并行、张量并行、流水线并行、上下文并行等)的批量大小影响、内存减少方式、计算减少方式、通信方式以及计算/通信重叠策略,并提供了一个术语表方便查询。
回顾第一部分:FineWeb高质量数据集
值得一提的是,训练三部曲的第一部分这篇关于FineWeb的博客文章,主要讲述如何创建高质量的预训练数据集 - 这是从头开始训练大模型时的第一个必经步骤。
FineWeb数据集的特点:
- 15万亿个标记(tokens)
- 占用44TB磁盘空间
- 源自96个CommonCrawl快照
FineWeb的关键价值:
- 经实验证明可以生成比其他开源预训练数据集性能更好的LLM;
- 详细记录和验证了所有设计选择;
- 深入研究了去重和过滤策略;
这一工作的重要性在于:Llama 3和Mixtral等顶级开源模型的预训练数据集并未公开,且关于其创建方式的信息极少,因此FineWeb为社区提供了一个透明且高效的替代方案。
HuggingFace推出这个系列文章的愿景
HuggingFace强调:”让AI更加普及的最关键因素,永远是教会每个人如何开发AI,特别是如何创建、训练和微调高性能模型。换言之,让每个人都能掌握支持近期大语言模型的各种技术,其中高效训练可能是最重要的一环。”
阅读这两篇博客后,你将拥有几乎所有核心知识,完全理解当今高性能LLM的构建方式,只缺少关于数据混合和架构选择的最后一些细节,而这将在即将推出的第三部分中介绍。
原文阅读链接(推荐用电脑访问):