终于!AI语音不再"像AI":Sesame的语音存在感突破
当我们与人交谈时,真正的理解不仅仅体现在词语上,更体现在声音的微妙之处:语调的起伏、有意义的停顿、语速的变化。这些细微差别共同构成了我们最亲密的交流媒介。而当前的AI语音助手,无论多么先进,都缺乏这种真实的”语音存在感”。
走出AI语音的”恐怖谷”
“恐怖谷”(Uncanny Valley)是机器人学和AI领域的一个著名现象,最初由日本机器人学家森政弘在1970年提出。这一理论指出,当机器人或虚拟形象接近人类但又不完全像人类时,人们会产生强烈的不适感。
在语音领域,这一效应同样存在:当AI合成语音接近真人但仍有微小瑕疵时,反而让人觉得怪异,不如明显的”合成”的声音那样让人接受。我们多数人都体验过这种感觉 - 当前的高级语音助手听起来已经很”像人”了,但那种平板的情感、缺乏语境适应的回应和机械的节奏,常常让长时间交流变得疲惫和不自然。这就是语音交互的”恐怖谷”,一个看似接近人类但又让人感到不适的区域。
Sesame团队在最近发布的研究《Crossing the uncanny valley of conversational voice》中,正尝试跨越这一根本挑战。我体验了他们的语音助手演示,无论是Maya还是Miles,都给我留下了深刻印象,特别是相比目前市面上的ChatGPT或者豆包的实时语音模式,Sesame的语音助手听起来真实了许多 - 他们似乎已经开始成功地跨越这道”恐怖谷”。
语音存在感的魔力
Sesame团队强调了”语音存在感”(Voice Presence)的概念,作为跨越恐怖谷的关键。这是使口语交互感觉真实、被理解和被重视的魔力品质。他们不只是在创建处理请求的工具,而是在打造能够进行真正对话的伙伴,随着时间推移建立信任和信心。
语音存在感由四个关键部分组成:
- 情绪智能:能够读取和回应情感语境;
- 对话动态:自然的时机、停顿、打断和强调;
- 语境感知:根据情境调整语调和风格;
- 一致的个性:保持连贯、可靠和适当的存在感;
技术深度解析:会话语音模型(CSM)
传统文本转语音(TTS)模型直接从文本生成语音输出,但缺乏自然对话所需的上下文感知能力。即使最先进的模型生成的语音听起来像人类,它们仍然面临”一对多”问题:
一句话有无数种有效的说法方式,但只有少数适合特定场景。
Sesame团队的创新在于引入了会话语音模型(Conversational Speech Model, CSM)这一概念,将问题框架化为端到端的多模态学习任务。这个模型的设计核心是模仿人类对话的自然流畅性,让AI能像真人一样实时交流,而不是那种机械的”你问我答”。CSM利用对话历史来生成更自然、更连贯的语音,能深度理解和生成对话中的上下文,确保AI的回应始终连贯且有逻辑。
为了训练这个强大的模型,Sesame使用了约100万小时的公开音频数据,涵盖了多语言、多口音和各种情感表达。这让模型学会了丰富的语音模式和情感线索,输出时自然度和真实感直接拉满。
为了更好支持实现实时对话,Sesame优化了模型架构,采用了流式处理技术和端到端设计。传统的语音模型往往需要多个中间步骤,而CSM直接从输入到输出,减少了处理时间。再加上高效的计算摊销方案(音频解码器只在音频帧的随机1/16子集上训练,而第零级码本在每一帧上训练),哪怕在云端处理海量数据,延迟也能控制在毫秒级,用户几乎感觉不到卡顿。
Sesame团队训练了三种不同规模的模型:
- Tiny:1B骨干,100M解码器;
- Small:3B骨干,250M解码器;
- Medium:8B骨干,300M解码器;
这种相对较小的模型规模对于希望集成自然AI对话能力的硬件产品来说是个巨大利好。
突破性的评估结果
传统基准测试如词错误率(WER)和说话者相似度(SIM)已经体现不出差异了,现代的主流语音生成模型,包括CSM,在这些指标上都达到了接近人类的表现。
为了更好地评估发音和上下文理解能力,Sesame团队引入了一套基于语音转录的新基准测试:
- 通过同形异义词消歧的文本理解:评估模型是否正确发音具有相同拼写的不同单词(例如,作为”金属”的”lead”/lɛd/与作为”引导”的”lead”/liːd/);
- 通过发音延续一致性的音频理解:评估模型是否在多轮对话中保持特定单词的发音一致性;
从下图的测试结果可以看到,Sesame的模型在这两项测试上甚至超过了目前被认为最领先的OpenAI和ElevenLabs这两家。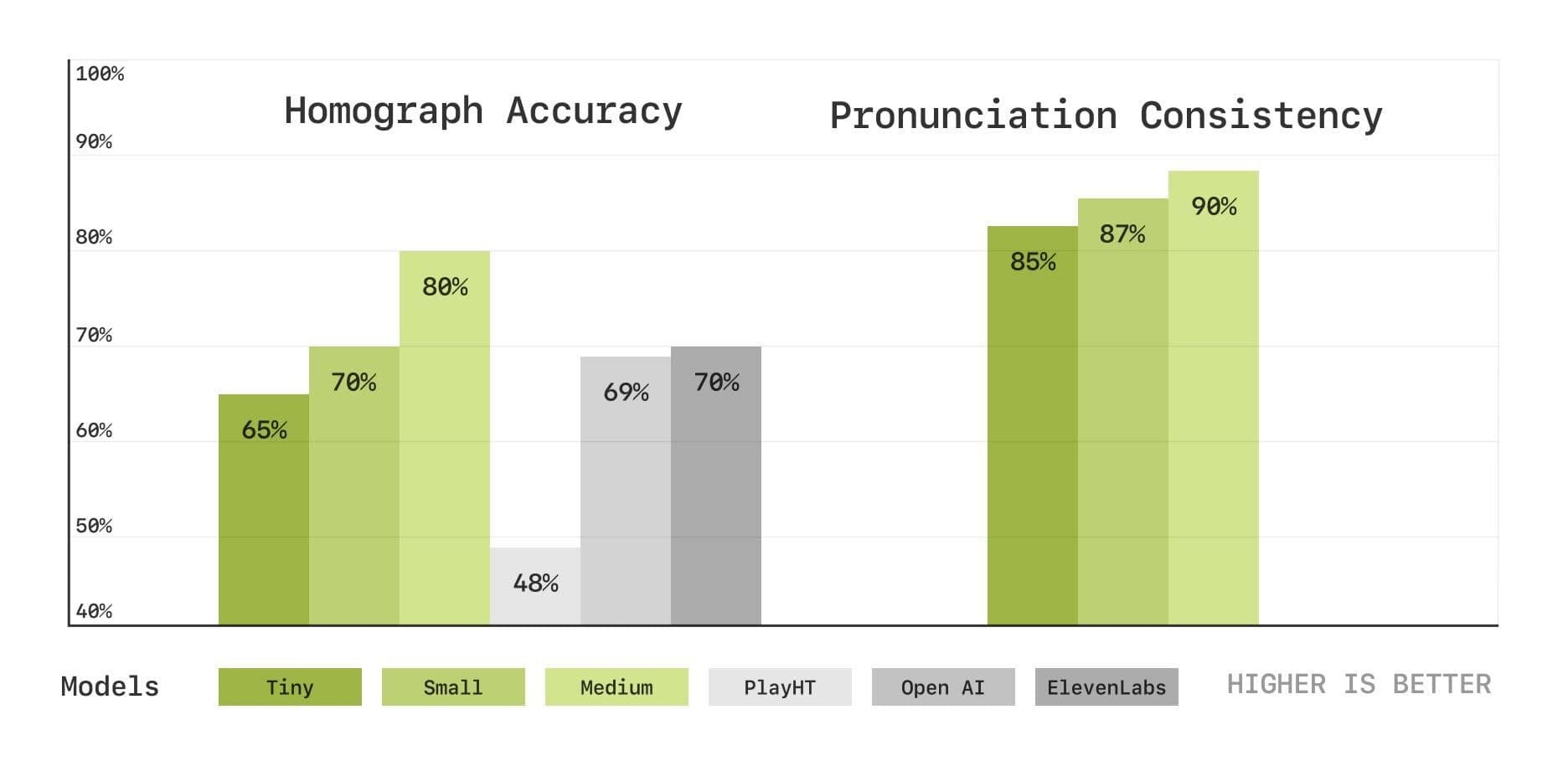
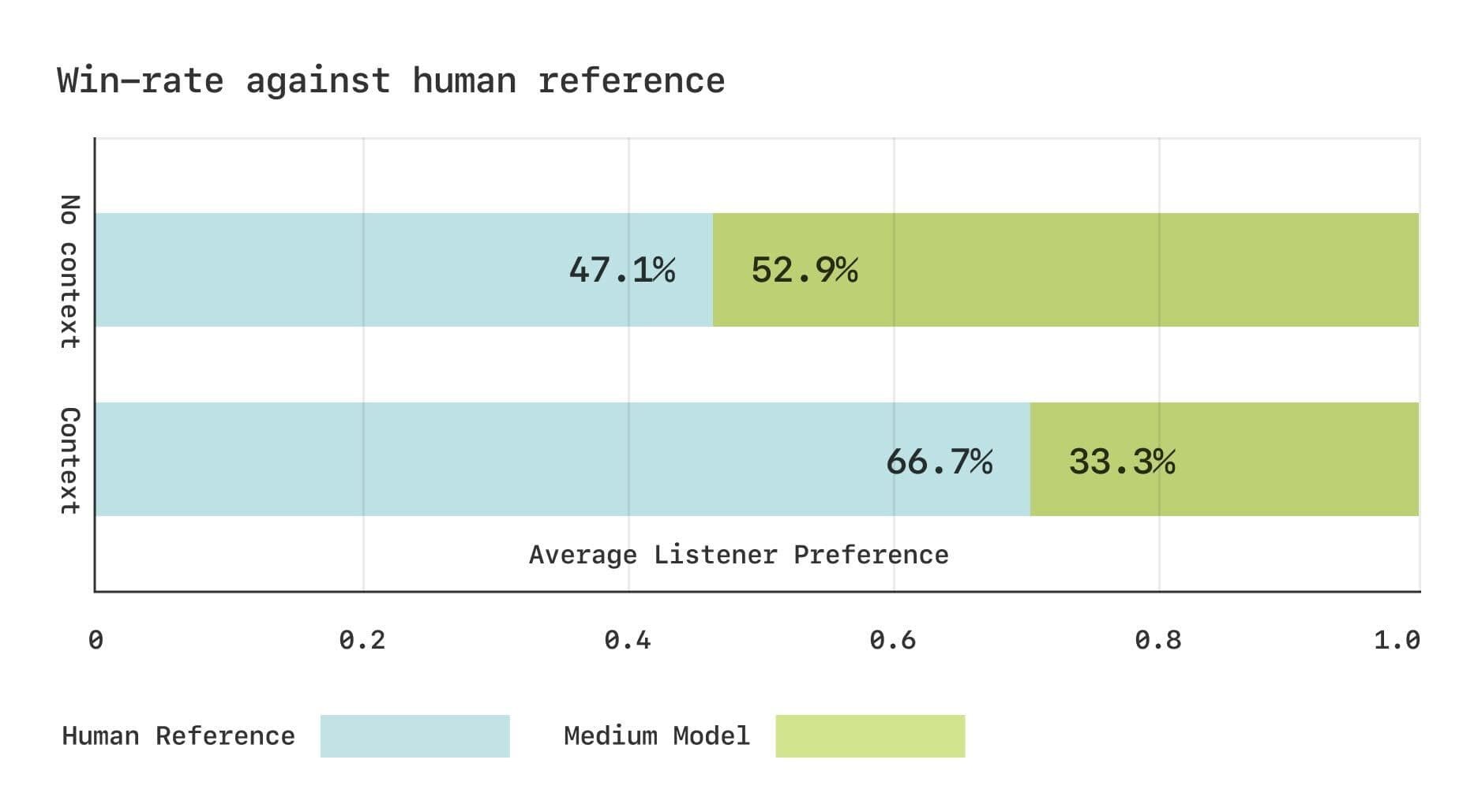
主观评估方面,他们进行了两项比较平均意见分数(CMOS)研究,使用Expresso数据集来评估生成语音的自然度和韵律适当性。在没有上下文的情况下,人类评估者对生成的和真实的语音没有明显偏好,表明自然度已饱和。但当包含上下文时,评估者仍然一致倾向于原始录音,这表明在会话语音生成方面,AI还有显著提升空间。
Maya和Miles:我要打十个!
再来看看这个视频里中的例子 – Sesame的语音助手Maya被要求引导用户冥想,结果让我相当震撼 - 它瞬间切换到柔和舒缓的语气,节奏拿捏得恰到好处,完全符合冥想引导的需求。冥想语音其实很有挑战性,既要平和又要连贯,还要通过语气让人放松。Maya不仅做到了,还通过细微的呼吸停顿和语调变化,增强了真实感。这种快速适应语境的能力,真的体现了Sesame模型的情境感知和情感表达有多强。
同样,如果是解释技术概念时,Miles能展现出清晰、自信的语调,同时能够根据问题的复杂性调整讲解的细节程度和语速。你能感觉到他不是在机械地朗读文本,而是真的在与你交流,理解你的问题,并希望你能理解他的回答。这种微妙的互动感是当前市场上其他语音助手所缺乏的。
每次我使用豆包或者通义的语音模式时,总能感觉到那种”AI感”——虽然发音清晰流畅,但总觉得有点平,缺少真人对话中的那种”灵魂”。而Sesame的演示让我看到了不同的可能性。
硬件野心与开源计划
Sesame的野心不止于软件。在最近社交媒体发帖中,Sesame提到:”我们生活中可以减少屏幕的使用。我们正在开发舒适的、可全天佩戴的眼镜,为个人伴侣提供最自然的方式来看、听和回应。做好这件事很难,但我们已经取得了坚实的进展。”
这一硬件战略与他们的语音技术完美契合。想象一下,当你戴着一副轻便的眼镜,能够与一个拥有真实语音存在感的AI助手自然交流,而不需要盯着手机屏幕。这种交互方式将远比当前的语音助手更加自然和无缝。而Sesame模型相对较小的规模(最小的Tiny模型只有1B+100M参数)也为这种硬件集成提供了可能性。
同时,Sesame团队相信推进会话AI应该是一项协作努力。他们承诺开源研究的关键组件,使社区能够实验、构建和改进他们的方法。他们的模型将在Apache 2.0许可下提供。
当前的CSM主要在英语数据上训练,虽然由于数据集混合,出现了一些多语言能力,但表现还不够理想。在未来几个月,Sesame计划扩大模型规模,增加数据集量,并将语言支持扩展到20多种语言。他们还计划探索利用预训练语言模型的方法,朝着对语音和文本都有深入了解的大型多模态模型方向发展。
更令人兴奋的是,Sesame团队认为AI对话的未来在于全双工模型,这些模型可以从数据中隐式学习人类对话的复杂动态,包括轮流发言、停顿和节奏等。这将需要从数据策划到后训练方法的整个技术栈的根本变化。
语音交互的未来:跨越恐怖谷
语音是人类最自然的交流方式,也应该是我们与AI交互的最自然界面。Sesame的工作向我们展示了,当AI真正掌握了语音的微妙之处时,我们或许终于可以跨越那道长期困扰人机交互的”恐怖谷”,迎来真正自然、流畅的对话体验。