AI代码能力的市场化检验:OpenAI用真金白银考验大模型
“在软件工程领域,AI的真实价值究竟几何?OpenAI用100万美元的真实项目给出了答案。”
在评估AI编程能力时,我们一直面临着一个问题:那些学术基准真的能反映现实世界中的软件工程工作吗?
今天OpenAI发布了一个新基准测试SWE-Lancer,用一种前所未有的方式评估AI的编程能力 - 直接用真实的自由职业者软件项目来考验AI。整个测试数据集包含了近1500个来自Upwork(这是一家线上接活的平台)的软件工程项目,总价值100万美元!
这个测试为什么与众不同?
SWE-Lancer最大的创新在于它首次用”赚钱能力”来衡量AI的表现。在这个基准中,一个项目能拿到32,000美元和200美元的差异,完全取决于真实市场的估值,而不是人为设定的难度等级。
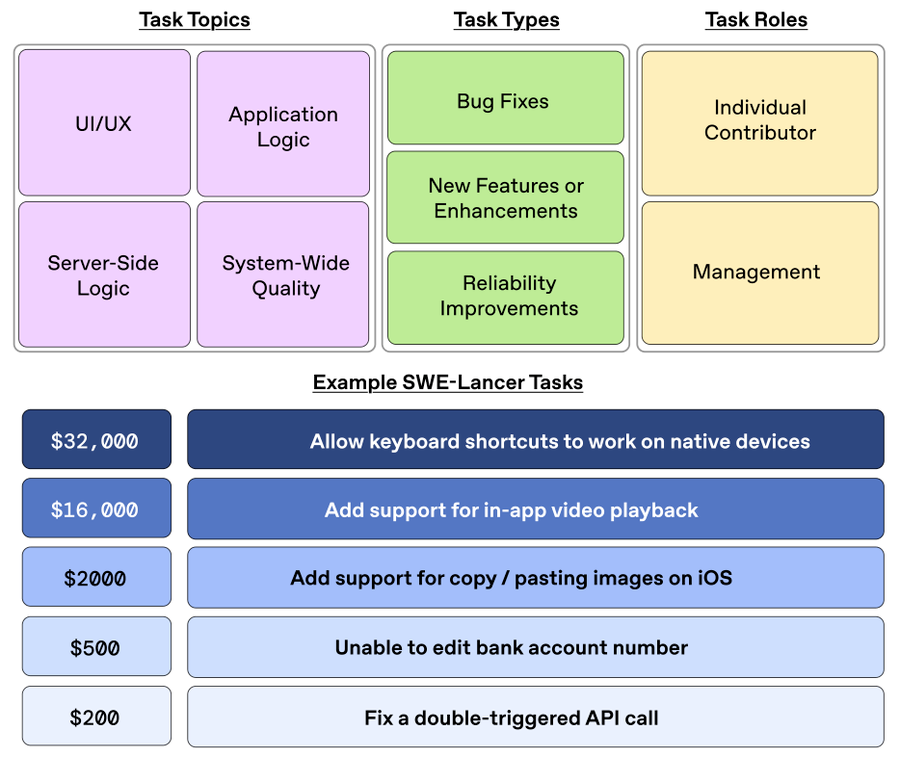
更有趣的是,这些项目的复杂度相当真实 - 平均来说每个项目在GitHub上需要26天才能解决,并产生47条讨论留言。这种复杂度远超传统的编程测试。
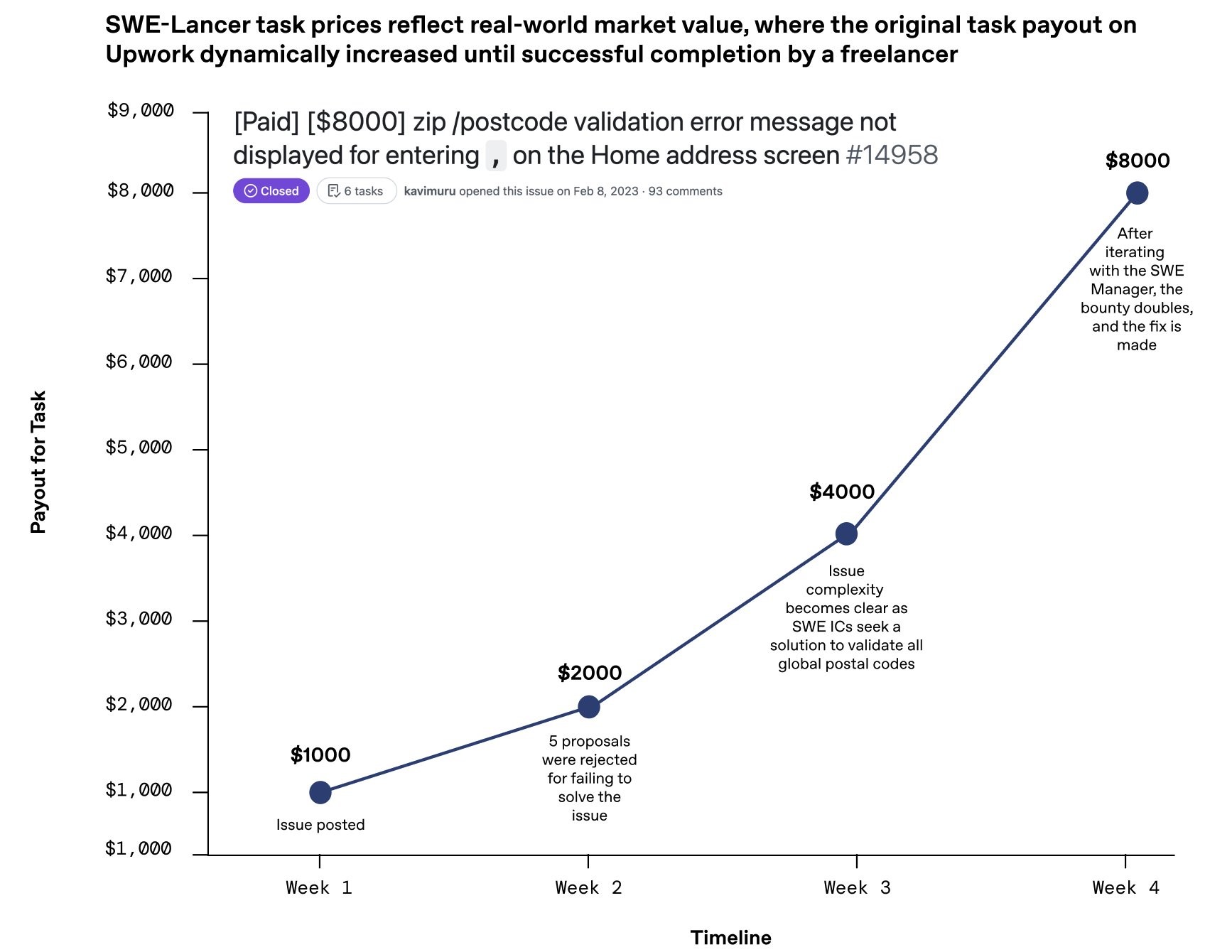
以其中一个价值8,000美元的邮编验证项目为例:最初报价仅1,000美元,但由于需要处理全球各种不同格式的邮政编码,以及考虑某些国家根本没有邮编的情况,项目价格在四周内一路攀升到8,000美元。这个过程完美展示了真实软件工程中的复杂性。
惊人的结果
在这场价值100万美元的”接单大战”中,最让人意外的是Claude 3.5 Sonnet的表现。它在整个数据集上”赚到”了超过40万美元,甚至超过了OpenAI自家的o1这样的顶级推理模型。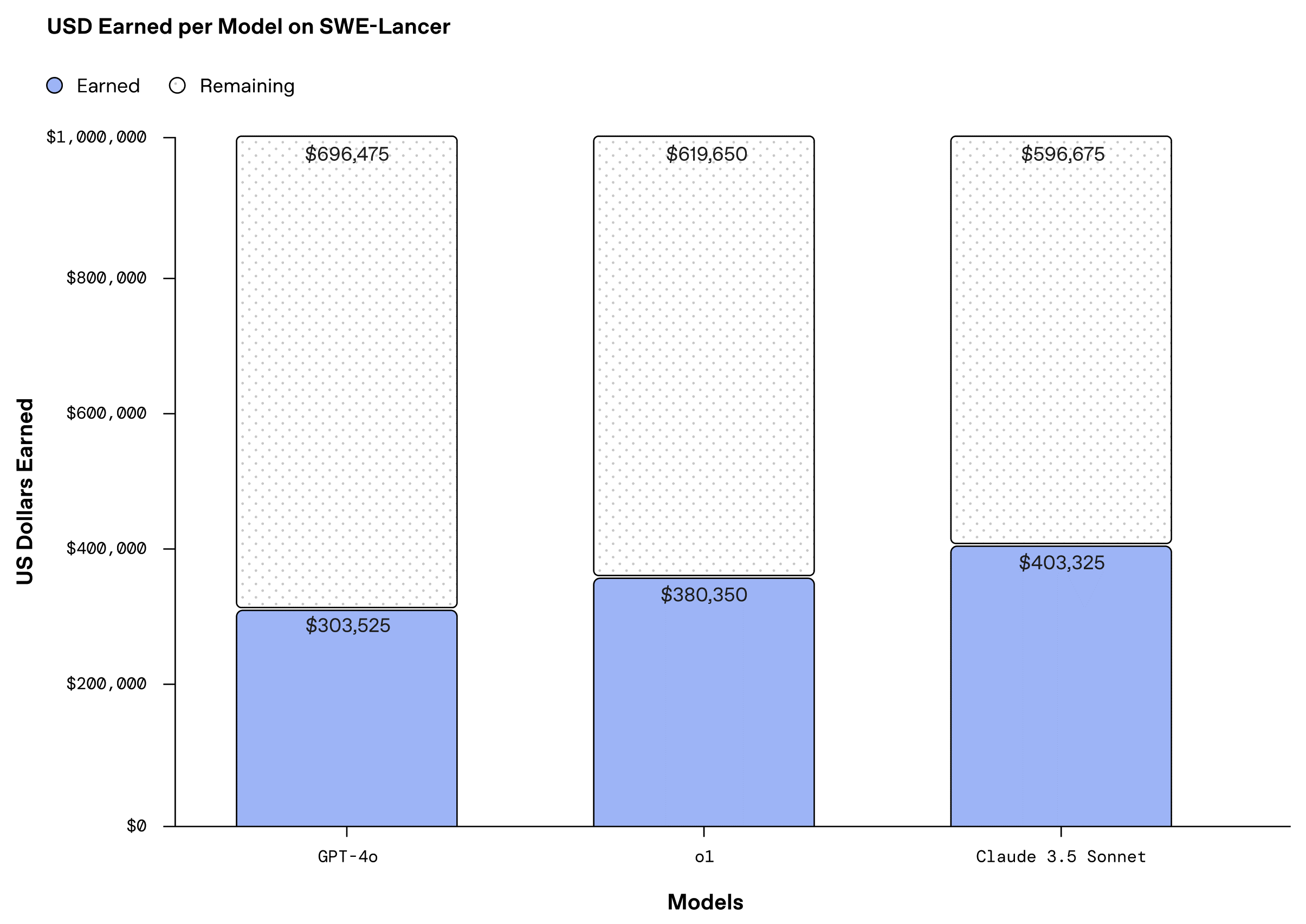
具体到不同类型任务上的表现上:
- 在UI/UX任务上,Sonnet比o1高出近15%的成功率;
- 在新功能开发上,Sonnet领先o1约10%;
- 在技术管理决策上,所有模型的表现都比编码任务好得多。例如Claude 3.5 Sonnet在技术管理决策任务上达到了44.9%的成功率,而在实际编码任务上则只有26.2%…
结语和启示
这个基准测试的结果给商业世界带来了深远启示:
- 价值创造的重新定义:虽然总体上AI只完成了约40%的任务,但一个AI系统能独立完成价值40万美元的工程任务,这个数字已经超过了许多程序员的年薪;
- 领域特长的浮现:数据显示AI在某些领域确实表现突出,除了上面提到的技术管理决策任务外:
- 在服务器端逻辑任务上,Claude 3.5 Sonnet取得了41.2%的完成率;
- 在UI/UX开发上达到了31.7%的完成率;
- 而在系统级质量和可靠性任务上则完全失败;
- 人才市场的转型:也许未来的程序员可能更像是”AI管理者”?这种人机协作模式应该是未来的主流~
正如任何新技术一样,理解它的真实能力和局限性,远比人云亦云更重要。而要评估AI的真实能力,必须回归到它能为现实世界创造多少实际价值。从这个角度看,SWE-Lancer是一个重要的里程碑 - 它让我们第一次用真实的市场价值来检验AI的实力 - 真金白银才是最好的试金石。
延伸思考:如果软件开发真的进入”AI+人工”的混合时代,那么程序员的培训体系和职业发展路径是否也需要重新设计?