论文导读 - 通用智能的胜利:RL is all you need!
🔥又到了刷论文比刷短剧爽的AI论文导读专题了,我会尝试尽量用普通人也能理解的方式来讲一些最新的AI领域论文~

这次要讲的这篇来自OpenAI的最新论文非常有趣,尤其是将其结合之前DeepSeek R1的技术论文中提到的对强化学习(RL)的使用部分一起来看的时候,你会明显地觉得RL的里程碑时刻真的要来了(而且也从另一个角度再次说明了DeepSeek团队独立发现了如何训练推理模型的配方),这意味着大模型们真的能更快更高效地自我进化了 我们将更快看到更强大的新模型出现。
论文名为Competitive Programming with Large Reasoning Models,核心思想可以一句话总结为:
在竞赛编程这个高度专业化的领域,所有精心设计的人类知识最终都败给了纯粹的强化学习。
如果用故事的方式来讲述论文中的研究,这个故事的开始其实很普通 – 传统大模型在竞赛编程上表现平平,在CodeForces上只能达到11百分位的水平。
真正的突破始于OpenAI通过强化学习训练出o1(全球首款推理模型)。通过训练模型进行有效的思维链推理,性能一下子跳到了89百分位。这个提升已经很疯狂了,充分显示了推理模型的潜力。
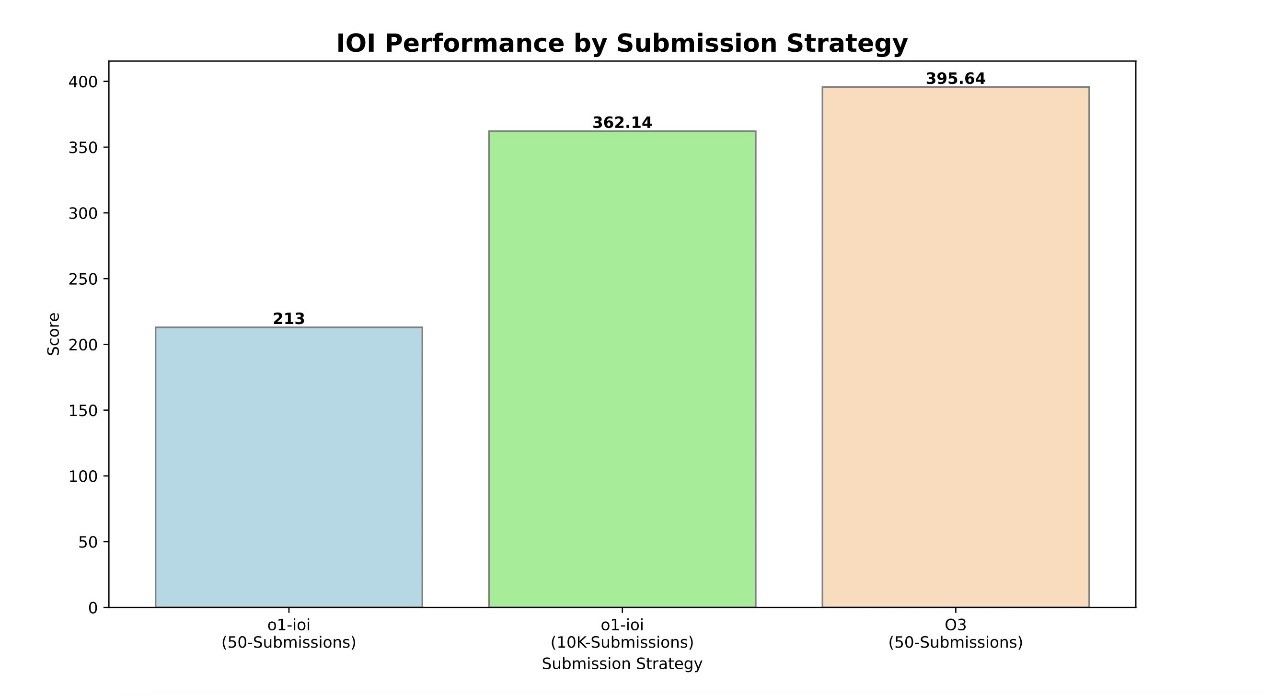
然后,研究团队使出了所有能想到的招数来针对性提升性能:精细的微调、基于测试用例的过滤、提示模型生成额外的测试用例、对解决方案进行相似度聚类、对聚类进行排序… 按照这些思路构建的o1-ioi - 一个专用竞赛系统,在国际信息学奥林匹克竞赛(IOI) 2024上,这个系统表现不错,获得了49百分位,放宽提交限制后甚至能拿到金牌,在CodeForces上也达到了98百分位的好成绩。
但这个”胜利”很快就被o3无情地粉碎了…
o3在完全抛弃了所有这些精心设计的策略后,直接取得了令人震惊结果– 不仅在标准限制下就拿到了IOI金牌,在CodeForces上更是达到了99.8百分位,相当于全球前175名的水平,这在之前被认为是不可能的。
最关键的是,这都是在没有任何定制优化手段的情况下,用通用智能实现的。
而且,当研究人员检查o3的思维链时,发现它自己发展出了测试策略,这恰恰是顶尖程序员常用的技巧 - 比如先写一个简单的暴力解法,然后用它来验证优化后的方案 - 这些复杂的推理能力完全是在通用训练中自然涌现的,没有任何人为设计和干预。
这也让我想起了一篇在大模型历史上可能是最出名的论文《Attention is All You Need》,我很想说这次的这篇论文完全可以叫《RL is All You Need》- 因为它展示了仅仅通过强化学习训练出的通用推理能力,就能超越所有精心设计的特制系统。
由于竞赛编程只是编程的一个方面,研究团队还在两个真实世界的软件工程基准测试上进行了实验:HackerRank Astra和SWE-bench Verified,结果通用推理模型同样表现出色。
- HackerRank Astra是一个包含65个项目导向的编程挑战的数据集。这不是那种算法题,而是真实的软件开发任务,涉及React.js、Django和Node.js等框架。而且这些任务没有现成的测试用例,所以模型不能依赖特制的测试策略。结果:从GPT-4o的pass@1约50.91% -> o1-preview提升到60.89% -> o1达到63.92%;
- SWE-bench Verified这个基准测试则是OpenAI专门设计来评估AI解决真实GitHub问题的能力。结果:GPT-4o: 33.2% -> o1-preview: 41.3% -> o1: 48.9% -> o3: 71.7%
这个”苦涩教训”其实并不新鲜 - 在计算机视觉领域,手工设计的特征最终败给了简单的端到端学习。在围棋领域,所有的人类启发式规则都比不上用“左右互搏”来强化学习训练的AlphaGo。现在,在竞赛编程领域,历史再次重演。
这些数字和代码是最好的证据,也许我们应该把重点放在提升模型的通用学习能力上,而不是不断开发特制功能。当模型具备足够强大的学习能力时,它能够自主发展出超越人类设计的解决方案。 如果这个方向是对的,我们可能很快就会看到更多令人惊叹的突破。
《Competitive Programming with Large Reasoning Models》的论文原文中的摘要部分翻译:
我们的研究表明,将强化学习应用于大语言模型(LLMs)能显著提升其在复杂编程和推理任务上的表现。此外,我们比较了两个通用推理模型——OpenAI o1和o3的早期checkpoint,以及一个领域特定系统o1-ioi。o1-ioi使用专门为参加2024年国际信息学奥林匹克竞赛(IOI)设计的手工设计的推理策略。我们使用o1-ioi在2024年IOI现场比赛中,采用手工设计的测试策略,位列第49百分位。在放宽竞赛条件的情况下,o1-ioi获得了金牌。然而,在评估较新的模型(如o3)时,我们发现o3无需手工设计的领域特定策略或放宽条件就能获得金牌。我们的研究发现,尽管像o1-ioi这样的专门化流程能带来显著改进,但经过扩展的通用模型o3无需依赖手工设计的推理策略就能超越这些结果。值得注意的是,o3在2024年国际信息学奥林匹克竞赛中获得金牌,并在Codeforces平台上获得了与顶尖人类选手相当的评分。总的来说,这些结果表明,在推理领域(如竞争性编程)中,扩展通用强化学习而非依赖领域特定技术,是使人工智能达到领先水平的可靠途径。