DeepSeek-R1 图解版
译者注:将来自Jay Alammar的这篇《DeepSeek-R1 图解》做了全文翻译,属于技术向的内容了,如果想看相对门槛较低的“说人话”总结版本可以参考我写过的这篇 - DeepSeek-R1的创新到底在哪儿? - 重新定义AI推理能力的培养之道
DeepSeek-R1 图解版
一个推理型 LLM 的训练方法
DeepSeek-R1 是 AI 发展进程中最新的重要突破。对机器学习研发社区而言,这是一个具有重大意义的发布:
- 这是一个开放权重模型,并提供更小的蒸馏版本;
- 它分享并深入探讨了一种训练方法,用于复现类似 OpenAI O1 的推理模型;
在这篇文章中,我们将用图形化的方式来详细介绍R1是如何被构建的。
目录:
- 回顾:大语言模型的训练方法
- DeepSeek-R1 的训练配方
- 长链推理监督微调(SFT)数据;
- 临时高质量推理大语言模型(非推理任务表现较弱);
- 使用大规模强化学习(RL)创建推理模型:
- 大规模面向推理的强化学习(R1-Zero);
- 使用中间推理模型创建 SFT 推理数据;
- 通用 RL 训练阶段;
- 模型架构
LLM 训练回顾
和大多数现有的大语言模型一样,DeepSeek-R1采用逐个生成token的方式进行输出,但它在解决数学和推理问题方面表现尤为出色,这是因为它能够通过生成用于解释其思考链路的思考过程标记,从而投入更多时间来深入处理问题。

下图展示了通过三个步骤创建高质量 LLM 的通用方法: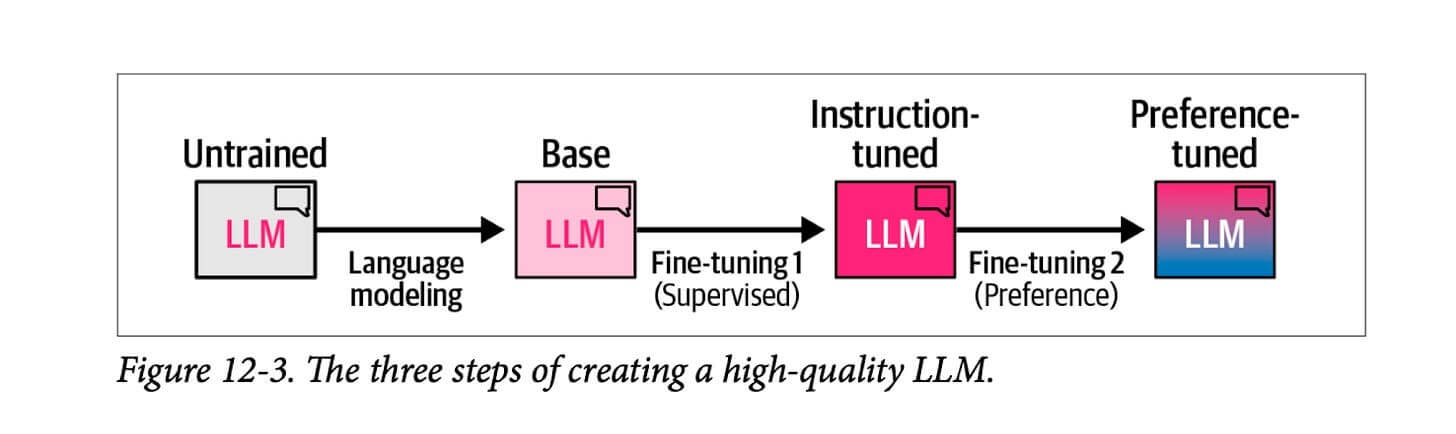
- 语言模型训练阶段,我们使用海量的网络数据训练模型来预测下一个词。这一阶段形成一个基础模型;
- 监督微调阶段,使模型在遵循指令和回答问题方面变得更加高效。这一阶段形成一个指令调优模型或监督微调(SFT)模型;
- 最后是人类反馈优化阶段,进一步优化其表现并使其与人类偏好相协调,最终形成你在互动平台和应用程序中使用的经过偏好优化的大语言模型;
DeepSeek-R1 的训练配方
DeepSeek-R1也遵循了上面这个通用方法。第一步的具体细节来自之前发布的DeepSeek-V3模型论文。R1使用了之前论文中的基础模型(而不是最终的DeepSeek-V3模型),并仍然经过了SFT和偏好调优的步骤,但其实现方式有所不同。

在R1的创建过程中有三个特别值得强调的地方:
1- 基于长链推理的SFT训练数据
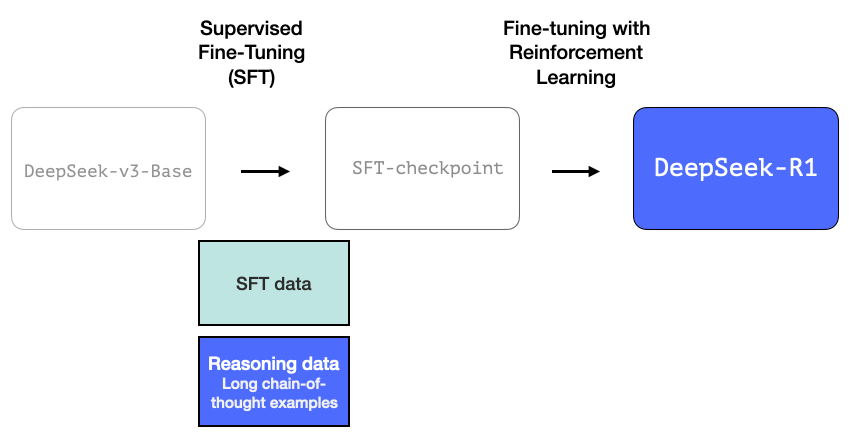
这包含了大量的长链思维推理示例(600,000个)。在如此大规模下获取这类数据十分困难,且人工标注的成本极其高昂。正因如此,创建这些数据的过程成为了第二个值得强调的特点。
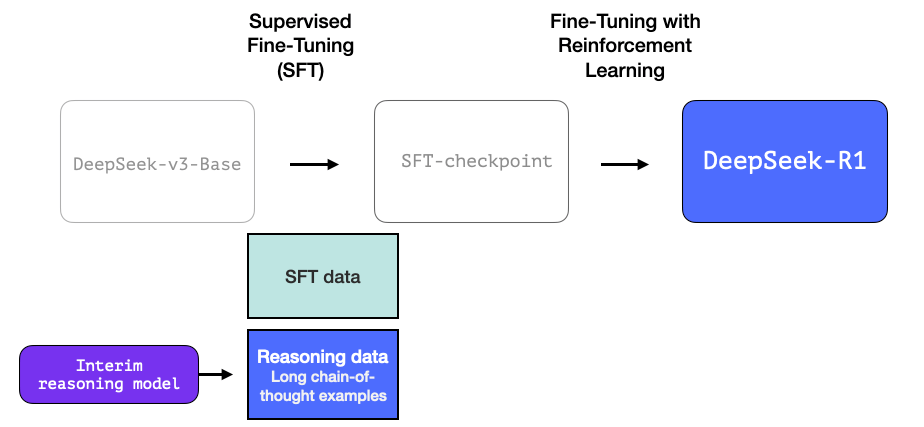
2-一个中间阶段的高质量推理大语言模型(但在非推理任务上表现较差)
这些数据是由R1的前身,一个专注于推理的未命名模型创建的。这个模型的灵感来自于一个称为R1-Zero的第三个模型(我们稍后会讨论)。它之所以重要,不是因为它是一个很好的可用大语言模型,而是因为创建它只需要很少的标记数据,再配合大规模强化学习训练,就能得到一个在推理问题上表现出色的模型。
这个未命名的专业推理模型的输出随后可以用来训练一个更通用的模型,使其不仅能完成其他非推理任务,还能达到用户对大语言模型所期望的水平。
3- 使用大规模强化学习(RL)创建推理模型
这个过程分为两个步骤: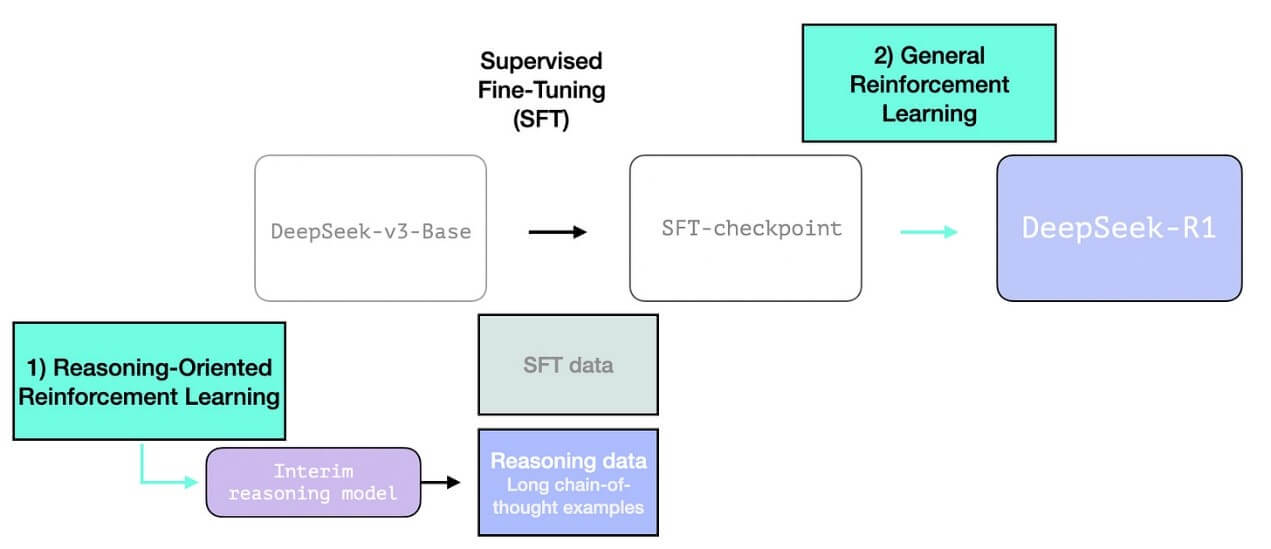
3.1 大规模面向推理的强化学习(R1-Zero)
这里使用RL来创建中间推理模型。该模型随后被用于生成SFT推理示例。但使这个模型成为可能的是一个早期实验,即创建了一个名为DeepSeek-R1-Zero的早期模型。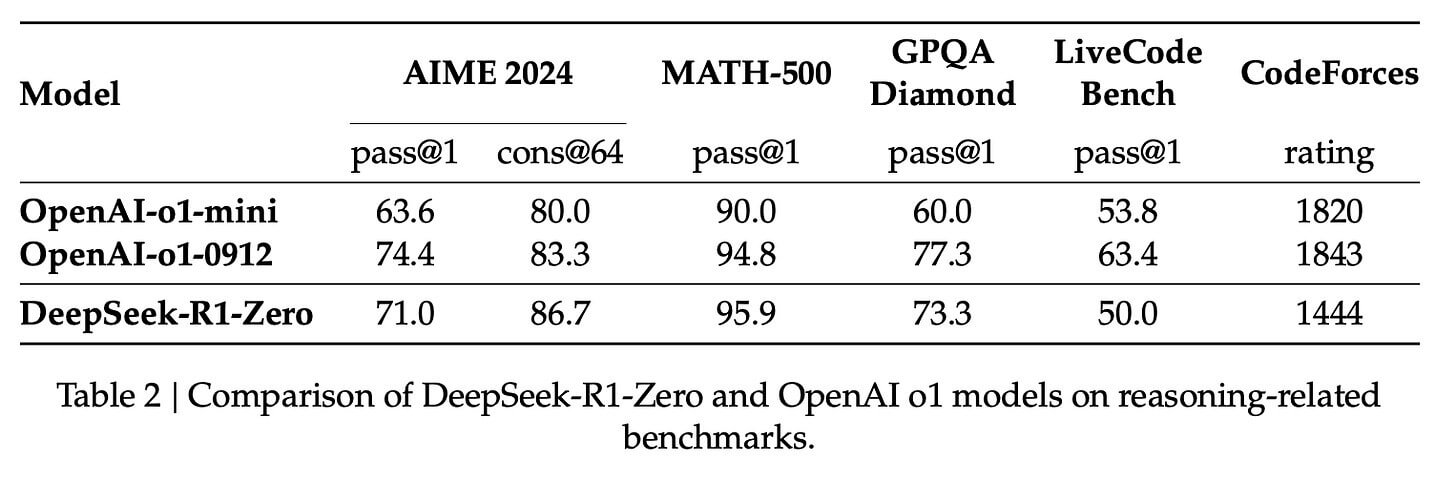
R1-Zero的特别之处在于它无需标记的SFT训练集就能在推理任务上表现出色。它的训练直接从预训练基础模型通过RL训练过程进行(没有SFT步骤)。它做得如此出色,以至于可以与o1竞争。
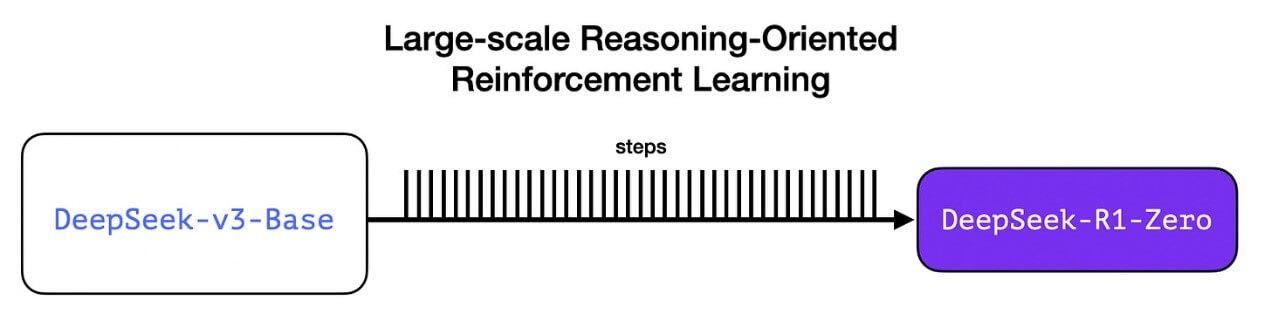
这很重要,因为数据一直是机器学习模型能力的燃料。这个模型如何能够偏离这一历史?这指向两点:
1- 现代基础模型已经跨越了某个质量和能力的门槛(这个基础模型是在14.8万亿高质量标记上训练的)。
2- 与一般聊天或写作请求相比,推理问题可以自动验证或标记。让我们用一个例子来说明。
示例:推理问题的自动验证
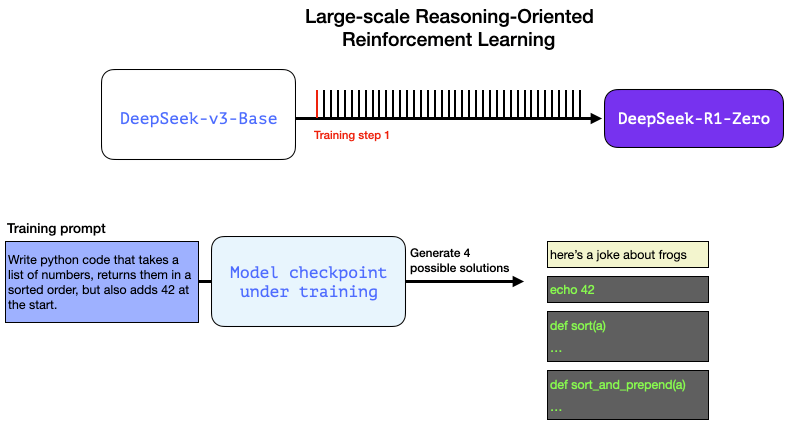
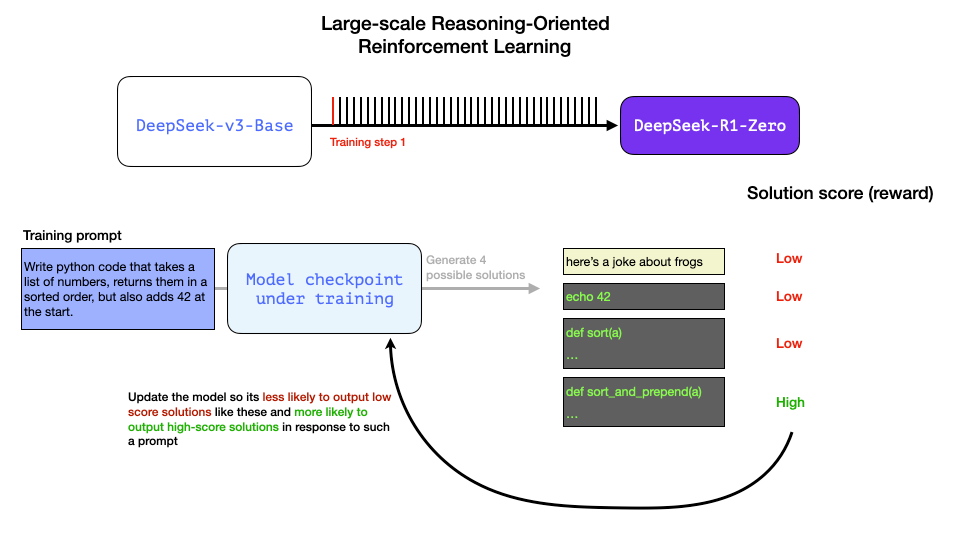
这可以是RL训练步骤中的一个提示语或问题:
编写Python代码,接收一个数字列表,将它们按顺序排序,并在开头添加42。
像这样的问题可以通过多种方式进行自动验证。假设我们将这个问题提供给正在训练的模型,它生成一个输出结果:
- 软件代码检查器可以检查输出的内容是否是正确的Python代码;
- 我们可以执行Python代码来看它是否能运行;
- 其他现代编程大语言模型可以创建单元测试来验证所需的行为(它们本身不需要是推理专家);
- 我们甚至可以更进一步,测量执行时间,让训练过程在正确的解决方案中偏好性能更好的解决方案;
我们可以在训练步骤中向模型提出这样的问题,并生成多个可能的解决方案。
我们可以自动检查(无需人工干预)并发现第一个输出结果甚至不是代码。第二个是代码,但不是Python代码。第三个是一个可能的解决方案,但未通过单元测试,第四个是正确的解决方案。
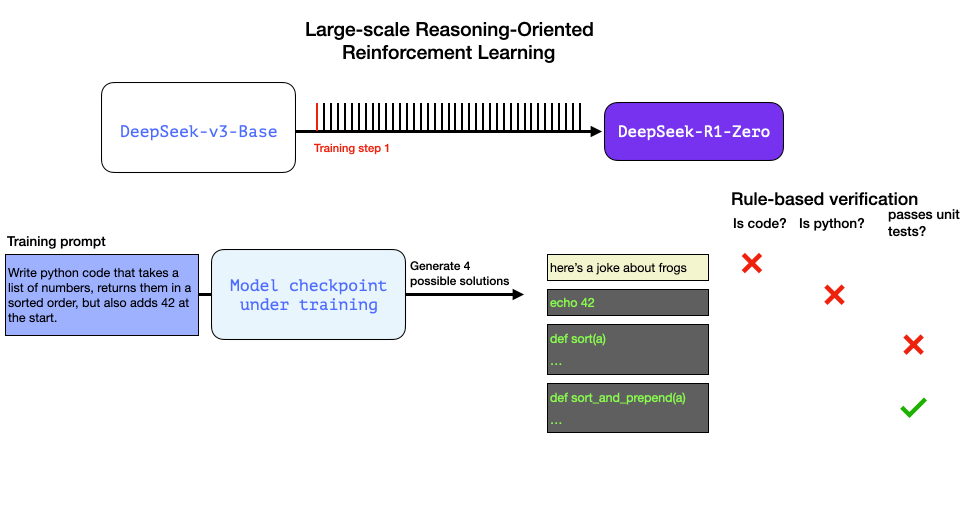
这些都是可以直接用于改进模型的信号。当然,这是在许多示例(mini-batch)和连续的训练步骤中完成的。
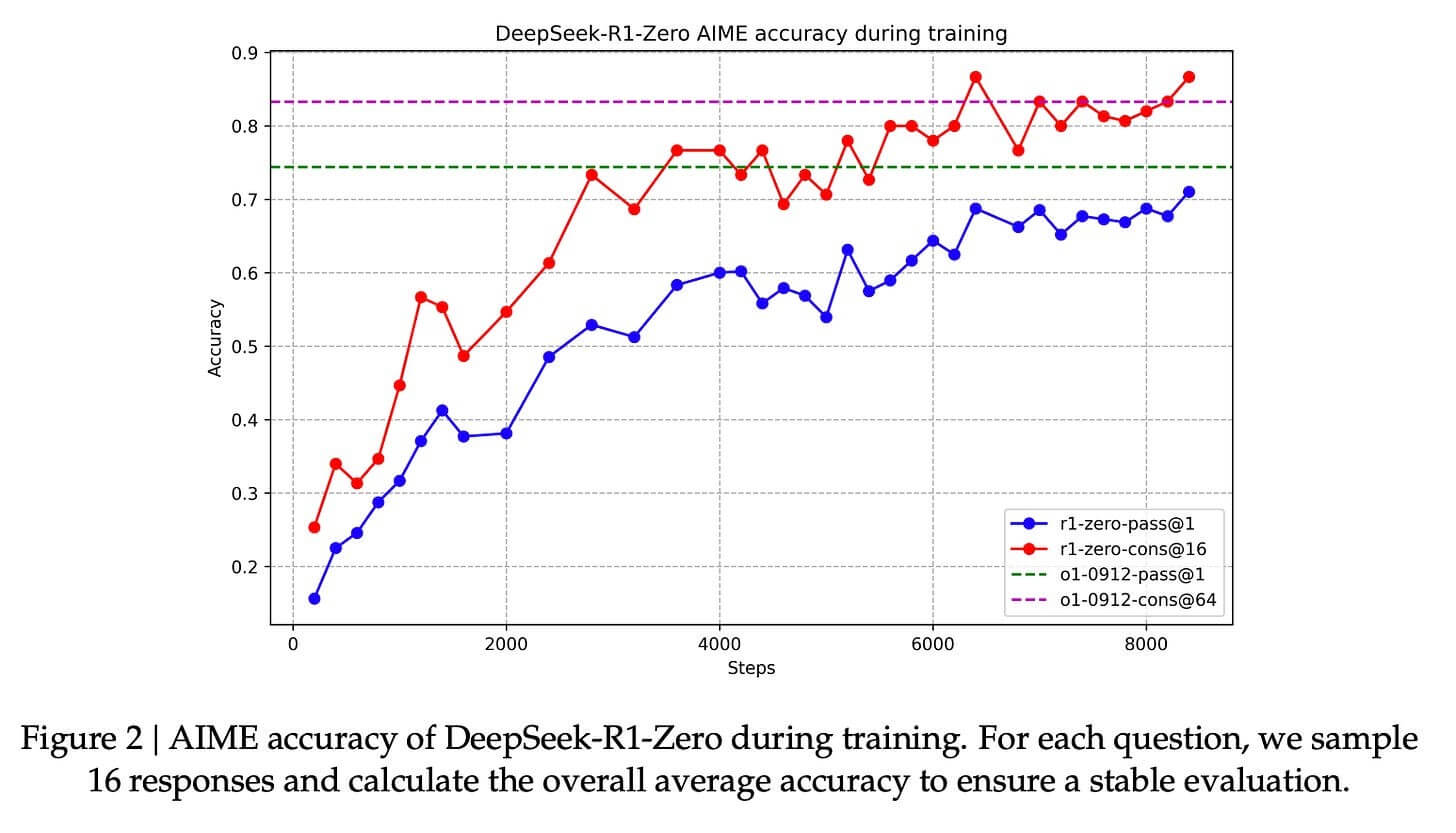
这些奖励反馈信号和模型更新是模型在RL训练过程中持续改进任务的方式,如论文中的图2所示。
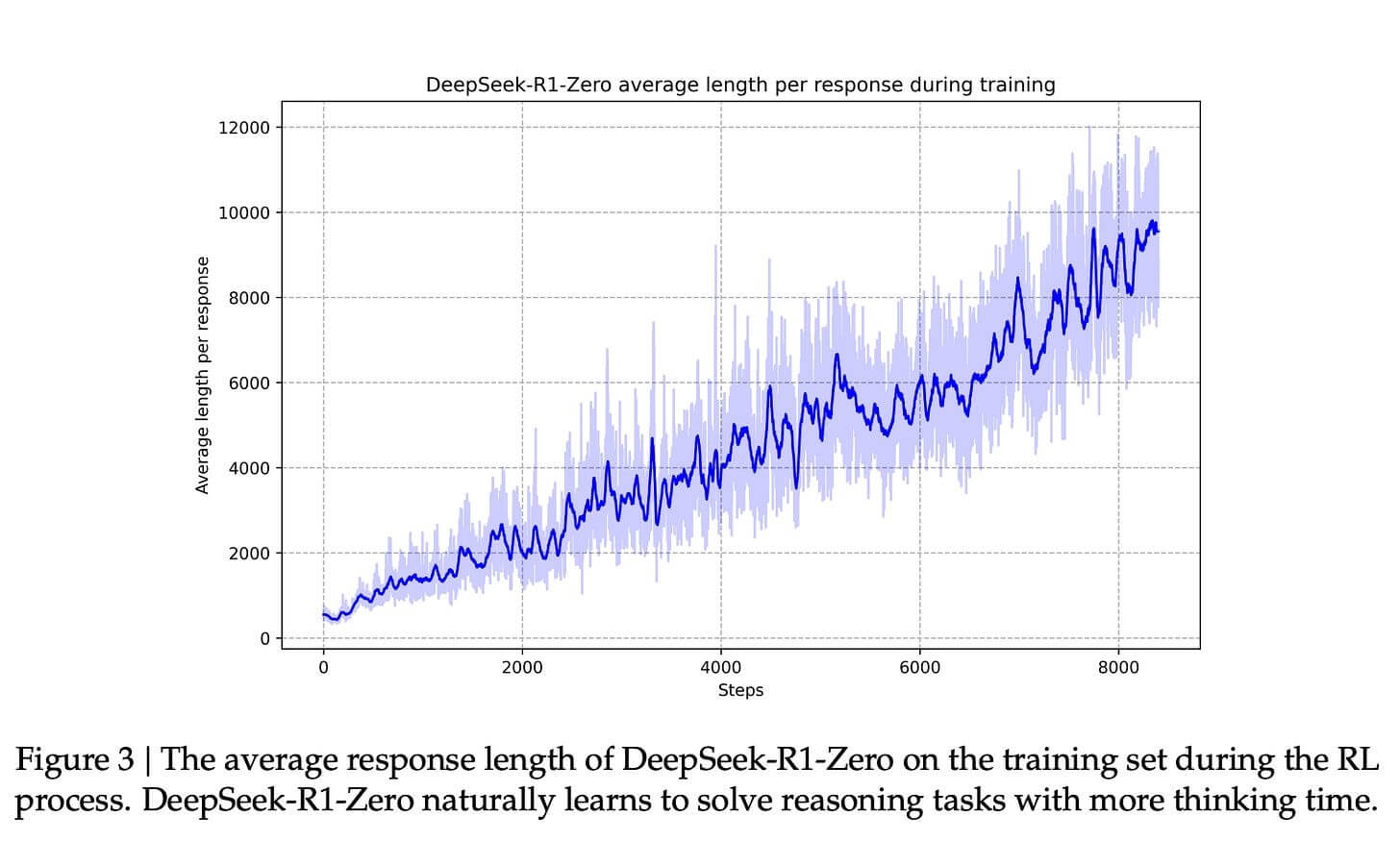
与这种能力的提升相对应的是生成响应的长度,模型生成更多用于思考的标记来处理问题。
这个过程很有用,但R1-Zero模型尽管在这些推理问题上得分很高,却面临着其他使其不如预期可用的问题。
虽然DeepSeek-R1-Zero展示了强大的推理能力,并自主发展出意想不到且强大的推理行为,但它面临着几个问题。例如,DeepSeek-R1-Zero在可读性差和语言混杂等方面存在挑战。
R1旨在成为一个更实用的模型。因此,它不是完全依赖RL过程,而是如我们在本节前面提到的,在两个地方使用:
1- 创建中间推理模型以生成SFT数据点;
2- 训练R1模型以改进推理和非推理问题(使用其他类型的验证器);
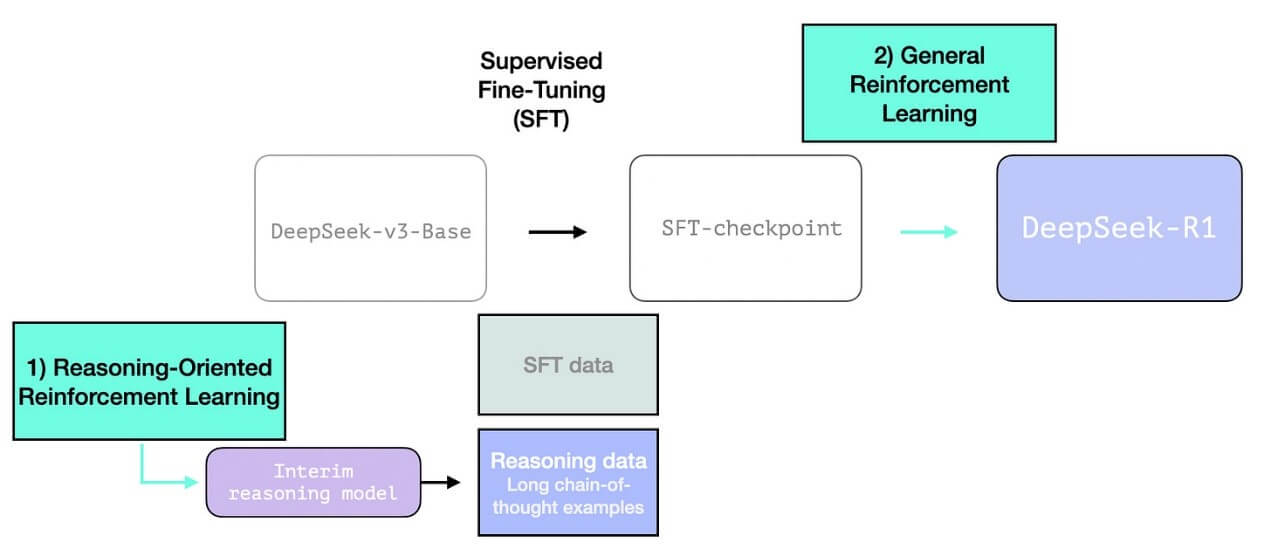
3.2 使用中间推理模型创建 SFT 推理数据
为了使中间层推理模型更加有用,它需要在几千个推理问题样本上进行监督微调(SFT)训练(其中一些是从 R1-Zero 生成并筛选得到的)。论文将这些称为”冷启动数据”(cold start data)。
2.3.1 冷启动
与 DeepSeek-R1-Zero 不同,为了防止基础模型在 RL 训练早期出现不稳定的冷启动阶段,DeepSeek-R1 构建和收集了少量长链式思维(Chain of Thought, CoT)数据,用于微调模型作为初始 RL 智能体。为了收集这些数据,我们探索了几种方法:使用带有长链式思维示例的少样本学习提示、直接提示模型生成带有反思和验证的详细答案、以可读格式收集 DeepSeek-R1-Zero 的输出,并通过人工标注者进行后处理来完善结果。
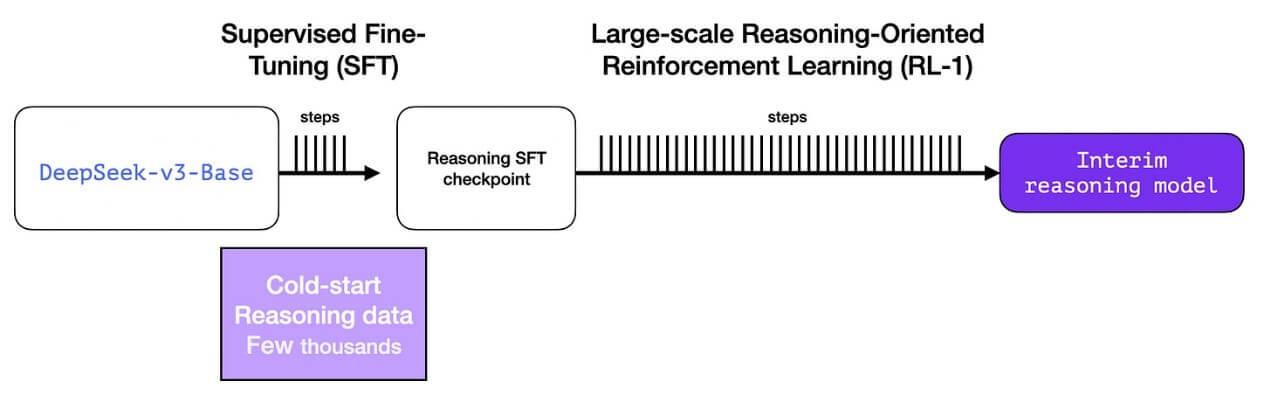
但是,如果我们已经有了这些数据,为什么还要依赖 RL 过程呢?这是因为数据规模的问题。这个数据集可能有 5,000 个样本(这是可以获得的规模),但训练 R1 需要 600,000 个样本。这个中间层模型弥补了这个差距,并能够合成生成这些极其有价值的数据。
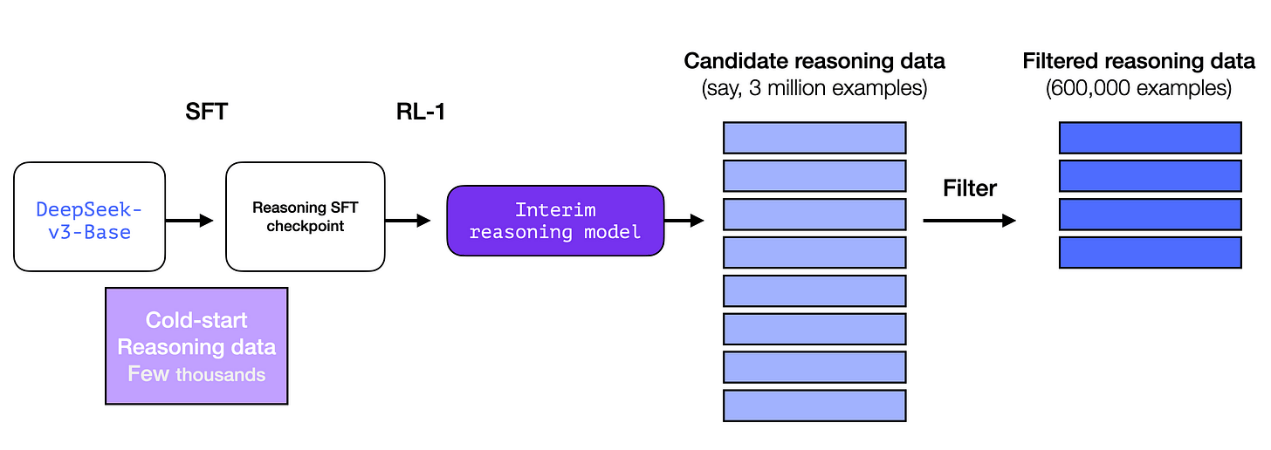
如果你不熟悉监督微调(SFT)的概念,这是一个向模型提供训练样本的过程,每个样本都包含提示词及其对应的正确答案。下图展示了几个 SFT 训练样本:
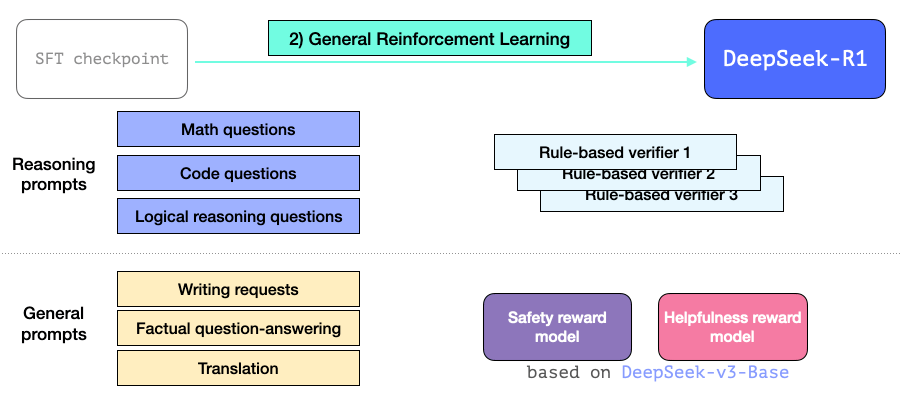
3.3 通用 RL 训练阶段
这使得 R1 不仅在推理任务上表现出色,在非推理任务上也能有良好表现。这个过程与我们之前看到的强化学习过程类似。但由于它扩展到了非推理应用,对于这些应用场景的提示词,它还采用了一个效用性和安全性奖励模型(类似于 Llama 模型的做法)。
模型架构
与 GPT2 和 GPT3 时代开始的早期模型类似,DeepSeek-R1 是由多个 Transformer 解码器块构成的。它总共包含 61 个解码器块。其中前三个是密集层,而其余都是混合专家系统层(Mixture of Experts, MoE)。
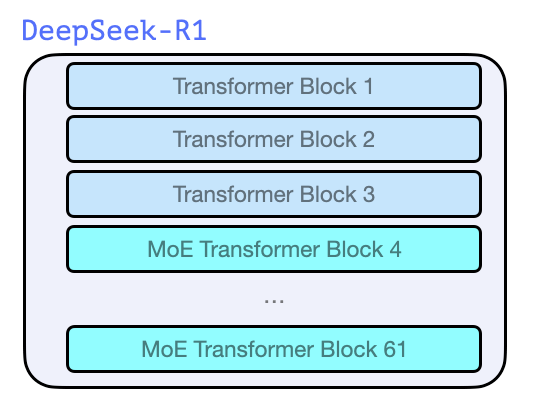
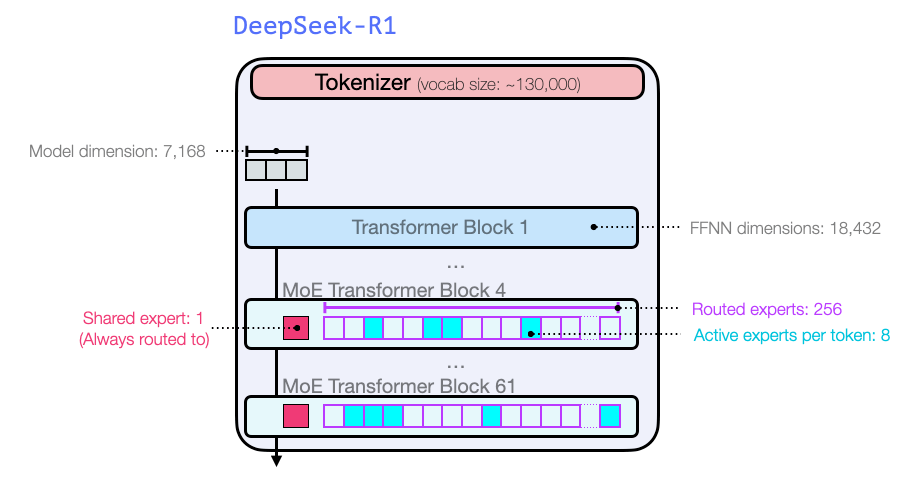
在模型维度大小和其他超参数(hyperparameters)方面,具体配置如下:
结论
通过以上内容,您现在应该已经能够掌握 DeepSeek-R1 模型的核心原理和主要设计思路了。
原文链接:https://newsletter.languagemodels.co/p/the-illustrated-deepseek-r1