DeepSeek-R1的创新到底在哪儿? - 重新定义AI推理能力的培养之道
今天Deepseek app在全球应用市场的排名再创新高 - 已在173个国家和地区登顶第一!考虑到全球目前一共只有174个国家/地区的市场分榜,而Deepseek唯一一个没有登顶的国家是汤加(第二名),这几乎就是完美的全球制霸!
这种势头可谓空前绝后,我们确实在见证一个历史性的时刻。
如果要想深入了解为什么Deepseek能取得这样的成绩,以及回应一些关于质疑Deepseek的创新点到底在哪儿的声音,我下面尝试深入浅出的来讲讲:
DeepSeek-R1的出现为AI领域带来了一个重要启示:
通过创新的训练方法,开源模型也能在推理能力上达到与顶级闭源模型相当的水平*。*
传统AI推理训练的困境
构建强大的AI推理能力一直面临着一个根本性的挑战:获取高质量的训练数据。传统方法主要包括:
- 雇用人类专家编写推理链:这种方式成本极高,且效率低下
- 利用现有模型做少样本提示:受限于源模型的能力上限
- 复杂的奖励建模:不仅难以调优,还经常出现训练不稳定的问题
这些方法都未能从根本上解决数据瓶颈的问题。而DeepSeek团队则另辟蹊径,提出了一个突破性的”以智养智”方案来实现数据的自举。
DeepSeek的突破性创新:以智养智
DeepSeek团队采用了一个三步走的方案 - 首先是通过纯强化学习(RL)训练出一个专门的推理模型R1-Zero。这个模型虽然在日常对话等任务上表现一般,但在数学和编程等需要严谨推理的领域却表现出色。接着,利用这个”专家模型”来生成海量的高质量推理数据,累计达到60万个训练样本。最后,这些数据被用于训练最终的通用模型DeepSeek-R1。
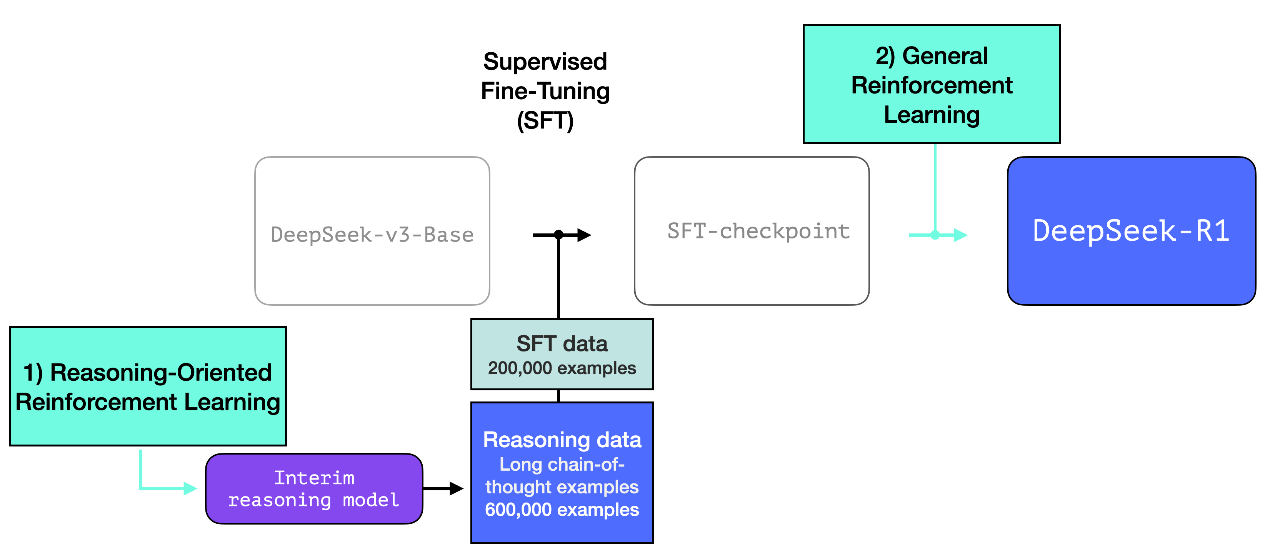
这个方案能够成功的关键在于充分利用了推理任务的一个独特性质:
答案的正确性往往可以通过程序自动验证。
例如对于编程任务,系统可以通过编译运行、性能测试等方式自动评估答案的质量;对于数学问题,也可以通过预设的验证程序来确认答案的准确性。这种自动化的验证机制为强化学习提供了清晰的奖励信号,从而使模型能在没有人工标注的情况下不断改进。
此外,从架构设计的角度,DeepSeek-R1采用了混合专家系统(MoE)架构,在其61层Transformer块中,除了前三层是常规密集层外,其余均为MoE层。这种设计不仅提升了计算效率,更重要的是可能为不同类型的推理任务提供了专门的处理通道,从而提高了模型的推理能力。
DeepSeek-R1 最令人兴奋的不仅是它的性能 - 更重要的是它教会我们如何训练 AI 系统:
- 纯强化学习/RL配合好的奖励函数可以产生惊人的效果;
- “师徒传承” - 专家模型可以成为通用模型的优秀教师;
- 有时解决数据问题需要重新思考整个训练方法;
我们正在看到一个从”投入更多数据”转向”设计更智能的训练策略”的转变。这将是通向更高效、更实用的 AI 发展的重要一步。