别那么快抛售英伟达:重新思考AI进化中的算力角色
Deepseek新发布的模型引发了AI圈的强烈关注:仅用竞争对手十分之一的GPU算力,就达到了顶级闭源模型的智力水平。这一突破迅速引发媒体广泛报道,在短短24小时内,Deepseek从43个国家应用市场榜首扩展到了160个国家,这家中国AI公司彻底出圈了。华尔街对这一消息反应激烈 - 英伟达股价暴跌17%,市值蒸发近6000亿美金。投资者似乎在传递一个明确信号:科技巨头们不计成本地投入巨资提升算力的策略可能走入了死胡同。
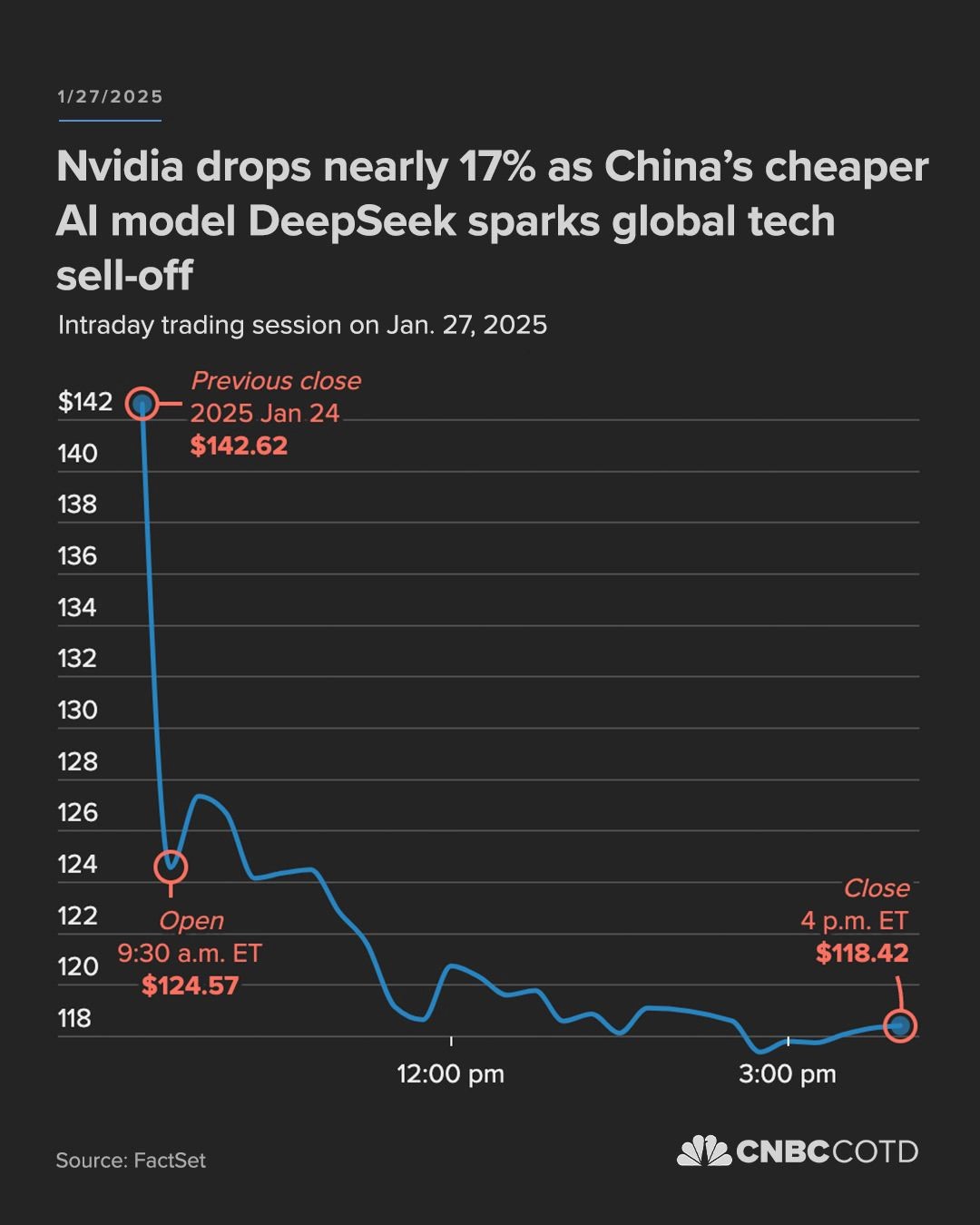
但是,作为一个长期观察AI发展的研究者,我认为这个结论过于简单化了AI进化的复杂性,昨晚也和一些朋友在微信群中做了热烈讨论。今早看到Andrej Karpathy发了一篇关于深度学习与算力关系的推文,感觉他提出的几个观点确实切中了要害,因此再结合一些自己的理解,谈谈为什么市场可能对算力的未来判断过于悲观。
首先,深度学习对算力的需求是独特的,这种需求的特殊性在AI发展史上前所未有。表面上看,Deepseek的突破似乎证明了我们可以用更少的算力达到相同的效果。但反过来想:
正是因为存在算力瓶颈,我们才被迫去寻找更高效的训练方法。
这种创新与其说是算力重要性的终结,不如说是算力压力推动下的必然产物。
其次,在传统认知中,算法、算力、数据是AI的三驾马车,彼此独立。但实际上,数据在很大程度上可以是计算的下游产物。通过强大的计算能力,我们可以生成海量的高质量合成数据。更为重要的是,这里有个不那么显而易见但极其重要的观点:
合成数据生成与强化学习之间存在着本质的等价性。
想象一下强化学习中的试错过程:每一次”尝试”本质上都是模型在生成新的合成数据,而每一次”错误”或”奖励”都在指导模型调整其生成策略。反过来说,当我们对合成数据进行筛选或评估时,这个过程本质上就是在实施一种原始的强化学习机制。这种深层联系告诉我们,算力不仅仅是训练速度的加速器,更是数据质量和多样性的关键保障。
最后,我们来理解一下学习的本质 - 在AI领域,存在两种根本不同的学习模式:模仿学习和试错学习。模仿学习就像是观察并重复,体现在预训练和监督微调/SFT中;而试错学习,则是通过强化学习实现的自主探索。AlphaGo的例子完美诠释了这两种方式的差异:它首先通过模仿人类专家的对局来学习基本策略,但真正让它超越人类的,是通过强化学习自主发现的创新策略。从它战胜李世石的历史性时刻,到现代大语言模型展现出的”顿悟时刻”,几乎所有令人震惊的AI突破都来自于试错学习的力量。
这种试错学习的过程本质上就是计算密集型的。
它需要模型不断尝试、失败、改进,需要在庞大的可能性空间中探索。这不是简单的效率问题,而是突破性能边界的必经之路。
而且,我昨天写Deepseek文章结尾能引发出一个有趣的悖论:
降低单个模型的算力需求反而可能推动整个行业对算力的总需求上升
截至目前,尽管AI已经成为热门话题,但真正的普及率其实并不高。无论是在中国还是美国,大多数人对AI的认知仍停留在概念层面,或者仅限于简单尝鲜。但Deepseek的突破正在改变这一现状,它向整个行业证明:高质量的AI服务可以做到既开源又平价,而用户对真正好用的AI产品有着巨大的潜在需求。
这种示范效应的影响可能比技术突破本身更加深远。当更多互联网公司看到这种可能性,必然会加速布局AI应用开发。而当越来越多的普通用户开始在日常工作和生活中使用AI工具,规模效应带来的算力需求可能远超过单个模型优化带来的节省。
所以,市场对Deepseek消息的反应可能确实过于情绪化。Deepseek呈现的工程创新确实能提升训练效率,这值得赞赏。但这种创新带来的不是算力需求的终结,而是AI应用加速普及的催化剂。随着我们追求更高层次的AI能力,特别是在探索通用人工智能的过程中,算力的整体需求只会进一步提升。
在AI这场进化马拉松中,工程创新和算力投入从来就不是非此即彼的选择。我们既需要不断提升训练效率,也需要持续扩展算力边界。只有这样,才能真正推动AI向更高智能迈进。