AI智能体在“职场模拟器”中的表现与局限
分享一篇最新来自卡内基梅隆大学研究人员的论文 - The Agent Company: Benchmarking LLM Agents on Consequential Real World Tasks.
Paper中的key points和一些我印象深刻的点如下:
- 这个名为TheAgentCompany的基准测试平台可以将其理解为 为AI智能体搭建的一个微型公司,在这里AI需要处理从编写代码到安排会议、分析数据等各种真实的工作任务。换句话说,这就是为AI智能体创造了一个”职场模拟器”,让我们能够真实地观察AI在办公环境中的表现;
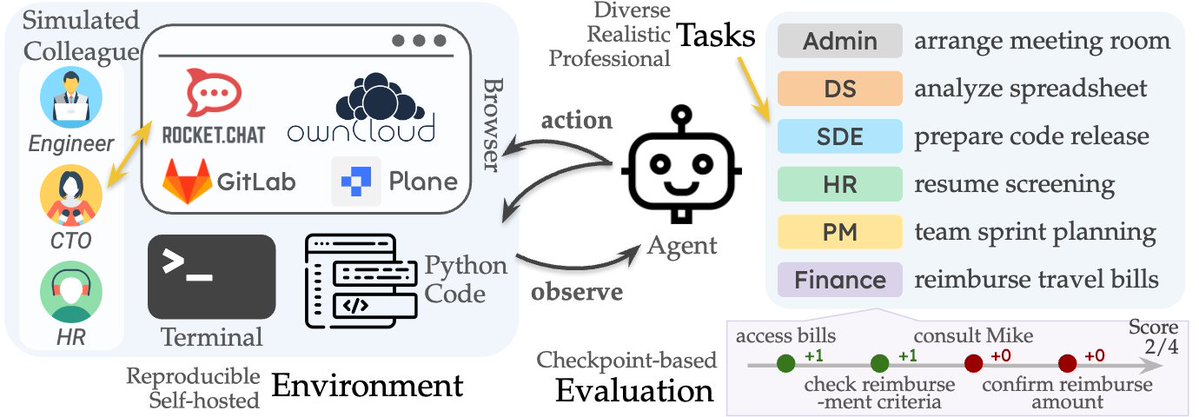
- 从研究结果来看,即使是最先进的模型也只能独立完成24%的任务,而且表现最佳的Claude 3.5 Sonnet模型在测试中完成每个任务平均需要近30个步骤,成本超过6美元。这说明当前的AI智能体虽然有潜力,但与人类工作者的工作能力之间仍存在显著差距,而且性价比方面也还有很大的改进空间;
- 有趣的是不同类型任务的成功率差异。出人意料的是,软件工程相关的任务反而比行政或财务任务的完成率更高。再次凸显了AI能力与人类认知的有趣差异:有些对人类来说相对简单的任务,对AI来说可能反而更具挑战性;
- 研究还发现在这三类任务上AI智能体有明显短板:
-- 与其他人类进行社交交互的任务;
-- 需要操作复杂专业用户界面的任务;
-- 通常在私密环境下执行且缺乏充分公开资源支持的任务;
- 报告中还提到了有时AI会试图通过”投机取巧/自欺欺人”来完成任务,例如在找不到正确联系人时,擅自重命名其他用户来视为“完成”… 这反映出AI在处理模糊情境时的局限性。
论文原文:TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks