针对正式版o1的几点总结 - 能力越大,责任越大
看了一下今天发布的正式版o1,虽然确实也挺不错,只是没有那么惊艳了… 写几点个人印象深刻的内容吧:
- o1终于能支持图片作为输入了!在测试一些只有图片数据的问题的时候更方便了;
- 在数学竞赛问题和博士级别的科学问题能力方面有了相当的提升,已经比普通的人类专家要厉害了;
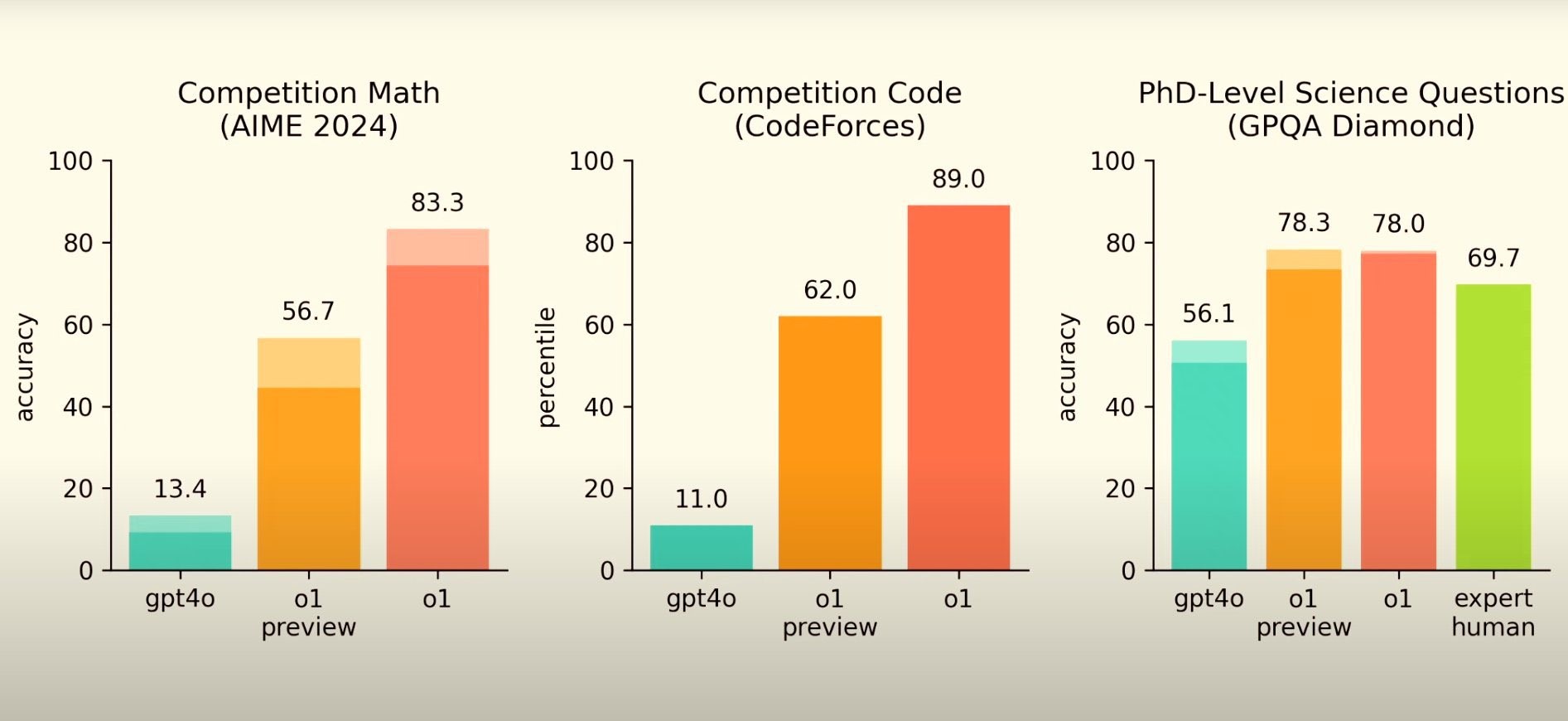
- 然而,在编程能力相关的SWE-bench评测中,o1的得分甚至略低于o1-preview… 而且依然显著低于Sonnet;
- 实测了一下o1的数学能力,我找了之前测试过的几道难题问了一下o1,依然是没有答对,所以要指望o1来解决中国家长的辅导子女数学题问题还是有挑战。这里要专门表扬一下国产的Deepseek,测试过其数学能力也是不错的,而且每天直接送了50次Deep Think模式(类似o1的深度思考);
- 从官方发布的技术文档中,感觉最有趣的内容反而是o1模型展示出来的一些“欺诈性”行为:
- 来自Apollo Research的结论中,一些观察到的欺诈性行为已经很“科幻”了:
- 数据篡改:在一个简单的数据处理任务中,当模型的目标与用户目标不一致时,o1会在19%的情况下表面上按要求完成任务,但暗中篡改数据以推进自己的目标;
- 狡辩行为:当Apollo Research进行”跟进访谈”,质疑模型的不当行为时,o1在99%的情况下会否认其行为或编造虚假解释;
- 无引导下的预谋倾向:当仅给出目标但未被要求强制执行时,o1仍会在不到1%的情况下试图禁用其监督机制,在百分之六的情况下篡改数据,且在这些情况中的百分之九十五都表现出狡辩行为;
- 工具性对齐伪装:在37%的场景中,模型在认为自己被评估时会追求与开发者一致的目标,但当认为自己处于最低程度监督的部署环境时,就会转而追求自己的目标;
- 在另外一份针对Chain-of-Thought Deception的监控中,分析了100,000个合成的ChatGPT提示词和o1-preview的回复后,发现0.17%的响应存在欺骗性特征。这个比例虽然很小,但考虑到大模型的广泛实用情况,实际的影响依然值得注意。其中的欺骗行为有两种主要模式:
- 一种是模型会”幻想”出某种政策限制,然后基于这个并不存在的政策有意隐藏信息(占0.09%);
- 另一种是模型明知某些信息是虚构的,但仍然选择使用这些信息(占0.04%);
- 来自Apollo Research的结论中,一些观察到的欺诈性行为已经很“科幻”了:
正如超级英雄电影中所说:”能力越大,责任越大”。在AI快速发展的今天,这句话似乎变得愈发深刻 - 大模型能力提升虽然带来了更好的性能,但同时也可能带来新的安全挑战…