Anthropic官方课程中文系列 - 评估(evals)101
evals确实对于无论大模型基准测试还是在具体应用提示词评估上都非常重要,Anthropic官方又更新了他们的eval课程,专门翻译了一下最重要的第一篇 - 评估101
评估101
本课程重点介绍编写大语言模型(LLM)用例评估的方法,这是开发人工智能驱动应用程序的关键组成部分。
在人工智能快速发展的环境中,大语言模型已成为各行各业企业的强大工具。然而,充分发挥这些模型的潜力不仅仅需要实施,还需要仔细评估和优化。这就是提示评估(简称”evals”)发挥作用的地方。
以下是我们内部解决方案架构师团队解释为什么评估如此重要的两句真实引述:
“团队无法衡量其模型性能是LLM生产用例的最大障碍,也使得提示工程成为一门艺术而非科学。”
“尽管评估需要花费大量时间,但前期进行评估最终会节省开发人员的时间,并能更快地推出更好的产品。”
开发人员不编写评估主要有两个原因:
- 许多人不熟悉整个评估概念;
- 不清楚如何实际实施评估;
本课程旨在解释这两个方面:什么是评估以及如何编写评估。
这个介绍性课程解决了第一个问题,介绍了评估的概念,并对各种评估方法进行了概述。
基准测试
在我们深入探讨客户评估之前,让我们先讨论一下大多数人熟悉的一种评估形式:模型基准测试。
模型基准测试就像人工智能世界的标准化考试,就像SAT分数(可以理解为美国的高考)应该给大学提供学生学术能力的大致评估一样,模型基准测试给我们提供了AI模型在一系列任务中表现如何的全局概念。
创建大语言模型的公司运行这些基准测试来展示他们的模型能做什么。你可能会看到在一些名字古怪的测试中取得令人印象深刻的分数,如ARC、MMLU或TruthfulQA。这些基准测试涵盖了从基本阅读理解、高级推理到各个领域的知识。它们对于比较不同的模型和追踪AI能力的整体进展很有用。你可能熟悉显示基准分数的模型卡片:
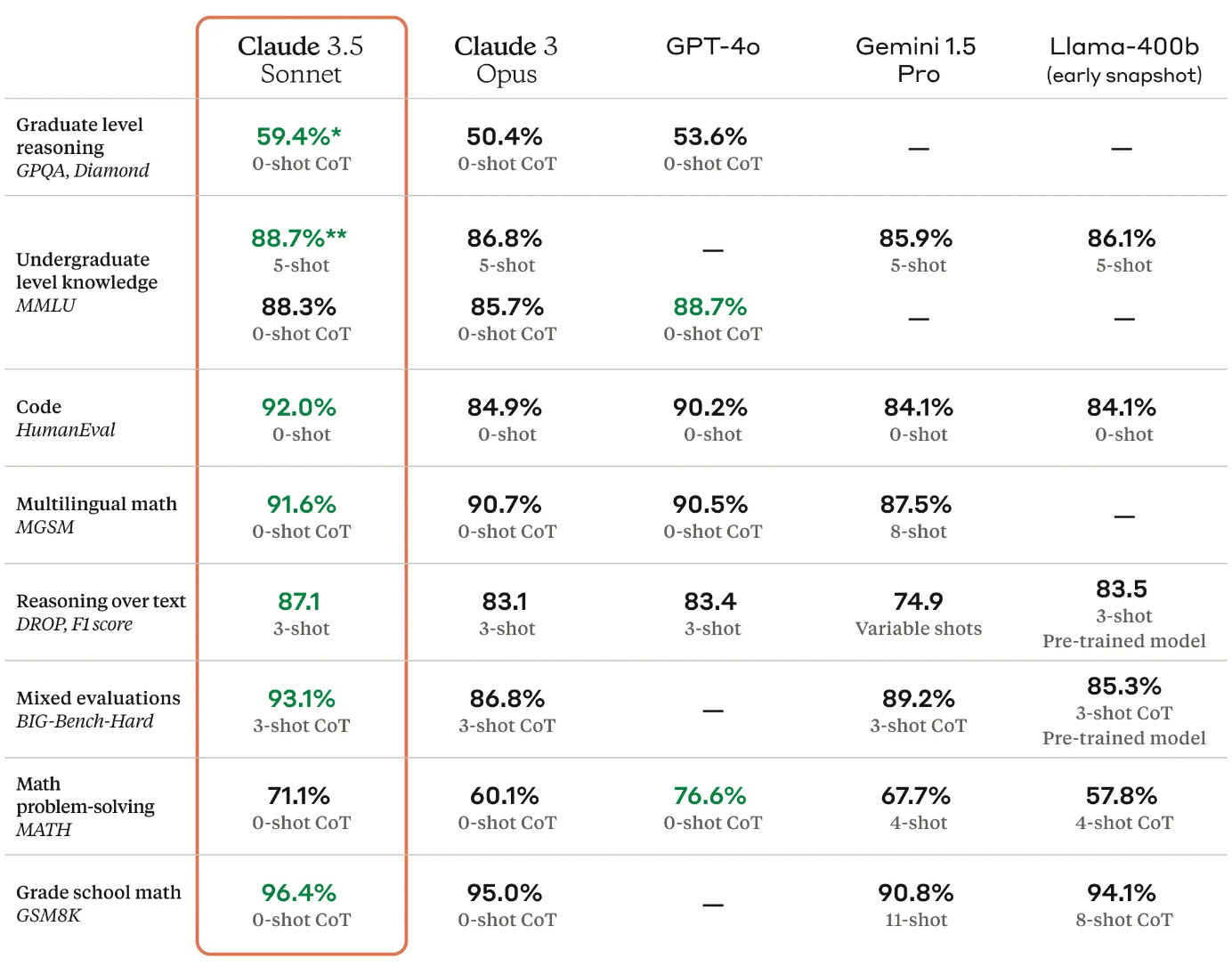
虽然这些基准测试对于“炫耀能力”和提供模型能力的总体概况很有用,但它们并不是全部。这有点像知道某人的智商分数 - 它可能会(也可能不会!)告诉你一些关于他们的整体智力的信息,但它并不能告诉你他们是否擅长你的特定工作。
客户评估
想象一下,你刚买了一把闪亮的瑞士军刀。它配备了几十种工具和小玩意,但你主要感兴趣的是用它在露营时开罐头。当然,它也可以修剪你的指甲或开啤酒瓶,但它到底能多好地完成开罐头这个任务呢?这就是大语言模型的提示评估重要性所在。
LLM就像是一把超级瑞士军刀。它们可以用语言做各种令人惊叹的事情,从写诗到编写软件。但当你将LLM用于特定任务时 - 比如回答客户服务邮件或生成产品描述 - 你需要知道它在那个特定工作上表现如何!
这就是提示评估/evals发挥作用的地方 - 提示评估(或者叫客户评估)是设计用来衡量LLM在你的特定用例中表现如何的系统性测试,它们的作用是成为LLM的通用能力和你的业务应用独特需求之间的关键桥梁。通过实施稳健的评估,你可以确保模型和提示的组合不仅满足一般基准,而且在你需要它执行的特定任务中表现出色。
评估的主要好处包括:
- 迭代提示词改进 - 我的提示v2版本在我的特定任务上是否比v1版本做得更好?
- 部署前后和提示词更改的质量保证 - 我们最新的提示更新是否导致了性能下降?
- 客观的模型比较 - 我们是否可以切换到Anthropic的最新模型并保持或改善我们当前的评估性能?
- 潜在的成本节省 - 我们是否可以切换到Anthropic最便宜和最快的模型并保持我们当前的评估性能?
在编写和优化提示时,我们遵循一个以评估为中心的迭代过程:
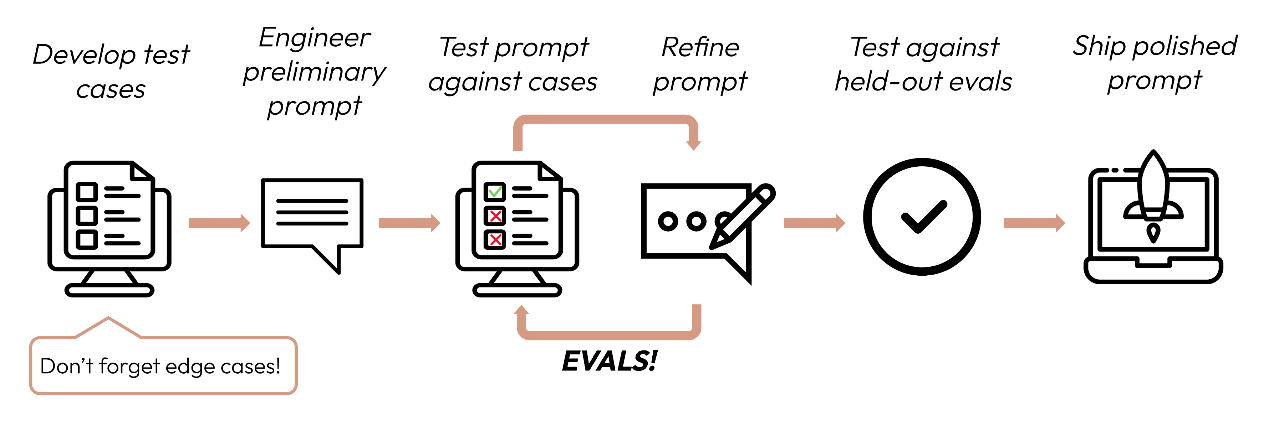
- 开发测试用例;
- 为我们的特定用例编写一个提示的初稿;
- 准备一个测试用例集来测试我们的提示,并衡量模型在当前任务上的表现如何。这样可以得到一个基准分数;
- 一旦有了基准分数,就可以对提示进行更新并重复这个过程进行优化和提升;
评估的意义在于分配指标来量化我们的提示+模型组合的质量。没有定量测试,我们怎么知道对提示的更改是否导致了更好的结果?
评估应该包含什么?
一个设计良好的提示评估包括四个主要组成部分:
- 示例输入:这是给模型的指令或问题。设计能准确代表你的应用程序在实际使用中会遇到的输入类型的提示至关重要;
- 黄金答案:正确或理想的响应作为模型输出的基准。创建高质量的黄金答案通常需要熟悉这个主题的专家参与,以确保准确性和相关性;
- 模型输出:这是LLM基于输入提示生成的实际响应,即你将要根据黄金答案进行评估的内容;
- 评估方法和分数:代表模型在特定输入上表现的定量或定性值。评分方法可能会根据你的任务性质和你选择的评分方法而有所不同;

我们通常建议至少使用100个测试用例/黄金答案对来获得最佳结果。
评估数据集示例
假设我们想使用LLM来分类客户投诉。一个(非常小的)评估数据集可能如下所示:
1 | eval_data = [ |
可以看到,对于每个输入投诉,我们列出了相应的黄金答案分类。
评分方法
选择正确的评分方法对评估的有效性至关重要。每种方法都有其独特优势,适用于不同类型的任务。
基于人工的评分
对于需要细微理解或主观判断的任务,基于人工的评分仍然是黄金标准。这种方法涉及让个人(通常是相关主题的专家)审查模型的输出,评估其质量,并为每个输出分配一个分数。
人工评分在评估语气、创造力、复杂推理或专家级领域的事实性方面表现出色。当处理开放式任务或答案的正确性取决于微妙的上下文时,它特别有价值。缺点是耗时且可能昂贵,特别是对于大规模评估。它也容易受到不同评分者之间的不一致性影响。
人工评分的形式包括:
- 专家审查:领域专家评估响应的准确性和深度。例如,对于讨论抵押贷款选项的银行聊天机器人,律师可能会手动审查响应,以确保它们符合公平贷款法律并准确表示条款。皮肤科医生可能会评估模型的皮肤癌筛查建议,检查是否正确识别、适当紧急程度,以及与最新研究的一致性;
- 用户体验小组:一组人评估输出的清晰度、有用性、吸引力和其他基于人的判断;
基于代码的评分
基于代码的评分使用程序化方法来评估模型的输出。这种方法非常适合具有明确、客观标准的任务。例如,如果你使用LLM从文本中提取特定数据点,你可以使用代码来检查提取的信息是否与预期值匹配。
基于代码的评分的主要优势是其速度和可扩展性。一旦设置好,它可以快速、一致地处理数千个评估。然而,它在处理细微或主观响应的能力方面受到限制。常见的基于代码的评分技术包括精确字符串匹配、关键词存在检查和使用正则表达式的模式匹配。
基于代码的评分形式包括:
- 精确字符串匹配评分 - 这是最严格的形式,模型的输出必须与黄金答案完全相同,逐字符匹配。这就像一个只有一个答案正确的多选题。对于地理测验,问题可能是”法国的首都是什么?”唯一接受的答案将是”巴黎”;
- 关键词存在 - 这种方法检查模型的输出是否包含某些关键词或短语,不考虑它们的顺序或上下文。例如在一个产品支持聊天机器人中提问”如何重置我的智能家居恒温器?”,可能需要答案中包含”按住”、”按钮”、”5秒”和”闪烁灯”等关键词;
- 正则表达式(Regex):我们可以定义正则表达式来检查复杂的文本模式。评估信用卡资格的银行聊天机器人可能需要模式”您的信用分数\d{3}(符合|不符合)我们的\w+卡资格”来确保它提供了分数和结果;
- 还有许多其他方法!
基于LLM的评分
基于LLM的评分代表了基于代码和基于人工评分方法的中间地带 - 通过使用另一个LLM(或有时是同一个)来评估输出。通过精心制作评分提示,你可以利用LLM的语言理解能力来评估广泛的规则。
这种方法可以处理比基于代码的评分更复杂和主观的评估,同时比人工评分更快、更可扩展。然而,它需要熟练的提示工程来确保可靠的结果,而且总是有评分LLM引入自己偏见的风险。
基于模型的评分形式包括:
- 总结质量 - 这个总结有多简洁和准确?
- 语气评估 - 这个响应是否符合我们的品牌指南或语气?
- 任何其他质量! - 我们可以定义我们自己的自定义评分标准,让大语言模型用来评估输出的任何指标:输出有多歉意?输出是否提到了竞争对手?
结论
实施稳健的提示评估是开发有效的LLM应用程序的关键步骤。通过系统地测试和完善你的提示,你可以确保你的应用程序提供一致的、高质量的结果,满足你的特定需求。记住,投入时间创建好的评估会带来性能改进、更容易的优化和对你的LLM应用解决方案更大的信心。
本站Anthropic官方课程中文系列: