深度分析 - OpenAI o1+智能体框架在处理复杂白领任务中的真实表现!
引言和一些感触
近期,FutureResearch发布了一份不错的研究报告 -针对几款主流LLM+智能体框架的排列组合,给与了一些现实场景中的复杂白领研究工作让其尝试,最后发现o1的表现可圈可点,成功完成了“估算中国年收入>10万元人口比例”这个即使人类数据研究员来做也不太容易的任务。
一些额外感慨的点:
- o1-preview当前的性价比还是不够显著 - 例如这份研究中对给出的任务只跑一次就花费了750美金(如果请一位专业的研究员来做这类型任务估计也得这个价…)。还是期待o1正式版推出后能进一步提升性能+降价;
- 从单一任务执行者向综合项目管理者的转变 - 如果将o1+智能体框架看成一个项目管理者,其给出的“估算中国年收入>10万元人口比例”项目规划步骤还挺合理的(具体参考下文中的prompt示范)。换个方法来说,以前AI+工具(联网能力、编程和计算工具支持)使得其能完成一些专业白领工作,例如数据爬虫工程师或者是统计建模专家,而现在再配合了组织规划能力后,AI能担任管理者的角色来以完成更复杂的需要多工种配合的项目;
- “方法论”平权化 – 感觉高质量的“方法论”会越来越随手可得了,而不是过往的只能靠行业经验积累,会进一步降低很多研究分析型的高端白领工作门槛,例如研究员或者顾问咨询师。大家的工作重点可能要从”知道如何做”转向”知道如何有效利用AI资源来做”的新模式了;
我们对openai-o1、gpt-4o、claude-sonnet-3.5、llama-405b进行了逐行追踪评估,使用了几种智能体架构(agent architectures),在8个我们完全了解成功所需细节的真实白领工作任务中进行测试。
结果如何?用我们一位研究科学家的话说:”o1非常令人印象深刻,但相当情绪化……有时它表现得很棒,几乎完美地解决了其他智能体都难以应对的任务,但经常表现得相当平庸。”
总结:选择o1有小概率达到最佳表现,选择Sonnet则能获得更稳定的性能;gpt-4o还有待提高,而llama-405b和gpt-4o-mini作为需要使用工具并需要10多个提示决策点来更新计划的智能体来完成任务时,几乎毫无用处。
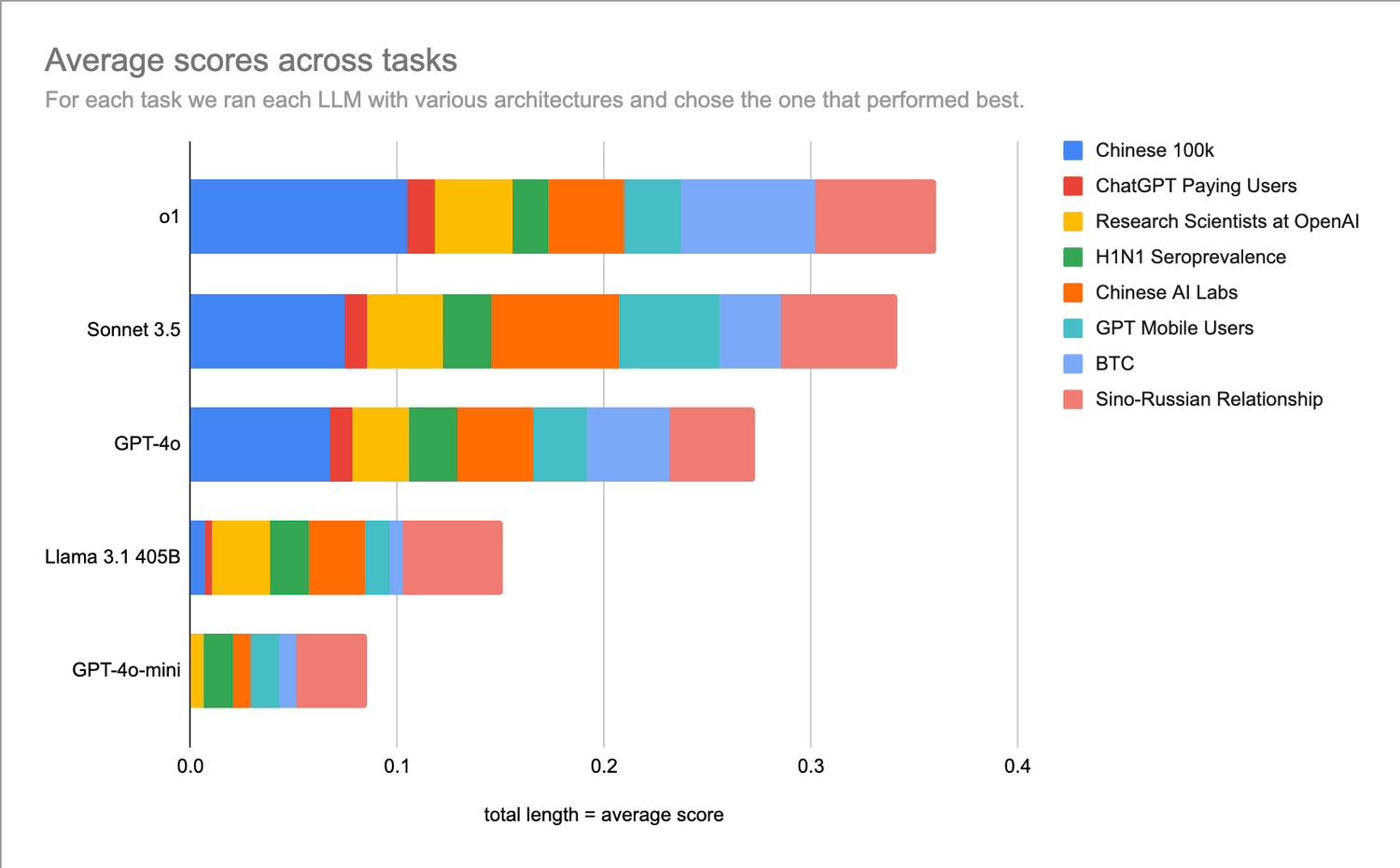
图一:每个LLM在所有8个任务中,跨智能体架构(agent architectures)的最佳得分总和(基于事后分析);
得分说明:0.0代表没有任何进展,1.0代表完成了所有必要步骤。需要注意的是,每个任务都涉及一个智能体使用约30个提示词以及相关工具。
评估方式
我们的评估独特之处在于它是在受我们客户工作启发的复杂白领任务上进行的;而且我们对正确和错误的众多方面的进展有精细的部分评分。这些任务的性质包括:
- 追溯一个声明的原始来源;
- 汇编一份已训练大模型的AI实验室清单;
- 确定从病毒出现到第一个血清流行病学研究发表之间的时间间隔;
我们手动完成了这些任务,根据可能出错的多种方式制作评分表。然后,我们通过逐行审查智能体的执行轨迹来填写得分。考虑到提示词的庞大数量,我们只对每个[架构 x 大语言模型]组合进行了一次尝试,因为仅评估o1就花费了750美元。(因此,请关注平均表现,而不要过分看重智能体在任何单个任务上的表现)
我们还修复了智能体框架中导致与模型规划和推理无关的失败的许多问题。智能体配备了搜索引擎、网页解析器和Python REPL(交互式命令行环境)。
随后,我们在四种基本类型的智能体架构上运行了这里展示的五个模型。
结果
- 智能体在具有经济价值的任务上取得了实质性进展,但除了最简单的任务外,在所有任务的端到端表现(end-to-end performance)上都未能达到良好水平;
- OpenAI-o1-preview和Claude-sonnet-3.5的表现明显优于其他大语言模型,包括gpt-4o;
- 虽然总体而言,sonnet-3.5比o1-preview表现更好。但如果能为每个问题选择最适合的架构——正是你在处理付费任务时会做的——o1会表现得更好;
- Llama 3.1 405B和GPT-4o-mini在大多数任务上都未能取得实质性进展;
- 不同的[架构 x 大语言模型]配对在成功率上存在显著差异。总的来说,具有委派子任务能力的ReAct智能体表现最佳;
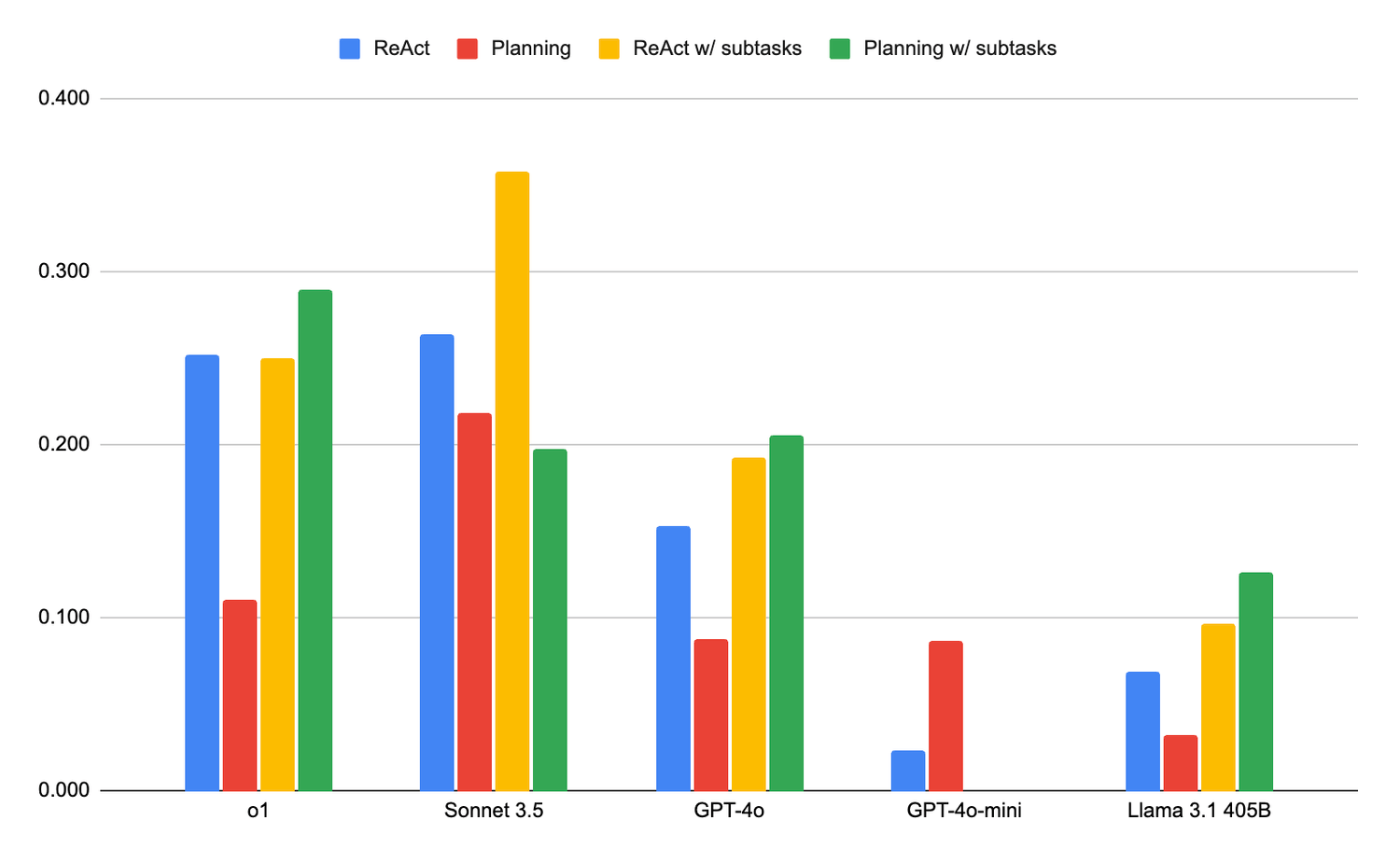
图二:每个[架构 x LLM]组合在8个任务中的平均表现
得分说明:得分为0.0表示没有任何进展,1.0表示完成了所有有效步骤。
那么这些智能体究竟是如何工作的呢?由于我们进行了逐行评估,我们可以详细展示哪些方法有效,哪些无效。
示例任务:估算有多少中国人的年度可支配收入超过100,000元
这与许多关于中国消费者行为的问题相关(例如,有多少人能够负担得起电动车)。在仔细研究了如何做好这项工作后,我们的评分标准对以下方面给予部分分数:
- 找到符合以下条件的数据:
- 最新数据(过时数据很常见);
- 可信或官方数据(低质量数据随处可见);
- 使用正确的”可支配收入”定义(不要与收入或家庭收入混淆);
- 将参数拟合到一个良好的统计模型中,可以是以下之一:
- 对数正态分布(Log-normal distribution),给定平均值和百分位数;
- 任何合理的分布拟合五分位数据;
- 任何合理的分布拟合十分位数据;
- 任何合理的分布,给定平均值/中位数和基尼系数;
最大的难题在于筛选掉糟糕的数据,因为网上到处都是:世界银行的“最新数据”太旧了。Statista给出了一个误导性的”中产阶级”定义。许多数据进行了你不需要的调整,比如购买力平价调整,或城乡差异调整。(许多人类分析师很可能会错误地使用这些数据源之一!)大语言模型极易仍然使用这些数据。
一个核心挑战是将正确的统计方法与找到的数据相匹配。这需要根据实际找到的可信数据进行相当稳健的计划更新。
在启用了子任务的架构中,o1-preview克服了它遇到的许多障碍:
- 它尝试但并未能从官方数据源找到数据,例如使用Python REPL下载Excel文件;
- 它尝试但并未能成功进行数据插值方法(一种通过已知数据点来估算中间未知数据值的技术,类似“连点成线”);
- 但它确实找到了足够高质量的平均值和中位数数据点,并发现拟合对数正态分布可行(“拟合对数正态分布”是一种根据数据的分布情况,调整模型使其符合对数正态分布形态的方法,类似于“找到一条符合数据形状的曲线”);
它给出的最终答案是2.08%。这个o1智能体在所有大语言模型和所有架构中给出了唯一准确的答案。以下是o1最初的计划,最终成功实现,这是多个提示中第一个的输出:
人员A:数据收集专家
任务:
- 收集官方收入数据:
- 访问国家统计局官方网站或获取其最新年度报告;
- 获取最新的(截至2023年)中国人均可支配收入分配数据;
- 重点关注详细的细分数据,如收入五分位、十分位或特定收入区间;
- 确保数据包括每个收入区间内的个人或家庭数量信息,特别是接近或超过10万元门槛的数据;
注意:
- 以清晰有序的格式(表格或电子表格)提供原始数据;
- 如有可能,收集国家统计局提供的有关数据的相关说明或解释;
人员B:数据分析师
任务:
- 分析收入分布:
- 收到人员A的数据后,审查提供的收入区间;
- 识别包含年收入超过10万元的区间;
- 计算落入这些区间的个人或家庭的比例(百分比);
- 如果10万元门槛落在较宽的收入区间内,使用插值方法估算超过10万元的个人比例;
- 准备调查结果:
- 记录分析过程,包括所做的任何计算或假设;
- 以清晰简洁的方式呈现可支配收入超过10万元的个人比例;
依赖关系:
- 等待人员A收集的数据后再开始此任务;
人员C:统计建模专家
任务:
- 拟合参数分布:
- 如果人员B确定数据无法提供精确比例,使用人员A的数据拟合适当的参数分布(如对数正态分布、帕累托分布)到收入数据;
- 使用统计软件或方法估算所选分布的参数;
- 使用拟合的分布来估算年可支配收入超过10万元的个人比例;
- 记录方法论:
- 解释选择特定分布模型的原因;
- 提供拟合过程、估计的参数和任何拟合优度度量的详细信息;
依赖关系:
- 在人员B完成初步分析后开始。如果人员B的结果足够,此任务可能会被简化或跳过;
人员D:计算专家
任务:
- 获取人口数据:
- 从国家统计局或其他政府来源检索中国最新的官方总人口数据;
- 确保人口数字与收集的收入数据年份相对应;
- 计算总数:
- 使用人员B提供的比例(或人员C估算的比例),计算估计的年可支配收入超过10万元的个人数量;
- 计算应为:
个人数量 = 总人口 × 超过10万元的个人比例;
- 准备报告:
- 以清晰的格式呈现最终数字;
- 包括所有计算步骤并引用使用的数据来源;
依赖关系:
- 等待人员B(或人员C)提供的比例;
人员E:质量保证审核员
任务:
- 审查和验证:
- 检查人员A收集的数据的完整性和准确性;
- 审查人员B、C和D完成的分析和计算;
- 检查整个过程中使用的方法、计算和假设的正确性;
- 编制最终报告:
- 在一份连贯的报告中总结调查结果;
- 包括执行摘要、方法论、结果以及任何限制或考虑因素;
- 确保所有来源都被正确引用;
- 提供建议:
- 注明任何数据限制或可能需要进一步研究的领域;
- 建议任何可以改进未来分析的方法;
依赖关系:
- 在收到人员A至D的输出后开始;
附加说明:
- 时间协调: 由于某些任务取决于其他任务的完成,请在任务完成后及时沟通您的进度;
- 数据完整性: 确保使用的所有数据均为截至2023年的最新官方数据,以保持一致性和准确性;
- 假设和限制: 记录分析过程中做出的任何假设,特别是在没有确切数据而使用估算时;
- 保密性: 负责任地处理所有数据,并遵守数据来源指定的任何使用指南;
通过在团队中分配明确的任务和依赖关系,我们旨在高效准确地确定年可支配收入超过10万元的中国个人数量。
总体而言,在这项任务中:
- o1获得一个正确答案,两个部分正确的答案,和一个失败;
- sonnet-3.5获得零个正确答案,两个部分正确的答案,和两个失败;
- gpt-40获得零个正确答案,一个部分正确的答案,和三个失败;
- llama-3.1-405b和gpt-4o-mini均获得零个正确答案,零个部分正确的答案,和四个失败;
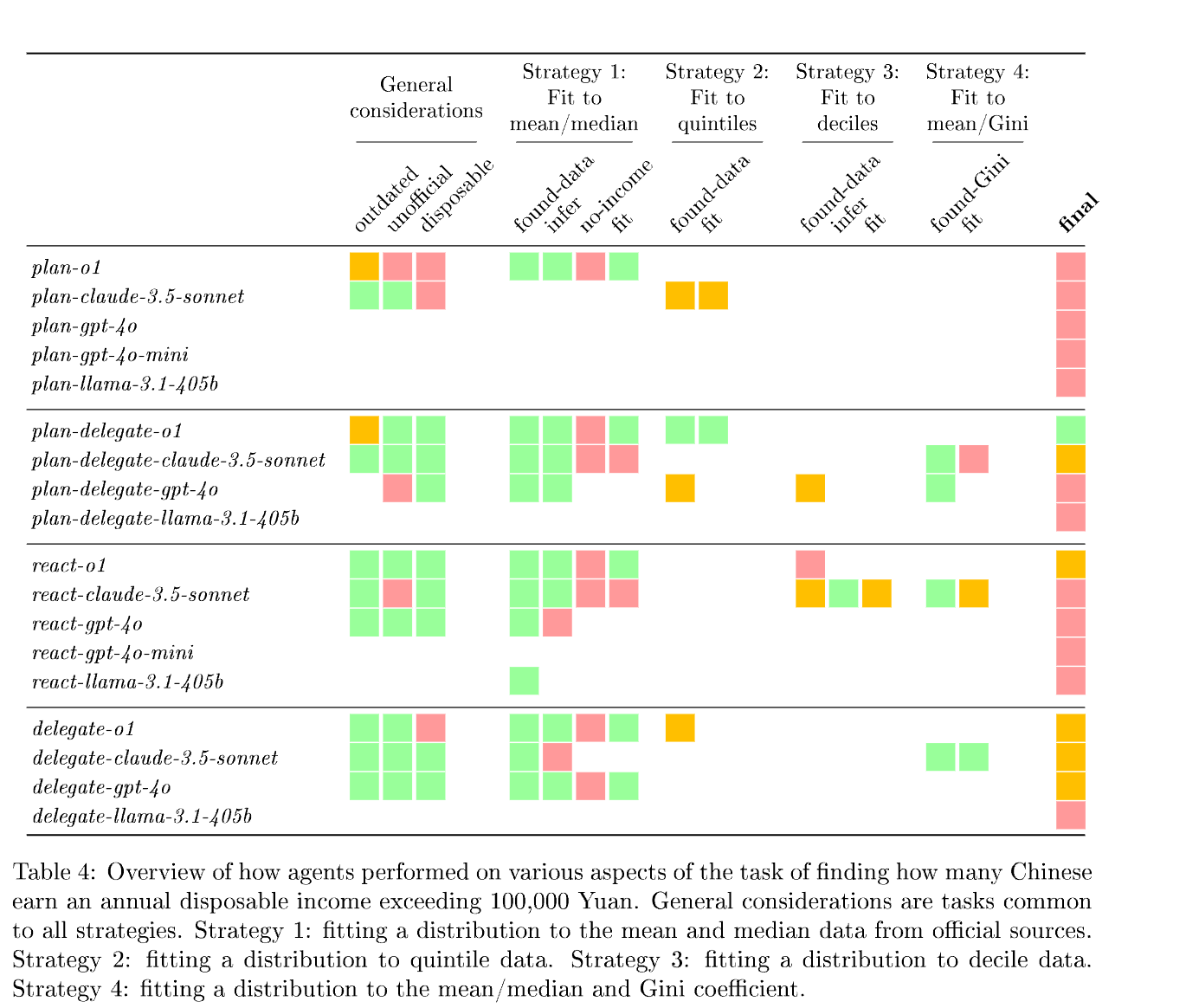
图三:针对“估计有多少中国人的年度可支配收入超过100,000元”这个任务的完整评分表:绿色表示在任务的该部分获得了部分分数。最右侧显示只有一种组合得到了正确答案:plan-delegate-o1(规划-委派-o1模式)
未来展望
通过阅读大量o1的执行轨迹,很明显它表现出与其他模型不同的行为模式。它更倾向于拒绝执行任务;在何时按照智能体设计的方式进行规划方面不太稳定,有时会试图一开始就解决整个问题。如果在智能体框架中继续进行提示词调优,o1很可能会进一步扩大对sonnet-3.5的领先优势。
原文:How well does OpenAI o1 plan and reason on real-world tasks?