Anthropic官方提示词优化指南更新稿重点详解
在Anthropic最初发布这套官方提示词优化指南的时候我做过一轮全文翻译,现在看到官方又更新了一稿,我做了一下对比,发现确实同比第一稿更完善和清晰了。特别将我觉得新版中值得重新阅读的几个重点说明一下:
如何创建有效的实证评估(Empirical Evaluations)
在定义好你的成功标准之后,下一步是设计Eval来评估LLM对这些标准的性能表现。这是提示工程循环(prompt engineering cycle)中的关键环节[1]。
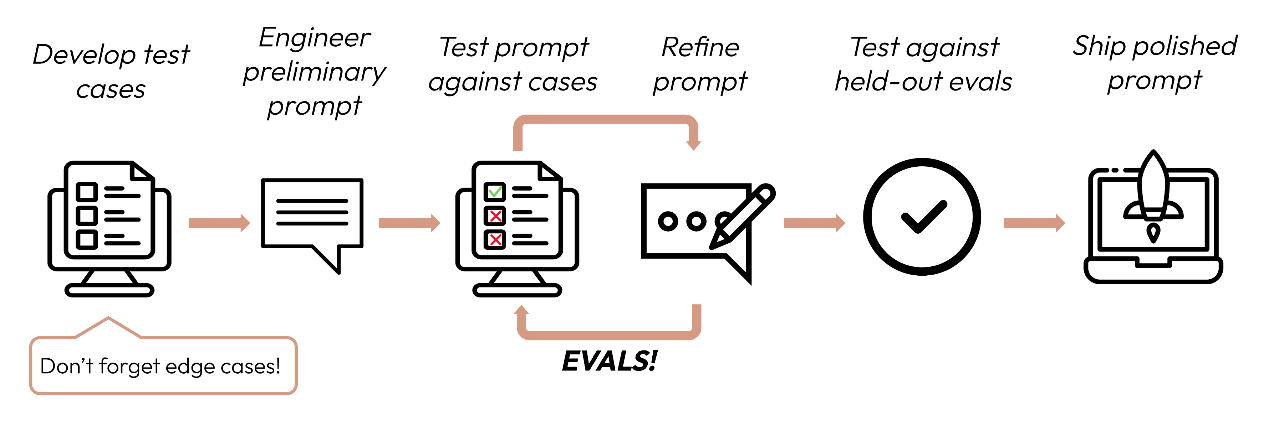
注1:这次的更新流程图中额外添加了“test against held-out evals”这个步骤,是指要使用留出集进行评估才能更公正。
Eval/测试集这两点一直是在让大模型应用落地时很容易被忽视的一环,建议一定要重视,方法论就显得格外重要了;
Eval设计的基本原则
- 要针对具体任务设计:设计能反映你真实世界任务分布的评估。别忘了考虑边缘案例(edge cases),例如:
- 不相关或不存在的输入数据;
- 过长的输入数据或用户输入;
- [Chat use cases] 糟糕的、有害的或不相关的用户输入;
- 模糊的测试案例,即使人类也难以达成评估共识;
- 尽可能自动化:构建问题以允许自动评分(例如,多选题、字符串匹配、代码评分、LLM评分);
- 优先考虑数量而非质量:更多具有稍低信号强度的自动评分问题比较少的高质量人工评分的评估要好;
Eval评分方法
在决定使用哪种方法来评分评估时,选择最快、最可靠、最具可扩展性的方法:
- 基于代码的评分:最快和最可靠,极具可扩展性,但对于需要较少基于规则刚性的更复杂判断缺乏细微差别;
- 精确匹配:output = golden_answer(输出完全等于标准答案);
- 字符串匹配:key_phrase in output(关键短语包含在输出中)
- 人工评分:最灵活和高质量,但速度慢且成本高。如果可能,应避免使用;
- 基于LLM的评分:快速且灵活,可扩展且适用于复杂判断。请首先测试以确保可靠性,然后再扩大规模;
基于大语言模型(LLM)评分的技巧
- 制定详细、清晰的评分细则:
示例:”回答应始终在第一句中提到’Acme Inc.’。如果没有,回答将自动评为’不正确’。”
注意:一个给定的用例,甚至是该用例的特定成功标准,可能需要几个评分细则进行全面评估; - 使用经验性或具体的评分标准:
例如,指示LLM只输出”正确”或”不正确”,或从1-5的范围进行判断。纯定性评估难以快速和大规模进行; - 鼓励推理过程:
要求LLM在决定评估分数之前先进行推理,然后丢弃推理过程只保留结果。这可以提高评估性能,特别是对于需要复杂判断的任务;
提示词工程综述
这部分的内容和原版变化不大,我只列出tldr和重点更新内容。
我认为提示词工程其实简单说可以分为两层:
- 最基础的是很容易被忽略的“说人话”,也就是今天假设你在给一个新人下属布置任务,能否清晰地描述出你的需求,例如对应上下文,明确要完成的任务,任务的输出具体格式要求,给一些参考样本等。在官方的提示词指南中也有这么一条黄金法则 “如果你的提示词会让人类迷惑,那么Claude也同样会。请一位朋友来阅读你的提示词,确保它们是易于理解的”;
- 第二步其实才到了“如何更好地和AI沟通”,特别典型的例子是MJ的各种魔法“咒语”,例如“close-up/medium shot/full shot”的区别。或者是针对LLM的“扮演特定角色”以及“think step by step”和“使用XML标签”等;
相信未来针对第二步的要求会随着AI智商的提升而越来越低,而针对第一步的要求将永远存在。
提示词生成器/优化器
在进行提示词工程/优化前,官方推荐大家去尝试他们的自动提示词生成器工具,以获得第一稿的提示词。不过这个工具因为只能到官方管理后台去使用,而且需要提供支付方式,所以使用门槛还挺高的… 这里推荐一个平替的方式是将官方的提示词生成器的mega-prompt自己拿来用就行,我在之前的这篇中写过 - 从Anthropic的Mega-Prompt来看提示词工程的最佳实践。
TL;DR版:Claude提示词编写技巧:
- 清晰和直接(Be clear and direct):给出清晰的指令和背景信息,引导Claude给出恰当的回应;
- 运用范例(Use examples):在你的提示词中包含范例,以展现你希望得到的输出格式或者风格;
- 设定角色(Give Claude a role):给Claude设定一个特定角色(比如专家),这样做可以增强在你的使用案例中的表现;
- 使用XML标签(Use XML tags):使用XML标签来构建提示词和回应,让信息传达更加清晰;
- 分步提示(Chain complex prompts):将复杂任务分解成小的、可管理的步骤,从而获得更好的效果;
- 引导思考(Let Claude think):鼓励Claude分步骤思考,以提升输出内容的质量;
- 预设开头(Prefill Claude’s response):用几个关键词开始Claude的回答,引导它朝着你希望的方向发展;
- 利用长上下文窗口(Long context tips):针对可以利用Claude的长上下文窗口的提示词进行优化;
如何提供清晰、明确和具体的指令
- 为 Claude 提供上下文信息:就像您在了解更多上下文信息后可能会更好地完成任务一样,Claude 在获得更多上下文信息后也会表现得更好。以下是一些上下文信息的例子:
- 任务结果将用于什么;
- 输出内容的目标受众是谁;
- 该任务属于哪个工作流程,以及在该工作流程中的位置;
- 任务的最终目标,或者成功完成任务的样子是什么;
- 明确指出您希望 Claude 执行的任务:例如,如果您只想让 Claude 输出代码而不输出其他内容,请明确说明;
- 以序列步骤的形式提供指令:使用编号列表或项目符号,这样可以更好地确保 Claude 按照您期望的方式执行任务;
如何设计提示词以激发思考
以下链式思考技巧按从最简单到最复杂的顺序排列。较简单的方法在上下文窗口中占用较少空间,但通常功能也较弱。
- 基本提示:在您的提示词中包含”Think step-by-step”(逐步思考)。缺点是并没有关于如何思考的指导(这对于特定于您的应用程序、用例或组织的任务来说尤其不理想)
示例:撰写捐赠者邮件(基本链式思考)
1 | Draft personalized emails to donors asking for contributions to this year’s Care for Kids program. |
- 引导式提示:为 Claude 的思考过程列出具体步骤。缺点是没有结构化,难以轻松剥离和分离答案与思考过程;
示例:撰写捐赠者邮件(引导式链式思考)
1 | Draft personalized emails to donors asking for contributions to this year’s Care for Kids program. |
- 结构化提示:使用 XML 标签(如 <thinking> 和 <answer>)来分离推理过程和最终答案。
示例:撰写捐赠者邮件(结构化+引导式链式思考)
1 | Draft personalized emails to donors asking for contributions to this year’s Care for Kids program. |
链式思考小提示:始终让 Claude 输出其思考过程。如果不输出思考过程,就不会发生思考!
官方的参考Prompt库
官方还专门提供了一个供参考的提示词库,包含了个人使用场景和工作使用场景的各种案例,推荐大家去看看,也在下面列出一些我个人觉得挺有趣的:
- 宇宙级打字游戏 - 在单个 HTML 文件中生成一个交互式速度打字游戏,具有横向卷轴游戏玩法和 Tailwind CSS 样式;
- 引用你的来源 - 获取有关文档内容的问题答案,并提供支持回答的相关引用;
- SQL 魔法师 - 将日常语言转化为 SQL 查询;
- 会议记录专家 - 将会议浓缩成简洁的摘要,包括讨论主题、关键要点和行动项目;
- CSV 转换器 - 将各种格式(JSON、XML 等)的数据转换为格式正确的 CSV 文件;
- 文章润色师 - 使用高级文字编辑技巧和建议来改进和提升书面内容;
- 数据结构化专家 - 将非结构化文本转换为定制的 JSON 表格;
- 评论分类专家 - 将反馈归类为预先指定的标签和类别;
- 推文情感分析师 - 检测推文背后的语气和情感;