AI论文导读 - CLASI: 通过LLM智能体实现人类水平的端到端同声传译
引言
同声传译(SiST)长期以来被视为翻译领域中最具挑战性的任务之一。尽管近年来机器翻译技术取得了巨大进步,但在实时口译这一复杂场景中,AI系统的表现仍然与人类译员有着明显差距。这篇来自字节的跨语言智能体团队提出的论文介绍了一种名为CLASI的创新方法,通过利用大语言模型(LLM)智能体,成功将机器同声传译的水平提升到了与人类相当的程度。
论文原文:Towards Achieving Human Parity on End-to-end Simultaneous Speech Translation via LLM Agent
问题背景 - 同声传译的挑战
同声传译面临着几个关键挑战:
- 实时性要求高:译员需要在听到原文的同时就开始翻译,这要求极快的反应速度和处理能力;
- 信息完整性与准确性:在有限的时间内既要保证翻译的完整性,又要确保准确性;
- 专业术语和文化差异:不同领域的专业用语和文化特定表达往往难以实时准确翻译;
- 数据稀缺:高质量的同声传译训练数据非常有限;
- 评估困难:传统的机器翻译评估指标难以准确反映同声传译的实际效果;
创新解决方案:CLASI - 跨语言AI同声传译智能体
为了应对这些挑战,研究者们提出了CLASI(Cross-Lingual Agent for Simultaneous Interpretation)方法。这是一个端到端的同声传译系统,核心是一个基于大语言模型的AI智能体。
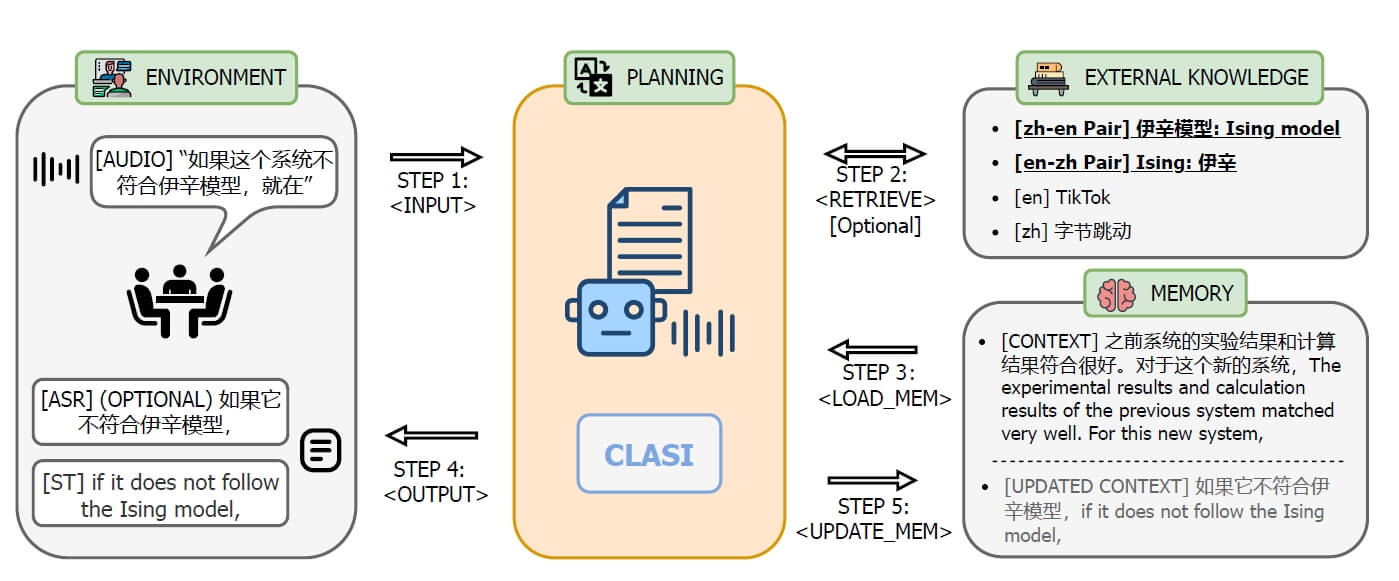
CLASI的主要创新点包括:
- 数据驱动的读写策略:
- 模仿人类译员的翻译策略,通过句法边界(如停顿、逗号、连接词等)和上下文意义,将句子分割成语义”块”;
- 通过人类译员的标注数据学习最佳的翻译时机,平衡质量和延迟;
- 多模态检索增强生成(MM-RAG):
- 引入外部知识库(存储术语和翻译对)和语音上下文记忆模块;
- 采用MM-RAG框架来实时检索相关知识,此框架利用音频编码器和文本编码器分别对外部知识数据库中的术语音频流和文本关键词进行编码,通过评分表示音频流中存在文本关键词的概率,将得分最高的术语传递给 CLASI 智能体,以此增强翻译质量和响应速度;
- 三阶段训练方法:
- 预训练:分别对LLM和音频编码器进行大规模预训练;
- 持续训练:使用合成数据对齐语音和文本模态,增强上下文学习能力;
- 微调:使用少量高质量人工标注数据进行最终调优;
- 新的评估指标 - 有效信息比例(VIP),并已开源:
- 反映实际传达的有效信息比例;
- 更好地衡量同声传译的核心目标:实时有效沟通;
研究成果
CLASI在真实场景的测试中展现出了卓越的性能:
- 在中译英任务中达到了81.3%的VIP分数,显著优于现有商用AI同传系统(得分42%);
- 成功缩小了机器翻译与人类译员之间的差距(高水平人类译员的得分大约在80%);
- 在各种复杂场景和长篇语音翻译中均表现出色;
结语
CLASI的成功不仅标志着机器同声传译技术的重大突破,也为其他复杂的实时语言处理任务提供了新的思路。这种结合LLM、多模态检索和模仿人类策略的方法,有望在更广泛的AI应用中发挥作用。