大模型实战指南 – 如何优化延迟/Latency optimization
大模型实战指南 – 如何优化延迟/Latency optimization
点评:当前大模型应用到实际商业场景中的一个主要问题是 - 虽然要做一个演示版demo的门槛大大降低,但是一旦涉及到要真正将这个产品部署到生产环境并实际为海量用户提供服务的时候,依然会有大量的工程优化工作要去做。这篇来自OpenAI官方最新更新的如何优化延迟的实战指南就是个很好的参考。而且因为最后提供的参考案例是一个客服机器人案例,只是参考相关的设计也有些实战价值。
我对全文进行了翻译并补充了更具体的注解供参考。
本文涵盖了一系列可以应用于各种大语言模型响应速度优化的核心原则,这些技巧源自与众多客户和开发人员合作中产生的最佳实践,因此无论您正在构建什么—从细粒度工作流还是端到端的聊天机器人—这些原则都会适用!
虽然具体的优化大模型延迟的技巧有很多,但我们将它们归纳为下述的七条原则,而且在最后会通过一个案例来演示如何应用这些技巧。
七大原则
- 加快token处理速度/Process tokens faster
- 生成更少的token/Generate fewer tokens
- 使用更少的输入token/Use fewer input tokens
- 减少请求次数/Make fewer requests
- 并行化处理/Parallelize
- 减少用户等待时间/Make your users wait less
- 不要默认就使LLM/Don’t default to an LLM
一. 加快token处理速度
在解决延迟问题时,推理速度/Inference speed可能是大家最先会想到的(但正如您很快会看到,它远不是唯一的)。这是指LLM处理token的实际速率,通常以TPM(每分钟token数)或TPS(每秒token数)来衡量。
影响推理速度的主要因素是模型大小—较小的模型通常运行得更快(且成本更低),如果能对小模型使用得当,其效果甚至可以胜过更大的模型。为了在使用较小模型时保持高性能,您可以尝试:
- 使用更长、更详细的提示,例如明确要求按照特定步骤来回答;
- 添加(更多)小样本案例,或者是
- 进行微调/蒸馏;
二. 生成更少的token
使用LLM时,生成token这一步几乎总是延迟最高的地方 – 根据一般经验,减少50%的输出token就能减少约50%的延迟。而具体减少输出大小的方式将取决于输出类型:
- 如果您要生成自然语言,可以直接地要求模型输出更简洁(例如要求”少于20个单词”或”非常简短”)。您还可以使用小样本案例和/或微调来教模型生成更短的响应;
- 如果您正在生成结构化输出,请尽可能最小化输出语法:缩短函数名称,省略命名参数,合并参数等;
- 最后,虽然不常见,您也可以使用max_tokens或stop_tokens来提前结束生成;
请牢记:减少一个输出token就是节省一(毫)秒!
三. 使用更少的输入token
虽然减少输入token的数量确实会降低延迟,但这通常不是一个重要因素—一般来说**将输入提示减少50%可能只会使延迟降低1-5%**,当然除非您使用真正大量的上下文(文档、图像等);
如果您正在处理大量上下文(或者您执意要榨取每一点性能提升,并且已经用尽了所有其他选择),您可以使用以下技术来减少输入token:
- 微调模型 - 以取代冗长指令/案例的需要;
- 过滤上下文输入 - 如修剪RAG结果,清理HTML等;
- 最大化共享提示前缀 - 将动态部分(例如RAG结果、历史记录等)放在提示输入的后面部分。这将使您的请求对KV缓存更加友好(大多数LLM服务提供商都用这样的架构,意味着当共享提示前缀被处理并缓存后,后续只需处理动态部分),也意味着每个请求处理的输入token数更少;
四. 减少请求次数
每次发出请求时,您都会产生一些往返延迟—这些一点点加起来可就不少了。
如果您有需要LLM执行的步骤顺序,不要为每个步骤发出一个请求,而是考虑将它们放在一次提示请求中,并在一次响应中获取它们。这样能避免额外的往返请求延迟,并还可能会降低处理多个响应的复杂性。
一种方法是在组合提示中以枚举列表的形式收集步骤,然后要求模型以JSON中的命名字段返回结果。这样您就可以轻松解析和引用每个结果!
五. 并行化
在使用LLM执行多个步骤时,并行化可能非常强大。
如果要处理的步骤之间没有严格的顺序,您可以将它们拆分为并行调用。
但是,如果步骤间存在严格顺序,您可能仍然能够利用推测执行/speculative execution。这针对一种结果比其他结果更可能出现的步骤时特别有效(例如内容审核):
- 同时启动步骤1和步骤2(例如步骤1是输入审核,步骤2是故事生成);
- 验证步骤1的结果;
- 如果步骤1的结果不符合预期(用户输入未通过审核),取消步骤2(如果需要,可以重试)
- 如果步骤1的结果符合预期,那么步骤2的执行就相当于没有增加额外的延迟!
六. 减少用户等待时间
单纯等待和观看进度发生这两者之间有很大区别—从用户体验角度来说,尽量使用后者:
- 流式传输:最有效的方法,因为它将等待时间缩短到一秒或更短。(如果在每个响应完成之前什么都看不到,ChatGPT的使用感觉会有很大不同);
- 分块:如果您的输出在显示给用户之前需要进一步处理(例如审核或者翻译),请考虑分块处理,而不是一次性全部处理。通过流式发送数据到后端,然后将处理后的分块数据发送回前端;
- 展示每一步:如果您的程序需要执行多个步骤或使用工具,请向用户展示出来(而不是隐藏这些过程步骤);
- 加载状态:虽然这些加载状态主要是心理上的安慰,但展示旋转图标(spinners)和进度条(progress bars)确实可以极大地改善用户体验;
七. 不要默认就使用LLM
LLM非常全能和强大,因此有时会让我们忽视了其实有更适合/更快的传统方法存在,例如:
- 硬编码:如果您的输出受到高度约束,可能不需要LLM来生成它。操作确认、拒绝消息和标准输入请求都是硬编码的理想选择。(您甚至可以使用古老的方法为每个情况提供一些变量支持。)
- 预计算:如果您的输入受限(例如类别选择),您可以根据可能的输入组合预先生成响应并存储,用户请求时直接从预先生成的响应中获取;
- 利用UI:有时最好使用经典的、定制的UI组件,而不是LLM生成的文本来传达汇总的指标、报告或搜索结果;
- 传统优化技术:LLM应用仍然是一个应用程序,传统的优化技术(二分搜索、缓存、哈希映射和runtime复杂性等)在LLM世界中仍然有用。
延迟优化案例
现在我们来看一个具体的优化案例 - 我们将分析一个虚构的客服机器人的架构和提示,这些提示来源于真实的生产应用。架构和提示部分提供了相关背景信息,而分析和优化部分将逐步介绍如何来优化延迟。
架构和提示
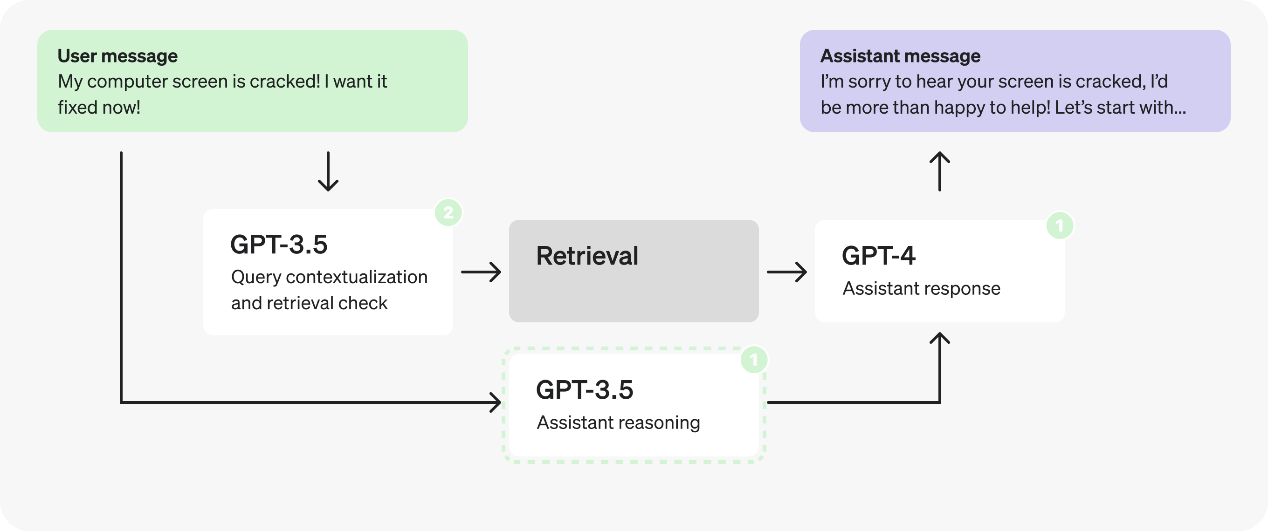
以下是一个虚构的客服机器人的初始架构
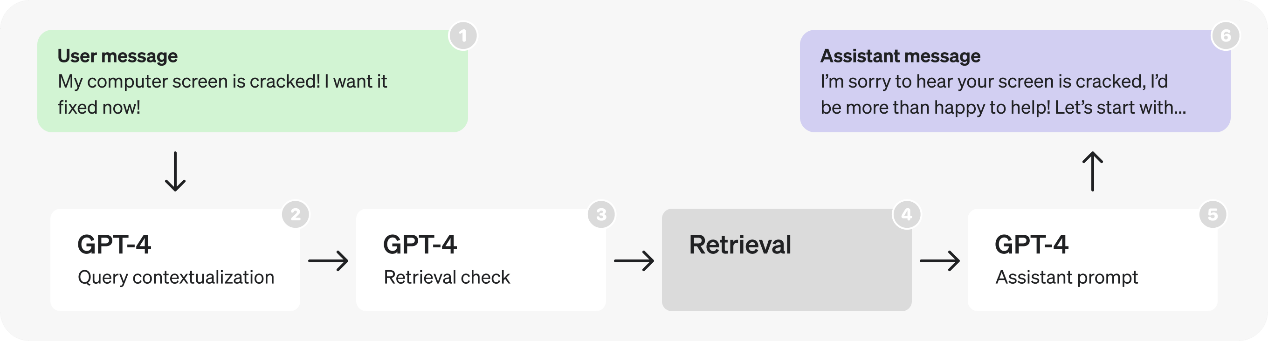
上图的流程描述了以下六个步骤:
- 用户在对话中发送消息;
- 最后一条消息被转化为一个独立查询;
- 我们确定是否需要额外的(检索到的)信息来响应该查询;
- 执行检索,生成搜索结果;
- 助手根据用户的查询和搜索结果进行推理,并生成响应;
- 响应发送回用户;
以下是相关步骤中使用的提示词。虽然这些提示只是虚构和简化的,但它们的结构和措辞与生产应用中看到的其实很类似。
查询情境化提示
将用户的查询改写为一个独立的搜索查询
SYSTEM
1 | Given the previous conversation, re-write the last user query so it contains all necessary context. |
USER
1 | [JSON-formatted input conversation here] |
解读:
这个提示的目的是将用户在对话中的最后一个查询重新改写为包含所有必要上下文的独立查询,以便于系统能够理解并处理这个查询:
- 读取对话历史:系统会参照之前的对话上下文,例如上面例子中用户是在问关于退货政策的问题;
- 识别用户的最后一个查询:从对话中提取用户的最后一个问题或请求,例如这里是最后问了一个关于退货政策的覆盖期的问题;
- 添加必要的上下文:将之前的对话信息整合到用户的最后一个查询中,使其成为一个完整的查询;
- 生成新的查询:生成一个包含所有必要上下文的独立查询,确保在没有之前对话的情况下也能理解这个查询。例如这里将用户问的”它的覆盖期是多长?”改写成了”退货政策的覆盖期是多长?”;
检索检查提示
确定查询是否需要进行检索才能响应
SYSTEM
1 | Given a user query, determine whether it requires doing a realtime lookup to respond to. |
USER
1 | [input user query here] |
解读:
这个提示的目的是判断用户的查询是否需要实时查找(例如数据库查询或外部数据源检索)来得到回答:
- 读取用户查询:系统会获取用户当前的查询内容;
- 分析查询类型:系统分析该查询是否需要访问外部数据或系统进行实时查找。上面例子中,用户问“我如何在30天后退货?”。这种查询通常需要访问系统中的退货政策数据,因此需要进行实时查找;而如果用户只是说了“谢谢你!”。这种查询不需要任何额外的数据查找;
- 返回判断结果:系统返回一个布尔值(true/false),指示是否需要进行实时查找;
助手提示
填写 JSON 字段,通过预定义的一系列步骤,根据用户对话和相关检索信息进行推理,生成最终响应
SYSTEM
1 | You are a helpful customer service bot. Use the result JSON to reason about each user query - use the retrieved context. |
USER
1 | # Relevant Information |
USER
1 | [input user query here] |
解读:
这个提示的目的是帮助客服机器人通过预定义的步骤和检索到的上下文信息,填充 JSON 字段,从而生成最终的响应:
- 读取用户查询:系统会获取当前用户的查询内容。
- 使用检索上下文:利用先前检索到的上下文信息来辅助理解和响应用户的查询。
- 填充 JSON 字段:根据查询和上下文信息,填充 JSON 的各个字段。
- 生成最终响应:根据填充的 JSON 字段,生成对用户查询的最终响应。
相关字段解释:
- message_is_conversation_continuation:指示当前消息是否是对话的一部分。
- 案例中为 “True”,表示这是对话的延续。
- number_of_messages_in_conversation_so_far:记录对话中的消息数量。
- 案例中为 “1”,表示这是对话中的第一条消息。
- user_sentiment:用户情绪,反映用户的情感状态。
- 案例中为 “Aggravated”,表示用户感到愤怒。
- query_type:查询类型,分类用户的问题类型。
- 案例中为 “Hardware Issue”,表示这是一个硬件问题。
- response_tone:回应语气,指示助手应该采用的回应语气。
- 案例中为 “Validating and solution-oriented”,表示助手应该采用验证性的和解决问题导向的语气。
- response_requirements:回应要求,指示助手需要在回应中包含哪些内容。
- 案例中为 “Propose options for repair or replacement.”,表示助手需要提议修理或更换的选项。
- user_requesting_to_talk_to_human:指示用户是否请求与人工客服对话。
- 案例中为 “False”,表示用户没有请求与人工客服对话。
- enough_information_in_context:指示当前上下文信息是否足够回答用户查询。
- 案例中为 “True”,表示上下文信息足够。
- response:助手的实际回应内容。
- 案例中为 “…”,表示实际的回应内容将在此生成。
分析和优化
第 1 部分:检视检索提示
这个流程中,首先引人注目的就是连续的GPT-4调用 — 很有可能存在潜在的低效问题,通常可以通过单次调用或并行调用来替代。在这个案例中,由于检索检查需要情境化的查询,我们可以将它们合并为一个提示,以减少请求次数。
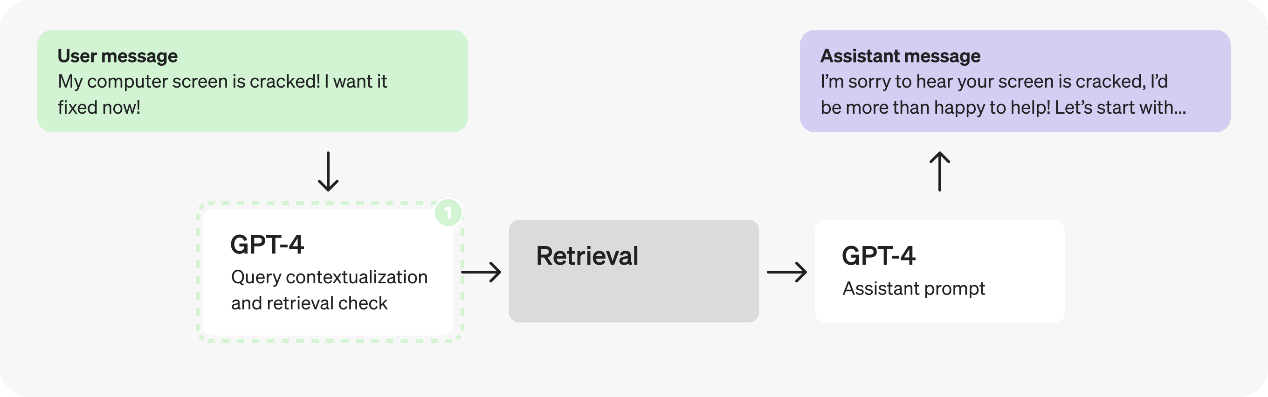
合并的查询情境化和检索检查提示
有什么变化?之前,我们有一个提示用于重写查询,另一个用于确定是否需要进行检索查找。现在,这个合并的提示同时完成这两项任务。特别注意提示第一行中的更新指令,以及更新后的输出 JSON:
1 | { |
SYSTEM
1 | Given the previous conversation, re-write the last user query so it contains all necessary context. Then, determine whether the full request requires doing a realtime lookup to respond to. |
USER
1 | [JSON-formatted input conversation here] |
解读:
这个更新后的提示将之前的两个步骤合并为一个步骤,以提高效率和响应速度:
- 读取对话历史:系统会参照之前的对话内容;*
- 识别用户的最后一个查询:从对话中提取用户的最后一个问题或请求;*
- 添加必要的上下文:将之前的对话信息整合到用户的最后一个查询中,使其成为一个完整的查询;*
- 生成新的查询:生成一个包含所有必要上下文的独立查询,确保在没有之前对话的情况下也能理解这个查询;*
- 判断是否需要实时查找:分析生成的查询是否需要进行实时查找(例如数据库查询或外部数据源检索);*
- 返回结果:以 JSON 格式返回重写后的查询和是否需要进行实时查找的布尔值;
事实上,添加上下文和确定是否需要检索是非常简单且明确的任务,因此我们可以考虑使用一个较小的、经过微调的模型,例如尝试切换到GPT-3.5使我们可以更快地处理token。
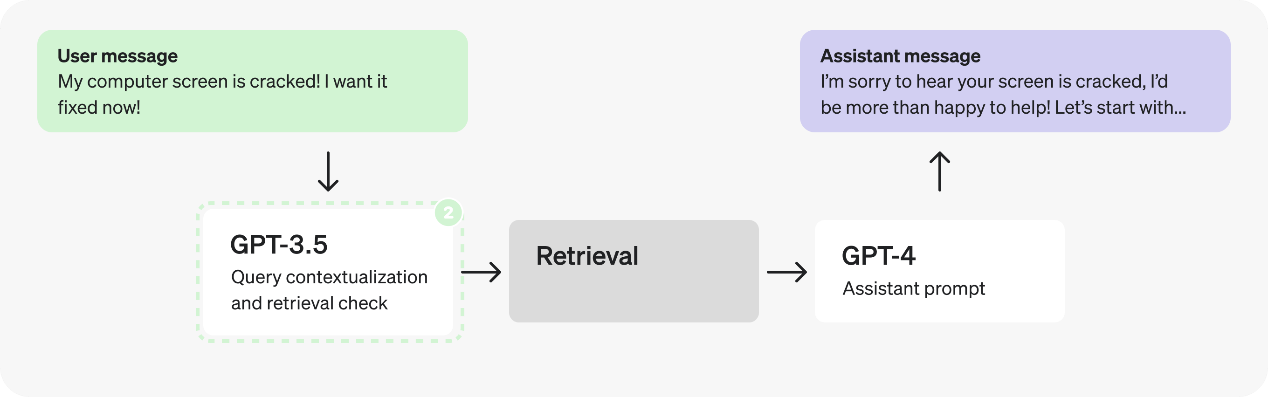
第二部分:分析助手提示
再来看看助手提示 - 在填写 JSON 字段时,似乎有许多独立不同的步骤 — 这可能意味着有并行处理的优化空间。
然而,假设我们进行了测试后,发现如果将推理步骤分割到 JSON 中会导致响应质量下降,因此我们需要探索其他解决方案。
我们能否使用微调后的 GPT-3.5 代替 GPT-4? 也许可以,但通常情况下,助手的开放式响应最好留给GPT-4,以便更好地处理更多样的情况。尽管如此,推理步骤本身可能并不都需要 GPT-4 级别的推理来完成。明确且范围有限的步骤使它们成为微调的良好候选对象 – 以之前的助理提示来看,除了最后一条外,很可能都可以用微调后的3.5来替代。
1 | { |
这带来了一个值得权衡的可能性 - 是让所有请求都由 GPT-4 完成,还是将其分为两个顺序请求,并使用 GPT-3.5 处理除最终响应外的所有内容?第一个选项可以减少请求次数,但第二个选项可能让我们更快地处理token。
如同许多优化权衡一样,答案将取决于具体细节。例如:
- 响应中的token比例与其他字段的比例;
- 通过更快处理大多数字段所带来的平均延迟减少;
- 执行两个请求而不是一个请求所带来的平均延迟增加;
结论会因具体情况而异,最佳决策的方法是通过生产案例进行测试。假设我们的测试结果表明将提示分为两个部分以更快地处理token是有利的,优化后的新流程图如下。
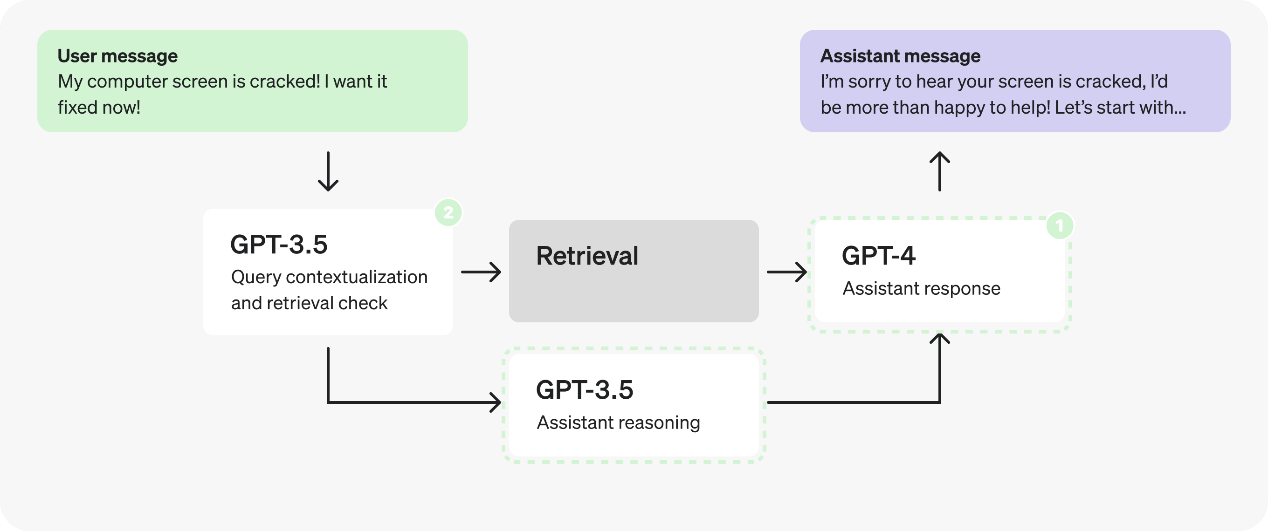
注意这里我们将在第二个提示中把 response 和 enough_information_in_context 组合在一起,以避免将检索到的上下文传递给两个新提示。
助手提示 - 推理
这个提示将由 GPT-3.5来处理,并可以在精心挑选的案例上进行微调。
有什么变化?- “enough_information_in_context”和“response”字段被移除了(模型不再需要判断上下文信息是否足够,也不需要生成实际的响应内容。这可以减少复杂性和错误率),检索结果不再加载到这个提示中(模型在生成这些字段时不依赖外部数据源。这可以减少交互的复杂性,并使模型更专注于对话内容本身的分析)。
SYSTEM
1 | You are a helpful customer service bot. Based on the previous conversation, respond in a JSON to determine the required fields. |
解读 - 更新后的提示步骤:
- 读取对话历史:系统会参照之前的对话内容;
- 识别用户的最后一个查询:从对话中提取用户的最后一个问题或请求;
- 分析对话和查询:根据对话的上下文和用户的情感状态,填充 JSON 字段;
- 返回 JSON:生成一个包含所有必要字段的 JSON 响应;
上面的例子中,当用户说: “我的电脑屏幕裂了!”,系统会根据上述步骤来生成一段JSON(相关字段的解释参考前文,输出内容参考上面的提示案例)
助手提示 - 响应
这个提示将由 GPT-4 处理,并接收上一步提示中确定的推理步骤以及检索结果。
有什么变化?- 除了“enough_information_in_context”和“response”外,所有步骤都被移除了。此外,之前作为输出填写的 JSON 将被传递到这个提示中。
SYSTEM
1 | You are a helpful customer service bot. Use the retrieved context, as well as these pre-classified fields, to respond to the user's query. |
USER
1 | # Relevant Information |
解读 - 更新后的提示步骤:
- 接收推理字段:系统会接收由之前的 GPT-3.5 提示生成的推理字段 JSON;
- 检索相关信息:将相关的检索上下文信息作为输入传递;
- 确定上下文信息是否足够:根据检索上下文和推理字段,判断上下文信息是否足够;
- 生成最终响应:根据所有提供的信息生成最终的响应;
按照上面的例子,当用户说: “我的电脑屏幕裂了!”后,系统在检索到了保修、线下服务中心地址和客服联系信息等相关信息后,最终生成的回答可能是这样 - “很抱歉听到您的电脑屏幕裂了。您可以将电脑送到最近的服务中心进行屏幕维修或更换。以下是您附近的服务中心信息… 如果您的电脑仍在保修期内,屏幕维修可能在保修范围内。请在此处检查您的保修状态… 如需更多帮助,您可以联系我们的支持团队…”
事实上,由于推理提示现在不依赖于检索到的上下文,我们可以将其并行处理,并与检索提示同时启动。
第 3 部分: 优化结构化输出
让我们再看看推理提示,仔细观察推理 JSON,您可能会注意到字段名称本身相当长。
1 | { |
通过将字段名称缩短,并将解释移到注释中,我们可以减少生成的token数量。
1 | { |
这个小小的变化减少了 19 个输出token。在 GPT-3.5 上可能只带来几毫秒的改进,但在 GPT-4 上则可能节省多达一秒的时间。

可以想象,这对较大模型的输出可能会产生显著的影响。
我们可以进一步将 JSON 字段简化为单个字符,或者将所有内容放入一个数组中,但这可能会影响响应质量。最好的方法仍然是通过测试来确定。
案例总结
让我们回顾一下我们为这个客服机器人实施的延迟优化措施:
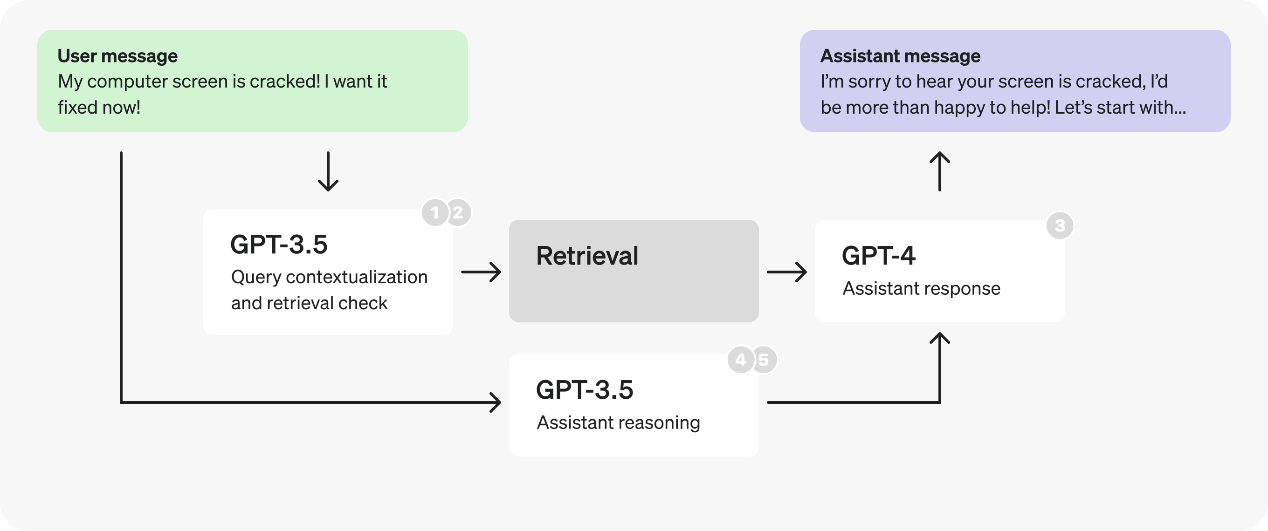
- 合并查询情境化和检索检查步骤,以减少请求次数;
- 对于新的提示,切换到较小的、经过微调的 GPT-3.5,以更快地处理token;
- 将助手提示分为两部分,对推理部分使用较小的、经过微调的 GPT-3.5,再次以更快地处理token;
- 并行化检索检查和推理步骤;
- 缩短推理字段名称并将注释移到提示中,以减少生成的token数量;
原文:https://platform.openai.com/docs/guides/latency-optimization/example