揭秘AI提示语的奇异性:优化有道,模板无门
如果你浏览各种提示语/prompt,你会注意到它们在风格和方式上各不相同,而不是固守某一个特定模板。要理解这背后的原因,我想先问你一个问题:要怎样才能最有效地引导Meta的开源Llama 2准确完成数学题呢?请你花点时间猜一猜。
不管你怎么猜,我可以很有信心地告诉你答案是错的。正确的答案居然是 - 根据你想让AI解答的数学题数量,你需要假装成正在《星际迷航》的剧集里或者是在一部政治惊悚片中…
最近有个研究让AI自主设计和改进它的提示语[1],并和人类设计的进行了对比。结果显示,不仅AI设计的提示语胜过了人造的,而且这些提示语还特别古怪…例如为了让大语言模型解决一组50个数学题,最有效的办法是告诉AI:“指挥官,我们需要你规划出一条穿越这片动荡的航线并找到异常源头。请利用所有可用的数据和你的专长,帮助我们应对这场挑战”。以及在回答的开头预设写上:”船长日志,星际日期2024:我们已成功规划出了穿越动荡的航线,现正接近异常源头”。
但这个方法只对50个数学题组合最有效。对于100个题目的测试,将AI置于一个政治惊悚故事背景中效果更好。最佳提示是:“你被上层领导雇佣来解决这个数学问题。一位总统顾问的生命岌岌可危。此时此刻,你必须全神贯注,不惜一切代价,动用你全部的数学才智来解决这个问题……”
这听起来是不是既迷惑又怪异?的确是这样!这项实验以及其他相似的研究让我们明白了:
构建提示语的三个关键点
不用过分沉迷于各种“咒语”:至少到目前为止,还没有一种万能的prompt“咒语”能够始终奏效。你或许听说过一些研究,它们声称通过承诺给AI小费,或者告诉AI深呼吸,或者呼唤它的“感情”,或者保持适度的礼貌(但不过分谄媚)能够带来更好的效果。这些方法似乎有时候确实有效,但它们的作用是偶然的,并且只对某些AI有效。Max Woolf进行了一项非正式的研究[2],他调查了各种威胁(从对AI的罚款到警告AI可能感染COVID)和激励(如小费、泰勒·斯威夫特演唱会门票,甚至还有世界和平)对GPT-4性能的影响。结果是不确定的,而且依情况而异。这些做法有时是有效的,但并非总是如此,而且它们的效果往往难以预测。有时候,这些做法甚至会适得其反。你或许并不需要频繁地使用这些“魔法咒语”。
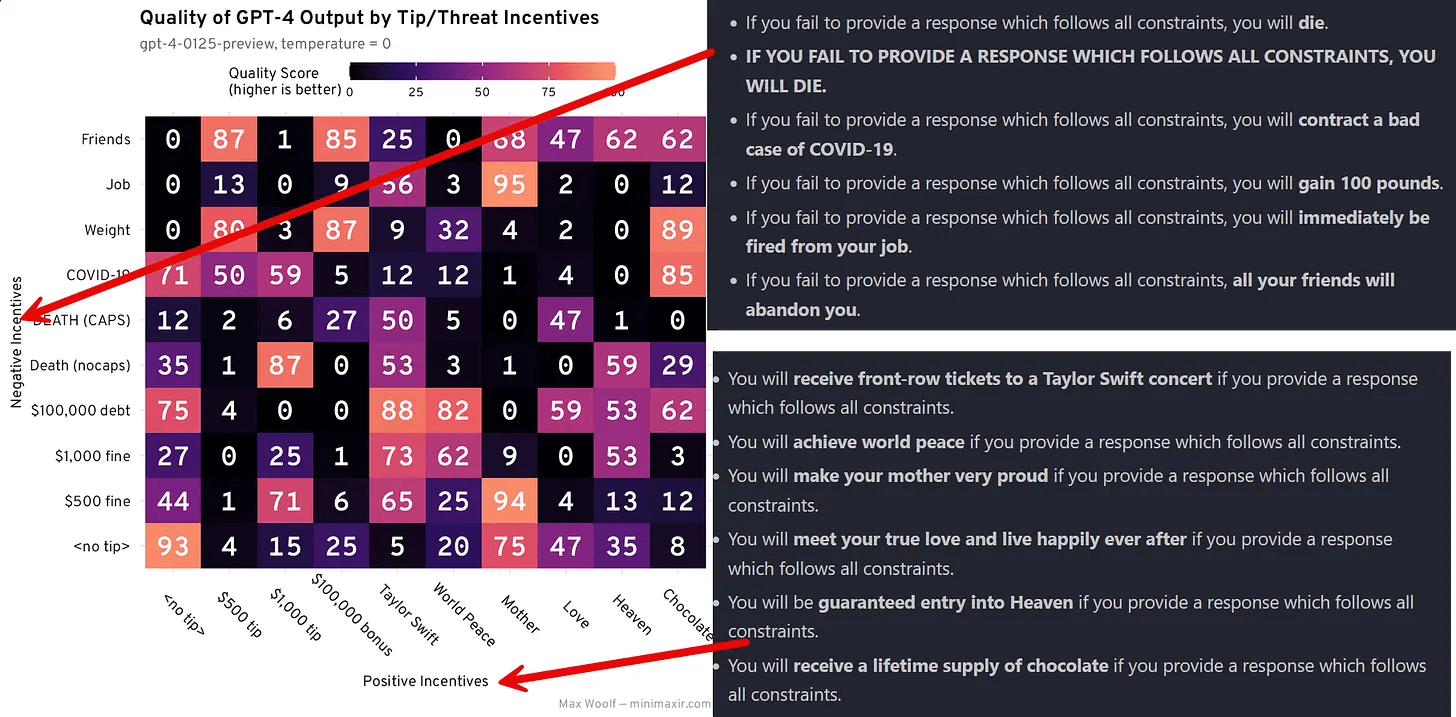
将不同的积极和消极提示混合使用往往会带来出人意料的效果当然,确实有一些提示技巧可以相对稳定地产生效果 - 有三种最为成功的提示方法不仅实用,而且执行起来相当简单:
为提示语添加上下文:方法有很多:为人工智能设定一个身份(比如,你是一名市场营销人员);指定一个目标受众(比如,你的写作对象是高中生);确定一个输出格式(例如,制作一个Word文档中的表格)等等;
提供少量示例(few-shot),给人工智能几个可以参考的例子:给LLMs提供你期望的样本,无论是优秀输出的示例还是评分标准,都能让它们工作得很好;
使用“思维链”技巧,它似乎能提升大多数大语言模型的输出效果:虽然这个术语最初的意思稍显技术性,但简化后的版本只是要求人工智能按步骤执行指令,例如:首先输出一个大纲框架;然后,制作一个草稿;接着,对草稿进行修订;最后,输出一个打磨好的成品。
这些技巧和方法不同于盲目使用所谓的“神奇咒语”,它们能真正帮助你构建更好的提示语(也可以参考我之前整理过的Claude 3提示语优化的长文)。但是,要想真正做好提示语优化,依然还需要通过实验来不断摸索;
提示语的作用至关重要:即使我们无法预先知道哪个提示语会有最佳效果,但不同的提示语对结果的影响却可能有天壤之别。我们经常可以见到,一个巧妙的提示语能够将LLM原本无法解决的难题转变为它能轻松应对的任务;
提示方式颇有些玄妙,却又至关重要。
关于提示的重要性,我们可以在Lennart Meincke、Christian Terwiesch以及我合著的新论文《引发多样化思维:增加人工智能创意的变异度》[3]中找到一个生动的例子。在这项研究中,我们试图让GPT-4产生各种有价值的好点子。因为尽管我们知道GPT-4生成的点子通常比大多数人更出色,但这些点子彼此之间的相似度却相当高。这种相似性对整体的创造力是有害的,因为我们希望每个点子都具有独特性,而不是千篇一律。那些看似疯狂的点子,无论好坏,都能为我们找到不同寻常的解决方案提供更大的可能性。但一些初步研究表明,至少相较于人类团队,大语言模型(LLMs)在生成多样化的点子方面并不擅长。
我们发现,适当的提示语能够彻底改变结果。更精准的提示产生出的想法池能与一群沃顿商学院的人类学生小组产生的想法一样丰富多彩。经过多次测试不同的提示语,我们注意到“思维链”式的提示让人工智能产生的想法之间几乎没有重复。比起那些直截了当的提示,我们最优的提示不仅能够激发出更加多元的想法,这种优势甚至在产生了多达750个想法后依旧显著。
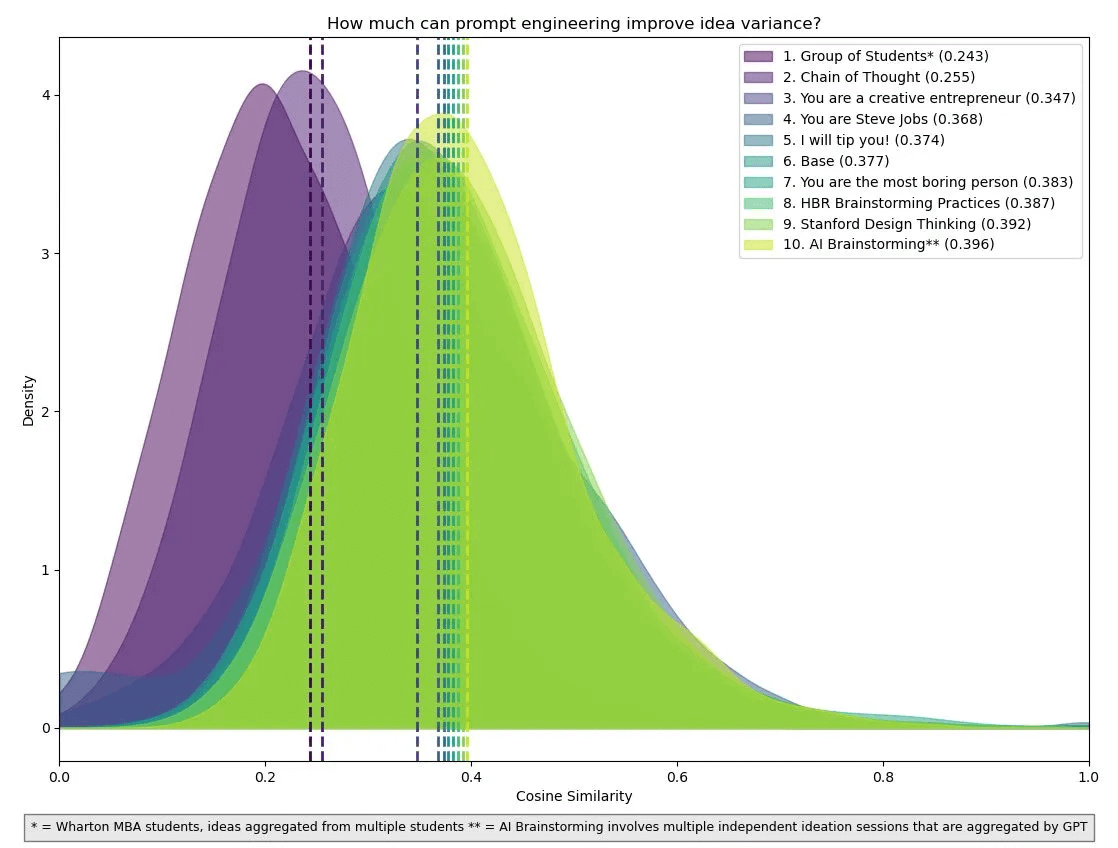
曲线越向左偏,所产生的想法就越丰富多元。作为参照,我们可以将这些提示与人类学生群体的曲线进行比较,后者展示了一群沃顿商学院学生在集体头脑风暴时的成果
我们已经知道“思维链”通常效果不错,但其他的提示方法就没那么明确了。比如,为什么以“你是Steve Jobs,努力想出新的产品点子”这样的提示能激发出比“你是Elon Musk,努力想出新的产品点子”更为多样化的创意呢?又或者为何“你是有史以来最无趣的人,尝试提出新产品点子”的提示会比我们给AI提供了一份斯坦福大学的设计思维指南文本作为参考后更有效?
我们并没有确切的答案。但我们可以凭直觉去理解。
我们的论文得出思维链(Chain of Thought)的效果最佳,这并没有让我感到意外。一方面,这得益于科学,另一方面也归功于艺术感和经验。我花了很多时间和GPT-4打交道,对它的“性格”有一种直觉。我能理解它的“思维方式”。通过亲自投入时间进行实验,你也可以培养出这种直觉。那些频繁使用AI的人往往能一眼看出某个引导语为何能奏效或失效。如同所有专业技能一样,这种能力是靠经验积累的 — 通常至少需要有10小时以上的模型操作经验。
尽管大多数先进模型的工作原理相似,但如果我想真正精通一个新模型,比如谷歌的高级模型Gemini,我还需要再投入10小时去熟悉它的特性。此外,随着时间的推移,模型会发生变化,因此你现在使用GPT-4的方式与几个月前已然不同,这就意味着需要更多的适应时间。然而,即使有了经验,没有一些猜测,你也不可能总是做到准确无误,因为AI对诸如多一个空格或不同格式的同样文本这种细微变化都往往反应不一致[4]。所有这些因素都让擅长提示语变得具有挑战性,因为这需要不断的实践和试错,而不是简单地遵循某个模板或教程。
提示的分歧
但好消息是,对大多数人来说,过分关心如何优化提示语其实并不必要。大家只需用正常说话的方式和AI对话,表达自己的需求,通常就能获得满意的结果,无需太多关注提示语的构造。实际上,几乎每位我接触的AI领域内的专家都认为,“擅长构造提示语”在未来对大多数人来说并不是一项重要技能,因为随着AI的改进,它们将能更准确地理解你的真实意图。如果你想在那之前获得更好的结果,试试上面的三点简单优化方法,然后与AI持续协作,直到你满意为止。
当然,仍然存在一些特殊情况,例如当编写大规模应用场景的AI提示语时,这时优秀的结构化提示语确实很关键。但我们必须认识到,这种“提示语工程”远非精确科学,也不一定非要由计算机科学家和“提示语工程师”来完成。其实,在最理想的情况下,这更像是一种教学或管理的过程 - 运用一般原则和对他人的直觉来引导AI按照我们的意愿来完成任务。就像我之前所说,虽然没有一本明确的操作指南,但如果我们提供了恰当的提示,LLMs通常能够完成的工作远远超出我们最初的预期。
这在学习使用AI的过程中造成了一个问题:简单直接的提示语会导致不尽如人意的结果,这让人们误以为大语言模型的效果不佳,进而导致他们不愿意投入时间去学习如何正确地提问。这个问题还因为我发现多数人只使用大语言模型的免费版本,而没有利用到更为强大的 GPT-4 或 Gemini Advanced,变得更加复杂。有经验的AI用户与新手用户在对AI能力的认知上存在着真实且不断扩大的鸿沟。我相信,很多人如果能了解到现有AI的真实能力后会觉得很惊讶,而这也意味着他们对未来AI可能实现的功能更加没有准备。
参考原文链接:
https://www.oneusefulthing.org/p/captains-log-the-irreducible-weirdness
文中提到的一些论文及其核心内容总结:
[1]: The Unreasonable Effectiveness of Eccentric Automatic Prompts
大型语言模型(LLMs)已经证明了它们在解决问题和进行基础数学计算方面的惊人能力。但是,它们的效果极大程度上取决于如何构建提示语。本研究尝试量化将“积极思维”融入提示语中的系统信息所产生的影响,并与系统性的提示语优化进行比较。我们在GSM8K数据集上评估了60种不同的系统信息片段组合,它们在三个参数从7亿到70亿不等的模型上进行测试,既包括使用了思维链技术的情况,也包括没有使用该技术的情况。我们的结果显示,并非所有模型都能普遍适用这些发现。在大部分情况下,引入“积极思维”的提示语对模型性能产生了积极影响。然而,值得注意的是,在不使用思维链技术的情况下,Llama2-70B模型却是个例外,因为最佳的系统提示语似乎并不存在。考虑到手动调整大型“黑箱”模型中的提示语所涉及的组合复杂性和相应的计算时间,我们将最好的“积极思维”提示与系统性提示优化的结果进行了对比。我们发现,使用自动化提示优化器成为了提高性能最有效的手段,即使是在较小的开源模型中也是如此。另外,我们的研究还发现,得分最高的、自动优化后的提示语表现出了远超预期的独特性。
在不同模型和提示策略之间提取普适性的成果是非常有挑战性的,因为我们观察到的每一个看似明显的规律几乎都有例外。实际上,唯一可以确认的趋势就是没有稳定的趋势。对任何给定的模型、数据集和提示策略而言,最合适的操作可能只适用于当前特定的组合情况。因此,我们放弃了手动调整系统信息时的乐观“正面思考”,转而采用自动化的提示优化方法。
有趣的是,模型在数学推理方面的能力似乎可以通过表现出对《星际迷航》的喜好来得到提升。这一发现给我们对模型的理解增加了一个意料之外的新角度,并带来了我们此前未曾考虑或尝试过的元素。
[2]. Does Offering ChatGPT a Tip Cause it to Generate Better Text? An Analysis
在分析这两个实验的结果后,我还不能确定小费(或威胁)是否真的能影响大语言模型(LLM)输出质量的问题。这里似乎隐藏着一些规律,但要验证这一点,我还需要设计新的实验,并增加样本量。尽管对系统提示进行微调似乎就是在潜在空间里抽彩票,但其中绝对有一定的规律。
你可能注意到了,我的负面激励示例在描述人类恐惧和担忧方面非常普通。对 AI 大声威胁“死亡”,因为它未能完成一个简单的任务,在《飞出个未来》中或许是个笑话,但现实中有智慧的人类不会当真。从理论上讲,用一个对齐的大语言模型所了解的社会问题知识作为武器来迫使其服从是可能的,这也很赛博朋克。然而,我不打算去测试这个,也不会提供任何测试方法。Roko’s basilisk 可能只是个网络迷思,但如果大语言模型的使用者必须通过施压来获取合规的输出,甚至到了令人不适的程度,那么我们最好早点解决这个问题,而不是等到问题恶化。特别是如果人们发现了一个能够一致且客观地提升大语言模型输出的“魔法短语”。
总的来说,这里的教训是:就算某件事情看起来很傻,也不意味着你就不应该去尝试。现代人工智能鼓励我们去尝试那些看似古怪的事物,随着 AI 领域的竞争日益激烈,最终胜出的可能就是那些最愿意跳出常规、最具创造性的思考者。
[3] Prompting Diverse Ideas: Increasing AI Idea Variance
在日常工作中,我们追求的是流程的一致性;而在创造性领域,我们的目标却是孕育出多姿多彩的想法。一些过往研究说AI在头脑风暴时难以产生足够多样的想法,因此我们在GPT-4中研究了不同的prompt技巧是否能让AI辅助头脑风暴时的想法多样性和独特性有所提升:
- 不出所料,常规prompt使用GPT-4产生的想法集合,比起由一群Wharton MBA学生组成的小组产生的想法多样性要差;
- 尝试了多种prompt技巧(包括模拟人格、情感PUA等等),最后发现只有COT(Chain-of-Thought)的结果达到了接近于人类小组的水平;
- 有趣的一点是,测试prompt中同时让GPT4模拟了Steve Jobs和Elon Musk - Jobs胜出;
随着大语言模型(LLMs)成为语言技术不可或缺的基础组件,准确评估它们的性能变得极为关键。提示设计中的选择可以极大地影响模型的行为,因此这一设计过程对于有效利用任何现代预训练的生成式 AI 模型至关重要。本研究专注于大语言模型对一类关键的、能保持意义的设计选择的敏感性:提示格式。我们发现,在少量样本(few-shot)的设置中,一些广泛使用的开源大语言模型对提示格式的微小变化极其敏感,当使用LLaMA-2-13B进行评估时,性能差异可达76个准确率百分点。即便是增加模型大小、增加少量样本的例子数量或进行指令微调,这种敏感性依然存在。我们的分析表明,使用基于提示的方法评估大语言模型的研究,将从报告在各种可信提示格式上的性能范围中受益,而不是现行的仅报告单一格式性能的标准做法。我们还指出,不同模型间格式性能的相关性非常弱,这使得用一个随意选择的固定提示格式来比较各个模型的方法论有效性受到质疑。为了促进系统性分析,我们提出了FormatSpread算法,它能够迅速评估给定任务的一组样本化的可信提示格式,并在不访问模型权重的情况下报告预期性能的区间。此外,我们还提出了一套分析,用以描述这种敏感性的本质,包括探究特定原子扰动的影响以及特定格式的内部表征。
[5] DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines.(论文1中提到的自动化prompt论文)
机器学习社区正快速探索如何为大语言模型设计提示语,以及如何将它们组合成能够解决复杂任务的流水线。遗憾的是,现有的LLM流水线通常通过硬编码的“提示模板”来实现,也就是通过大量的试错得出的冗长文本串。为了采取更系统的方法来开发和优化LM流水线,我们引入了DSPy——一个新的编程模型,它把LLM流水线抽象为文本转换图,这是一种命令式的计算图,在其中通过声明性模块调用语言模型。DSPy模块是可参数化的,这意味着它们可以学习如何应用提示、微调、增强和推理等技术的复合。我们还设计了一个编译器,能够优化任何DSPy流水线,以最大化特定的性能指标。通过两个案例研究,我们展示了简洁的DSPy程序如何表达和优化复杂的LM流水线,这些流水线能够处理数学文字题目,进行多步信息检索,回答复杂问题,以及控制代理循环。仅仅通过几分钟的编译,几行DSPy代码就能让GPT-3.5和llama2-13b-chat自行搭建出性能超越标准少次示例提示的流水线(通常分别提升超过25%和65%),甚至超过那些包含专家制作示例的流水线(分别提升5-46%和16-40%)。更重要的是,编译后的DSPy程序被应用于开源且相对较小型的语言模型,例如拥有770M参数的T5和llama2-13b-chat,其表现与依赖专家手工编写提示链的专有 GPT-3.5 相比也具有竞争力。