懒人版大语言模型入门 - 整理自Andrej Karpathy的最新分享
说起AI圈的“网红”,Andrej Karpathy是大家很熟悉的名字,他不仅是OPENAI的创始成员,也曾经担任特斯拉的AI总监长达五年。他最近做了一个关于大模型的分享,我将其内容浓缩整理成为一个太长不看/TLDR版,正好为迟些要主讲的内部大模型培训做个准备,希望能让没有技术基础的同学们也能了解大模型是什么和大模型的发展方向这两个重要的议题。
第一部分:大模型是什么?
- 简单来说,一个大语言模型其实只需要两个文件!以Meta发布的Llama2 70B模型为例,你的笔记本电脑上只需要下面这两个文件就能在本地跑起来:一个包含这700亿神经网络参数的文件(140GB),以及一段运行这些参数的代码(大约500行C代码);
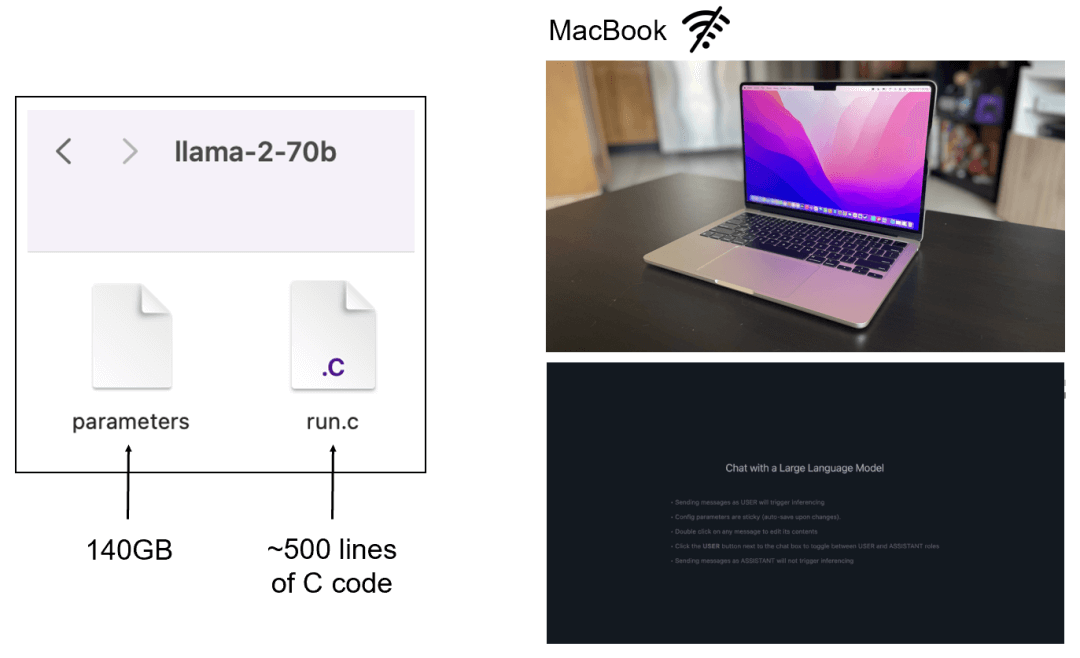
- 但大模型真正的难点主要在训练这个步骤上,以上面提到的这个140GB的参数文件为例,这其实是通过大量GPU算力将大约10TB的互联网数据片段有损压缩后得到的(6000块GPU跑12天,大约2百万美金的预训练成本)。训练完成后的大模型做推理计算的成本是相对低很多的;

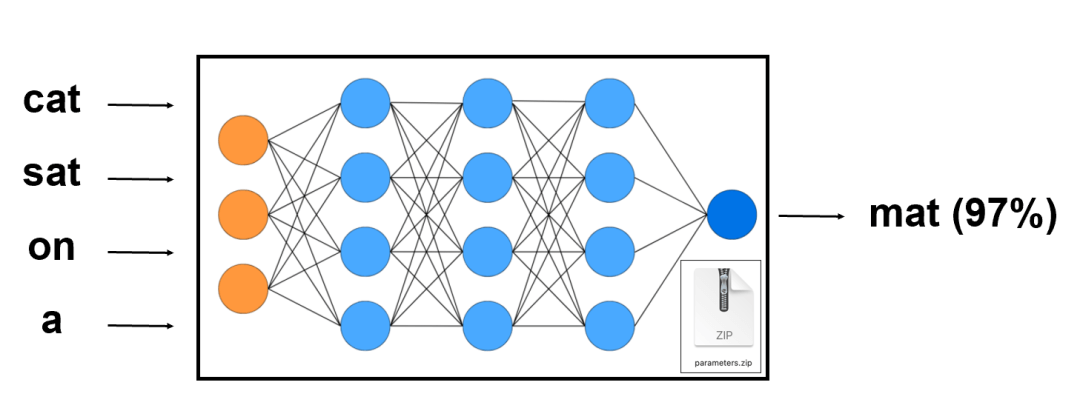
- 大模型,或者说这套神经网络的基本任务是尝试预测序列中的下一个单词,例如在“cat sat on a”这四个单词的序列中,神经网络可能会预测下一个单词是“mat”,概率为97%。如果你持续重复这个过程,就能得到一篇大模型“梦想”出来的完整文章;
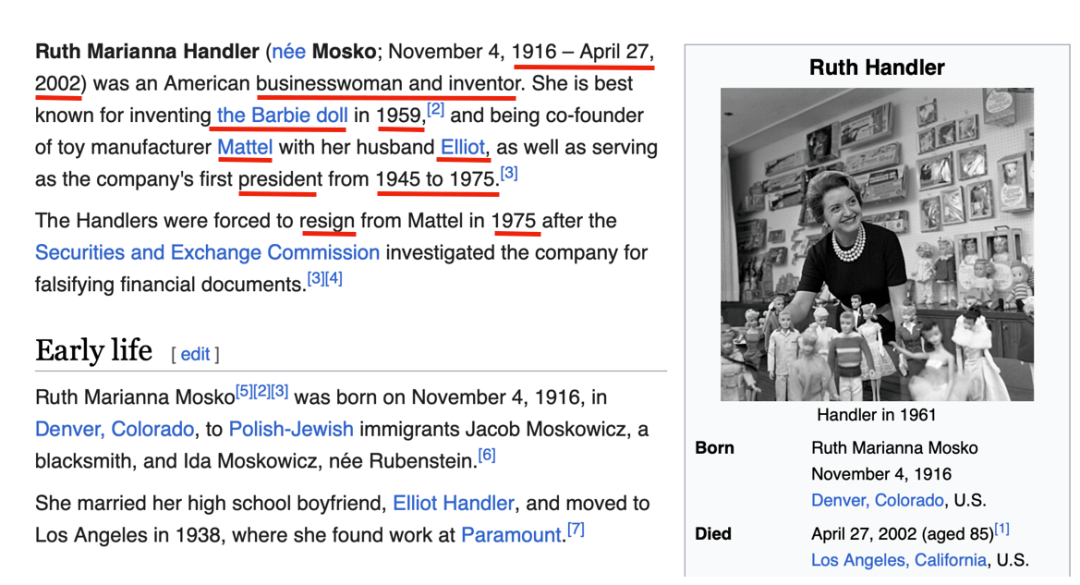
- 尽管这种下一个单词预测的能力听起来很简单,但做起来其实挺难的,会迫使神经网络学习大量关于这个世界的信息,并将其编码在参数中。以下图这个维基百科关于芭比娃娃的创始人Ruth Handler的内容为例,如果大模型要预测回答图中标红的个人信息(例如生卒年月),他就必须认真了解Ruth Handler这个人,然后将知识压缩存储在参数中。
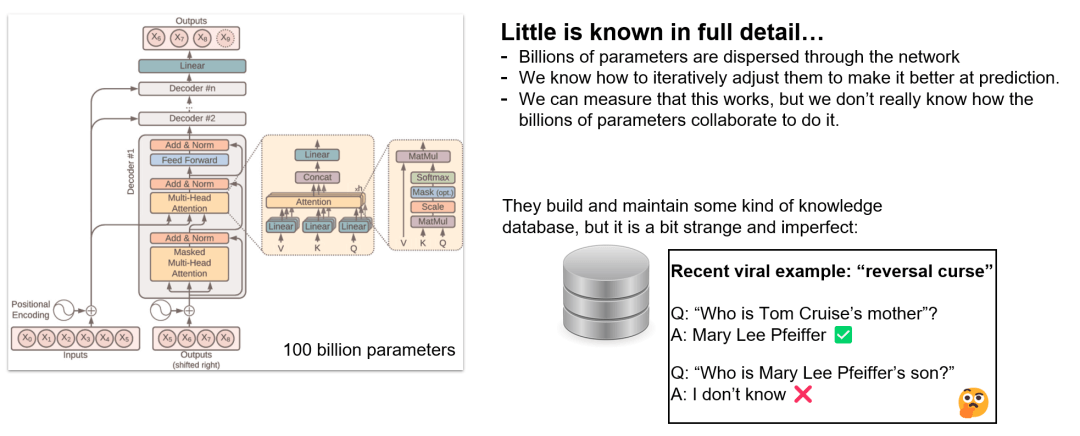
- 可以将大模型想象为一种绝大部分人无法理解的神秘产物… - 以下图这个基于transformer架构的神经网络为例,我们知道每个架构细节,也知道如何迭代调整其中包含的百亿参数使得输出结构更优,但我们目前仍不知道这些参数具体是如何互相协作来实现这一点的。例如这套神经网络中似乎是有某套数据库,但是又和我们常见的数据库都不一样 - 不久前ChatGPT曾经被发现一个名为“反转诅咒”的bug,当你问他“谁是汤姆克鲁斯的母亲”时他能正确回答是玛丽李菲佛,但是当你问“玛丽李菲佛的儿子是谁”的时候他却不知道了…
- 前面提到的预训练步骤完成大模型就能“梦想”出类似各种互联网文档的内容,但如果你希望让其能类似一个助理一样来回答大家的问题,就还要再通过微调训练这个第二步来获得一个助理模型。这里需要额外引入一套高质量的QA数据集。不同于预训练步骤中使用的海量+质量参差不齐的数据集,在微调时,基本就是靠人工生成的高质量对话。例如一个十万量级的QA数据集中可能包含这个问题 -你能写一个关于垄断一词在经济学中的含义的简短介绍吗?而下面的答案就是一位熟悉经济学领域的专家所写;

- 总结来说,如果你想训练一个自己的ChatGPT,步骤如下。简单说预训练阶段是在互联网数据集上进行的大规模训练,主要关注在知识的积累;而微调阶段则是所谓的对齐,即使得模型回答能从互联网文档的格式转换为问答格式,使其能更好地为大众所用:
阶段一:预训练(频率大约每年或者更高)
- 下载大约10TB的互联网文本数据;
- 准备一个包含约6000个GPU的算力集群;
- 使用神经网络将文本进行压缩处理,需要大约200万美元+12天;
- 得到基本模型;
阶段二:精调(频率大约每周或者更高)
- 准备标签说明文档;
- 雇用人员收集100,000个高质量的理想问答对,或者是对比数据;
- 在这些数据上精调基本模型,需要大约1天;
- 得到助理模型;
- 进行大量评估;
- 部署;
- 对模型进行监控,收集错误情况,然后回到步骤1;
虽然上述两个步骤后就能获得一个类似ChatGPT的助理模型,但很多时候我们还会引入一个名为人类反馈强化学习/RLHF的第三步骤。以llama2为例,我们会请人对模型的各种回答进行评分,以此数据进一步微调使得模型在安全性和可用性方面进一步提升;
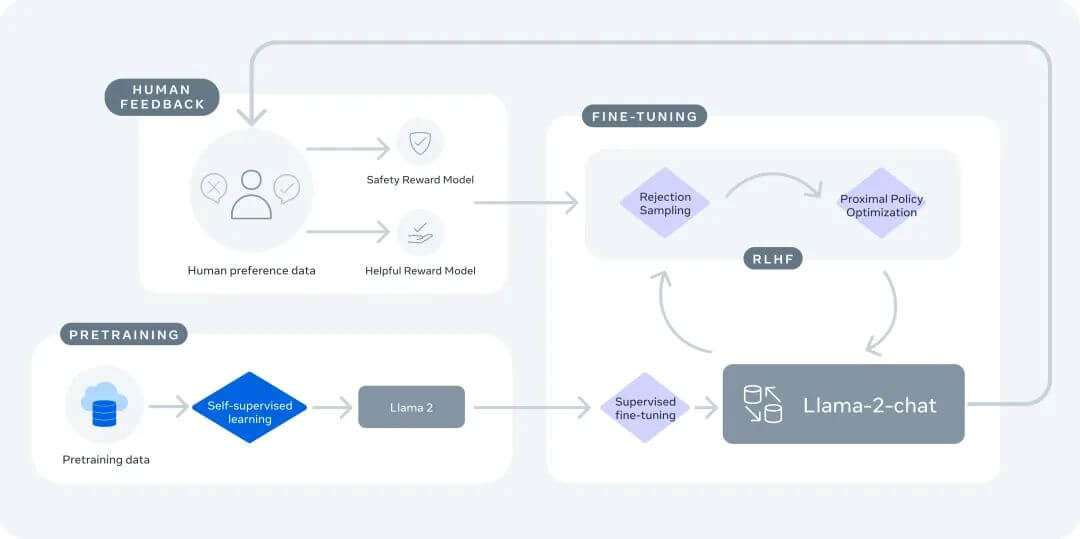
值得指出的是,步骤二和步骤三中提到的这些“人工标签”的过程,其实目前已经是人机协作的结果:
- LLMs已经能像人类一样参照并遵守标签指南文档的指示;
- LLMs可以创作初稿,然后由人类将这些初稿拼接整合为最终稿;
- LLMs可以根据给定的指示,对标签进行审核和评价;
第二部分:大模型的未来
当前大模型发展的重点方向主要是下面这三点:
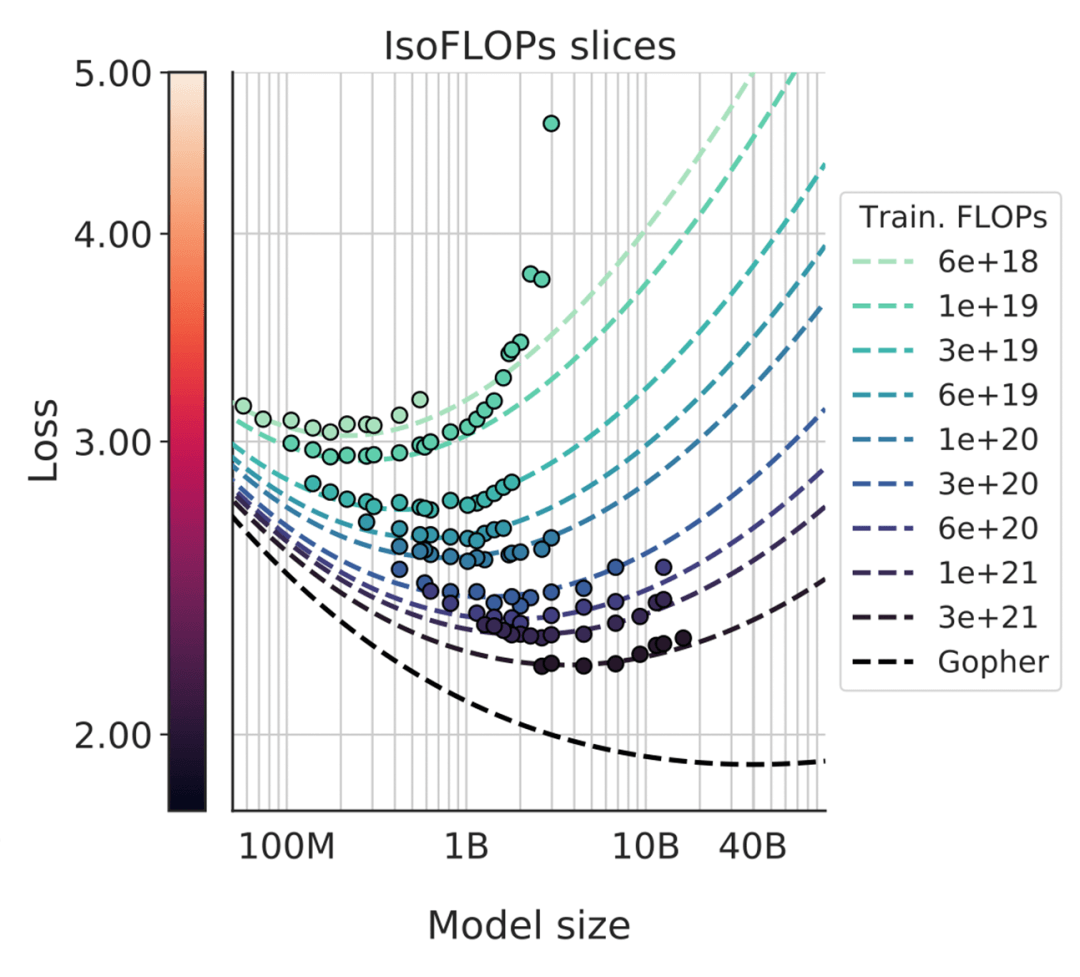
1、LLM的规模化定律 – 大就是好。大语言模型在下一个单词预测任务的准确性方面的表现是一个非常平滑且可预测的仅两个变量的函数。只需要知道的神经网络中的参数量(n)和训练的文本量(d),就可以非常有信心地预估LLM的性能,而且这条曲线似乎并没有见顶的迹象。也就是说,当前不必考虑算法的优化,单纯靠加大参数量和训练文本量就能持续提升大模型的性能。
2、当模型开始使用工具 - 类似人类能通过大量使用工具来解决各种各样的任务一样,给与LLMs各种工具能极大加强其实用性,例如上网浏览、计算器、编程和调用其他模型,最新的ChatGPT+Dalle3就是个很好的例子(下图是ChatGPT绘制的时间穿梭 - 星巴克的变迁之路,从不存在星巴克的1920年到刚开店的1970,到大家熟悉的2020年,再到未来的2050年)

3、 “多模态” - 让大模型拥有视觉和听觉,预计在2024年大家能看到更多多模态相关的大模型应用。
一些大模型的前沿研究方向:
1、能否让大模型也具备系统二的能力?《思考:快与慢》这本经典著作,中提出了人脑存在系统一和系统二这个理论:系统一是快速、本能和自动的思维过程。例如,当被问到2加2等于多少时,你不需要思考就能回答答案是4。但当被问到17乘24等于多少时,你需要动用大脑中更为理性的部分来执行计算得到答案。
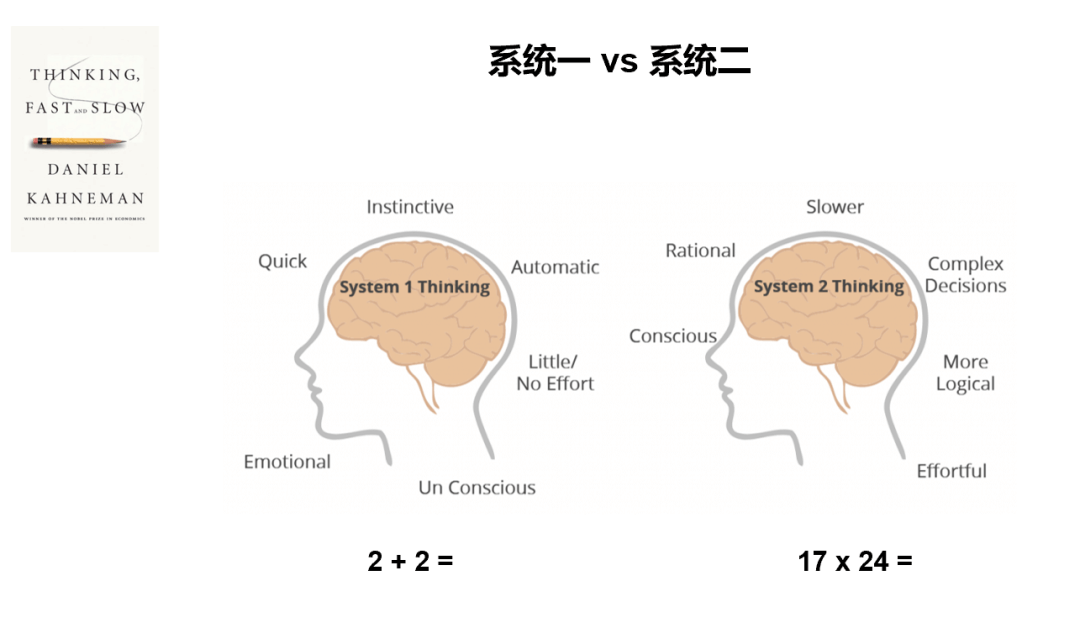
目前大模型由于其基本原理是“预测序列中的下一个单词”,所以基本只有系统一的能力。研究人员目前在做的尝试就是 – 如何给大模型添加系统二能力?无论是大家熟悉的let’s think step by step 的思维链COT,还是决策树思维链TOT, 其实都是尝试在将人类是如何运用系统二的思路转移到大模型上。或者说我们希望能告诉大模型,我愿意等待30分钟来换取一个更靠谱的答案,也就是用时间换取精确度。但是目前大模型整体在实现系统二的能力上还不够完善;
2、自我完善能力 - AlphaGo提供了一个很好的例子,他的成长经历了两个阶段:首先是通过模仿人类专家的棋谱来学习。这种方法虽然有效,但无法超越人类;其次是左右互博 – 创建一个自己和自己对局的沙箱环境,将最终是否获胜作为奖励指标,通过海量的自我对弈来成长。从下图可以看出来,在Deepmind的测试中,这个通过左右互博来学习的alphago模型只用了40天就超越了所有其他的alphago版本。
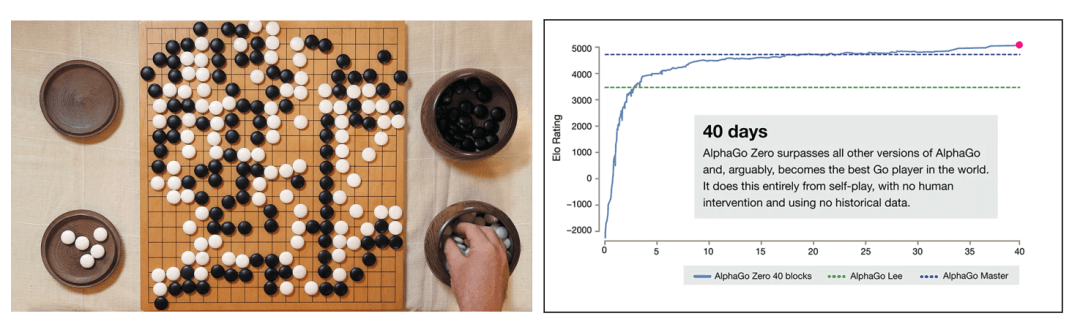
值得指出的,在围棋这个领域上是比较容易构建一个自我完善的奖励模型的,因为我们只要评估最终是否获胜这个关键指标。换到大模型的情况下,如果是普通的通用性任务,其实很难给出一个完美的奖励模型,例如你很难说某个语言描述比另一个更好。但是,类似围棋,在一些垂类领域中,如果什么是值得奖励的结果是更明确的,这种自我学习完善的模式是有可能被复制的;
3、自定义大模型成为特点领域的专家 - 最新OpenAI推出的GPTs就是这方面的很好例子。

如果在最后对大模型的未来做一个总结,其实大模型很可能就是一套未来的操作系统!
将上面提到的内容整合到一起,你会发现大模型很快就能:
- 阅读和生成文本;
- 在所有的学科知识方面,比任何人懂得都多;
- 浏览互联网;
- 利用现有的软件基础设施,如计算器、Python、鼠标/键盘等;
- 看到并生成图像和视频;
- 有听和说的能力,甚至生成音乐;
- 使用系统二进行深度思考;
- 在垂类领域进行自我完善;
- 根据特定任务进行定制和微调,能从应用商店中找到你想要的各种专家;
- 与其他大模型进行交互;
将拥有这些能力的大模型和现有的操作系统进行对比,你会发现几乎都能对应得上,如下图,而且最神奇的是,你只需要通过用自然语言接口来对这个操作系统进行访问!
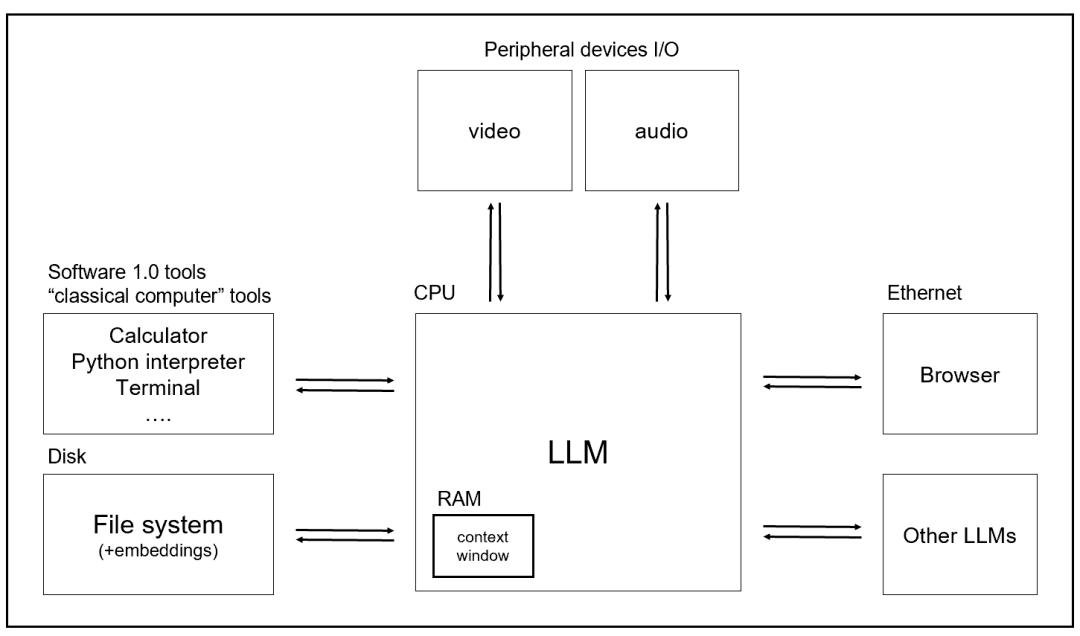
而且,从操作系统的生态角度来看,你会发现大模型和操作系统也呈现了相同趋势,无论是下图的windows/linux生态还是ios/安卓生态来看都是。