OpenAI的DevDay最新披露-"精进大型语言模型性能的各种技巧"专场ppt分享
OpenAI刚刚放出了他们在不久前的DevDay上面几个闭门会的视频全程内容,其中一个名为”A Survey of Techniques for Maximizing LLM Performance”(精进大型语言模型性能的各种技巧)是我觉得最有意思的一场,因此专门将这个演讲ppt的核心重点分享如下:
优化LLM的性能并不总是线性的
很多时候,人们会先进行提示工程(prompt engineering),然后进行检索增强生成/RAG(retrieval-augmented generation),然后进行微调,这是优化LLM的常见方式。然而,这种方式有问题,因为RAG和微调解决的是不同的问题。有时你需要前者,有时你需要后者,有时你可能都需要,这取决于你要处理的问题的类别:
- 优化有两个轴线方向可以考虑:一个是上下文context优化,即模型需要了解什么信息才能解决你的问题。另一个是LLM优化,即模型需要以何种方式行动,才能真正解决你的问题;
- 你应该做的第一件事是从提示词优化开始进行评估,找出你如何持续评估输出的质量。直到你可以确定,这到底是一个上下文问题还是一个我们需要模型如何行动的问题?如果是前者,请转向RAG,如果是后者,请转向微调。当然有些时候你会同时需要两者,而且应该再次强调这不是一个线性的过程,而可能是类似下图这样的有反复横跳的过程;
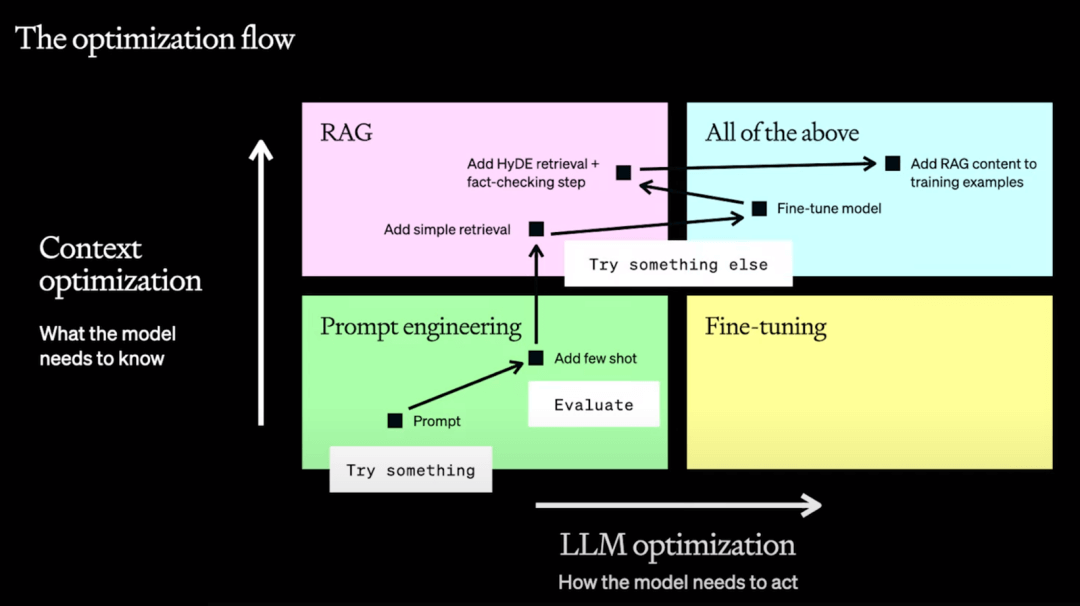
提示词工程 - 最理想的起点,也可能是非常好的终点
- 编写清晰的指令
- 将复杂的任务分解为更简单的子任务
- 给 GPTs 时间去“思考”
- 系统地测试改变
- 提供参考文本
- 使用外部工具
RAG/检索增强生成 - 给模型提供特定领域全部内容
- 尝试了提示词优化后,你的下一步是要看到底先尝试RAG还是微调(并不总是微调优于RAG!)。这里可以将其理解为短期记忆与长期记忆的选择问题 - 如果我们把这个问题想象成为准备考试,你的提示就是给他们需要完成考试的指导。微调就像你之前学习的所有方法和需要回答这些问题的实际框架。而RAG就像在他们实际参加考试时给他们一个开卷用的课本。如果他们知道方法和需要寻找的内容,那么RAG意味着他们可以打开书本,翻到正确的页面,轻松找到他们需要的内容。
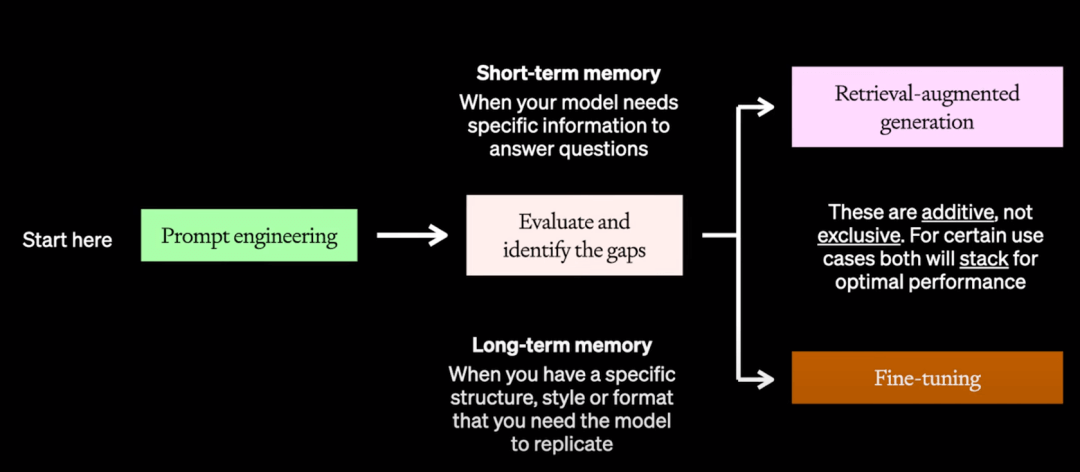
一套常见的RAG流程
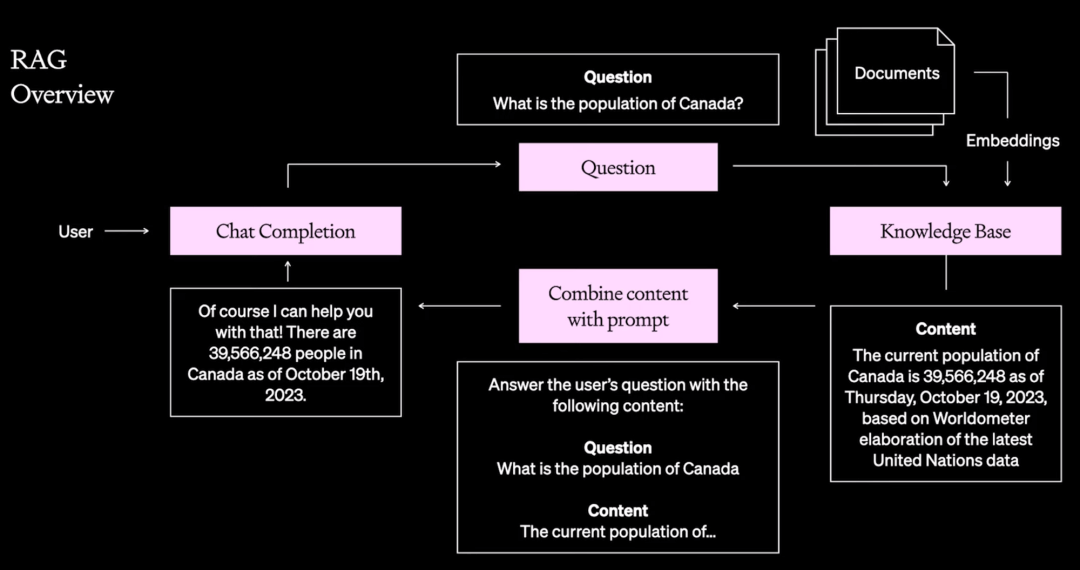
- 对RAG进行优化能大幅提升回答质量 - 需要专家来进行多轮尝试
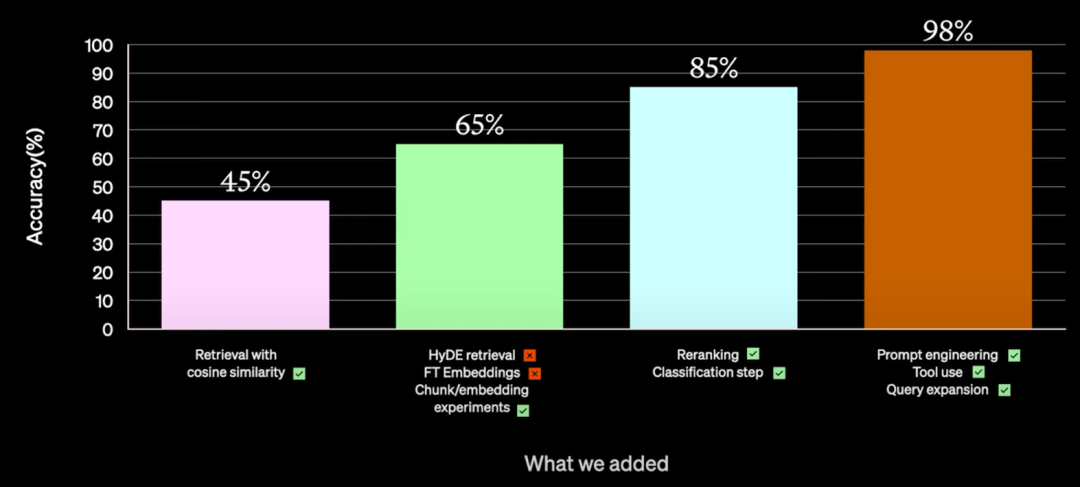
- 虽然随便通过某个LLMops你也能获得一个RAG能力的AI-bot,但是最初的回答质量其实是很容易出问题的。参考下图,即使是OpenAI的顶级工程师,依然是在尝试了多次不同的优化后才为某个用户的RAG应用案例的回答质量从最开始的45%提升到最后的98%(顺道提一下他们提到了针对这个案例也试了做微调,效果不太好,正好再次说明这类型特定领域的回答用RAG效果更好的大原则)。
Ragas - RAG评估框架
测量四个指标。其中两个衡量 LLM 回答问题的效果,另外两个衡量内容和问题的相关性。通过观察分值会对如何优化RAG产生良好指导意义。

微调 - 在更小、特定领域的数据集上继续训练过程,以优化模型以完成特定任务。
请注意 - 如果提示词工程优化的效果不好,很可能就不用尝试微调了…
微调的优点:
- 提高模型在特定任务上的性能
- 经常是比提示工程化或FSL更有效的提高模型性能的方式;
- 提高模型效率
- 减少模型在您的任务上表现良好所需的token数量;
- 将大型模型的专业知识提炼到较小的模型中;
微调的最佳实践:
- 从提示工程化和 FSI 开始 - 从低投入的技术开始,快速迭代并验证您的用例;
- 建立基线 - 确保你有一个性能基线来对比你的微调模型;
- 从小处开始,注重质量 - 数据集可能难以构建,从小开始并有意识地投入。优化较少的高质量训练示例;
微调+RAG
- 微调模型以理解复杂的指令;
- 最小化提示工程token数,为检索的上下文提供更多空间;
- 使用 RAG 将相关知识注入上下文;