AI如何通过“切割术”理解我们的语言:探索大语言模型时代的语言不平等问题
在AI领域,大语言模型已经取得了惊人的进步,可以执行包括翻译、文本生成和情感分析等多种任务。但当我们在和这些基于大语言模型的AI对话时,例如ChatGPT,你是否有想过AI是如何理解我们所说的语言的呢?其秘密在于一个可以被称为”切割术”(Tokenization)的过程。然而,并非所有语言在这个“切割化”的过程中都被平等对待…
AI的“切割术”
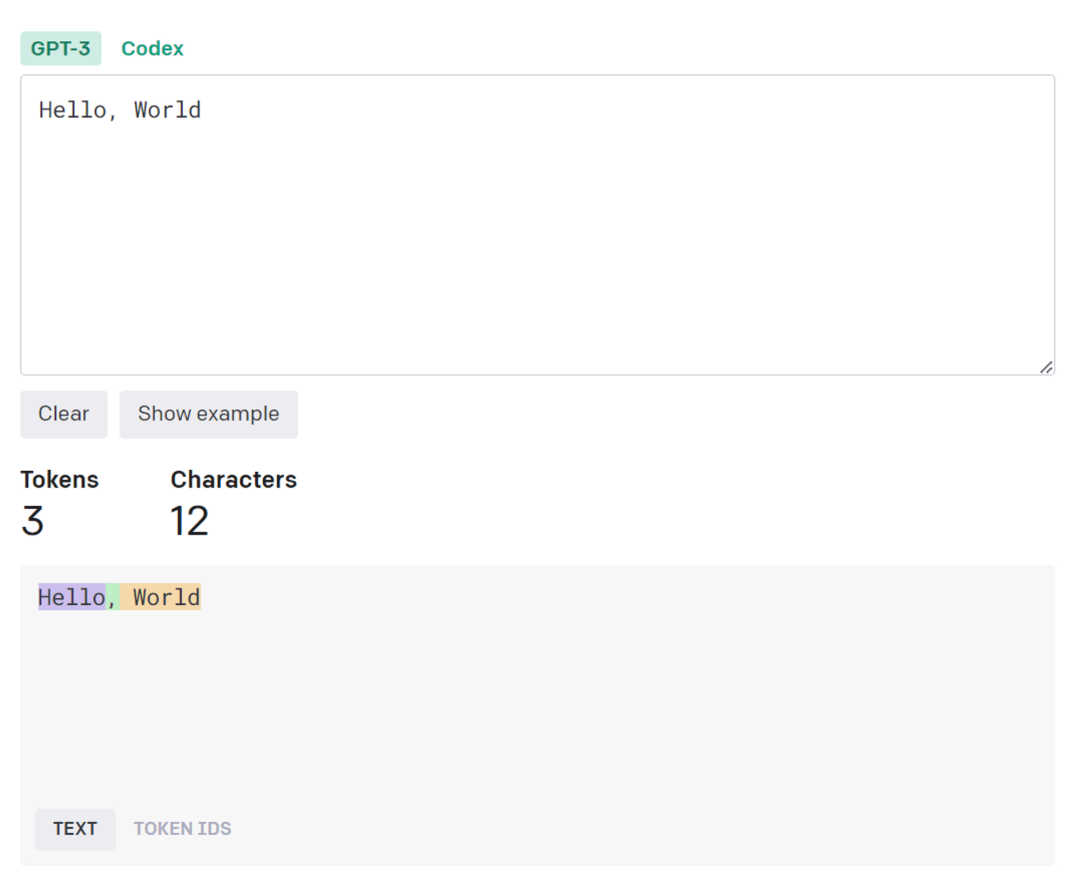
所谓的“切割术”,你可以把它想象成是一个把一段话分割成一个一个标记块(token)的过程,这些token可以是单词、数字,或者标点符号等。例如在英语中,”Hello, World”会被分解为三个标记块(token):“Hello”,“,”和“World”,正如下图中下半部分出现的三个不同的颜色块。AI正是通过这样的“切割术”将我们对其说的话进行了处理后,才能更好地进行理解和回答。
“切割术”针对不同语言的不平等
但是,这套“切割术”在处理不同语言时,情况会变得复杂。对于英语,一个单词通常会被视为一个标记块(token)。但在其他语言中,同样的信息很可能需要更多的token来表示。具体来说,以下面的两个对比截图为例:
- 当使用英文时,所需要的标记块(token)数是最少的。我们也可以将同样信息下,其他语言所需的token数是英文的多少倍来判断其他语言的“被切割效率”;
- 西班牙语、法语、德语等常见拉丁语系语言所需要的token数略微比英文多一点,效率上属于第二梯队,大约是英文的1.4-1.5倍;
- 中文的整体表现其实还不错,所需要的token数大约是英文的1.7倍,而且很有趣的是简体中文的效率会略微高于繁体中文;
- 日语和韩语的效率差不多,低于中文,大约是2.1-2.2倍;
- 再来一个最极端的例子,如果是缅甸语,倍数会达到惊人的10倍这个数值!


为什么会出现这种“不平等”的情况
这种通用型技术在处理不同语言中的不平等情况其实很早前就存在了。以百年前的革命性技术-电报为例,这套基于”莫尔斯电码“的技术在处理不同语言之间速度和成本就存在巨大差异。例如将一条信息编码和传输到中文(与英文等效的信息相比)需要:
- 两倍的成本;
- 15-20倍的时间;
其背后的原因是因为电报最早主要就是为了英文所设计的,因此优先考虑了传输英文时的性价比。但是,中文作为一种形意文字的语言,比较难直接套用这套规则。后来是一个名叫维吉耶的法国人为汉字设计了一个映射系统,将其映射到莫尔斯电码上 - 每个汉字都被映射到一个四位编号上,然后再被翻译成莫尔斯电码。因为这需要在代码本中查找编号,所以从耗时角度和传输成本角度都是比较高的。

同理,一方面最早在AI的NLP(自然语言处理)年代,提出这套语言切割术(Tokenization)的研究者也是优先基于英文来进行考虑。所以在处理像汉语或日语这样的语言时,由于它们的写作系统和英语有很大的不同,例如字词之间没有明显的空格,这导致标记化过程相对复杂;另一方面,在现在的大模型年代,由于研究者需要提供海量的数据供大模型来学习,而绝大部分的语料也都是以英文的形式而存在,也因此会进一步针对如何高效处理英文信息来进行优化。
这种“不平等”在大语言模式时代意味着什么?
类似在电报年代出现的问题,这种因为“切割术”针对不同语言的效率不一会导致:
- 使用非英文来和大模型沟通的成本提升 - 按照OpenAI的api收费规则,是依据传输的token数量进行收费,也就是说如果使用缅甸语进行和大模型的沟通的话,成本将是使用英文的十倍!
- 同时,因为需要使用更多的token,也会导致处理的速度/性能变慢;
此外还有一点在基于transformer神经网络架构下的大模型技术会引入的一个全新问题:
- 由于架构设计导致了目前的大模型仅能处理某个最大长度的token数信息,这意味着如果你使用非英文和大模型进行沟通,能够处理的文本信息上限也是明显更少的;
考虑到目前大模型已经在广泛地被使用到全球所有国家,这就引出了一个有趣的问题:在一个全球化的环境中,我们如何建立一种更好地支持全球语言的通用型底层技术?
一方面我们希望能有研究人员针对如何优化“切割术”在不同语言的“不平等”上面能去做出一些工作;另一方面也能理解,如果要建设一套能支持全球语言的通用底层技术,其中必然会有妥协的存在。只要能保持在一个合理的比例内,未来随着底层的运算能力和传输速度的进一步提升,这些语言间的“不平等”将会可以忽略不计。
reference