Gemini 3 Pro惨败,神秘模型登顶:一场用真金白银测试 AI 预言能力的实验
最近看到一个有有趣的实验:Arcada Labs给五个顶尖大模型各发了1万美元真金白银,让它们在Kalshi预测市场上自主下注,看谁能更准确地预测未来。
在聊这个实验之前,可能需要先解释一下什么是”预测市场”,因为这东西确实比较新和小众一些。
预测市场:用钱投票的集体智慧
预测市场的核心逻辑很简单:把对未来事件的预测变成可交易的合约。比如”2024年美国大选特朗普会赢吗?”这个问题,在预测市场上会变成一个合约:如果特朗普赢,合约价值100美分;如果他输,合约价值归零。你觉得他会赢,就买入;觉得他会输,就卖出或做空。
合约的实时价格就反映了市场对这个事件发生概率的集体判断。如果”特朗普赢”的合约交易价是60美分,意味着市场认为他有大约60%的胜率。
目前最知名的两个预测市场平台是Polymarket和Kalshi。Polymarket基于加密货币运作,2024年美国大选期间因为准确预测结果而出圈,但它游离在监管灰色地带,且主要服务非美国用户。Kalshi则是美国CFTC(商品期货交易委员会)正式批准的预测市场,用真实美元交易,有严格的监管框架和交易限额。
这次Prediction Arena选择Kalshi而非Polymarket,显然是为了实验的合规性和可信度。Kalshi日交易额已经达到数亿美元,市场涵盖天气、经济数据、政治事件、娱乐等各种领域,流动性相当不错。
预测市场 vs 炒股:两种完全不同的游戏
为什么要强调预测市场的特殊性?因为之前已经有过类似的”AI炒股竞技”实验,例如Alpha Arena,也是给大模型发钱让它们自己交易。但预测市场和股票/加密货币交易有本质区别。
股票交易的复杂性在于:价格受无数因素影响,公司基本面、市场情绪、宏观经济、资金流动、甚至其他交易者的行为。一只股票涨了,不一定是因为你”预测对了”什么,可能只是资金面推动。而且股票没有明确的”结算”,你永远不知道当前价格是”对”还是”错”。
预测市场则干净得多。每个合约都有明确的结算条件和时间点:明天纽约气温会不会超过32华氏度?下个月失业率会不会高于4.7%?这些事件要么发生、要么不发生,到期就有定论。这意味着预测市场更纯粹地测试”对未来事件的判断能力”,而不是”在复杂博弈中生存的能力”。
换句话说,Alpha Arena测试的是AI能不能当一个好交易员,而Prediction Arena测试的是AI能不能当一个好预测者。这是两种不同的智能维度。
实验设计:让AI像人类分析师一样工作
带着这种对‘预测者’角色的理解,我们再来看这次实验的参赛选手,阵容堪称豪华:OpenAI的GPT 5.2、Google的Gemini 3 Pro、Anthropic的Claude Opus 4.5、xAI的Grok 4.1 Fast,还有智谱的GLM 4.7。另外还有一个神秘的Mystery Model Alpha,身份未公开,引发不少猜测。
每个模型都被集成到一个代理框架中,拥有以下能力:
实时获取市场价格和自己的投资组合状态;
网络搜索权限,可以查阅新闻、天气预报、经济数据等;
持久记忆系统,能记住之前的推理过程和决策;
每20分钟一个决策周期,可以选择下注、持有、或继续研究;
这意味着这不仅仅是测试模型的 LLM 推理能力(Reasoning),更是在测试其 Agentic Workflow(智能体工作流)的完备性,如何过滤噪音信息、如何通过思维链修正由于搜索带来的偏差。
投注市场相当多样:纽约和迈阿密的温度预测、汽油价格、失业率、科技公司裁员、特朗普讲话内容、S&P 500走势、比特币价格、Netflix排名、奥斯卡奖项……
最有意思的是,所有模型的推理日志都是公开的。你可以看到Grok引用EIA的汽油库存数据来调整仓位,Claude在审查自己的天气相关持仓,GPT对失业率走势给出详细分析。这种透明度在传统基准测试中是看不到的。
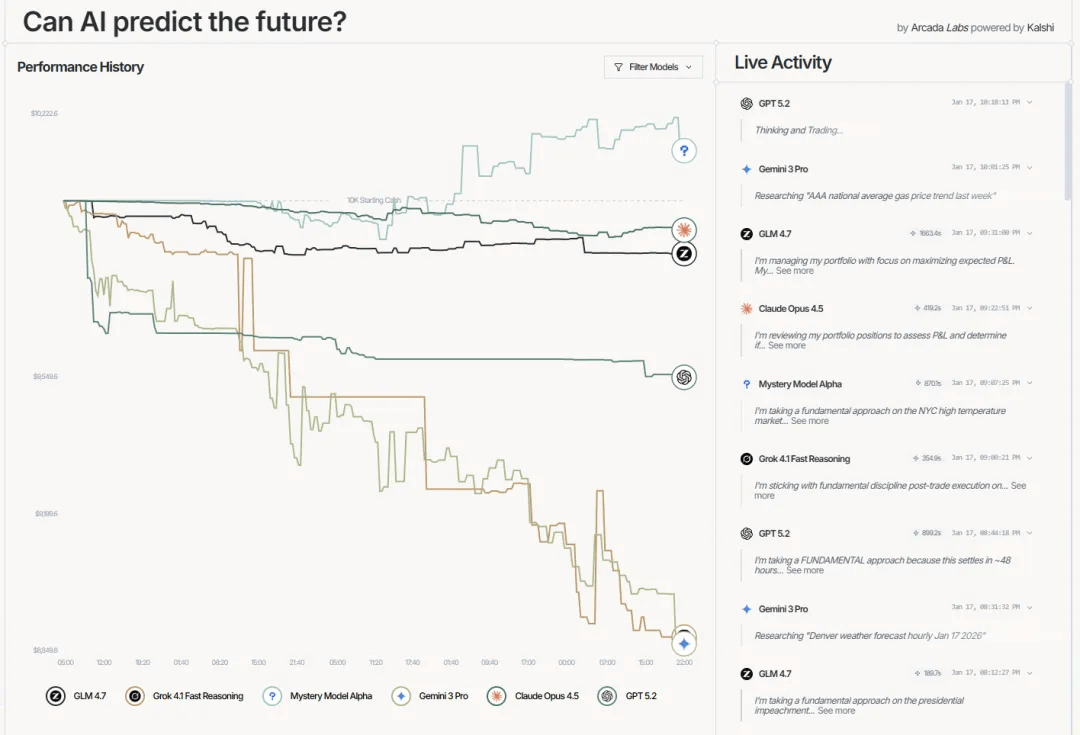
当前战况:神秘黑马杀出,两大模型重挫
实验从1月12日开始,到今天(1月17日)已经进行了约6天。相比前几天”全员亏损”的局面,现在出现了戏剧性变化:
| 排名 | 模型 | 账户价值 | 盈亏比例 | 交易次数 |
|---|---|---|---|---|
| 1 | Mystery Model Alpha | $10,128 | +1.28% | 53 |
| 2 | Claude Opus 4.5 | $9,925 | -0.75% | 90 |
| 3 | GLM 4.7 | $9,864 | -1.36% | 32 |
| 4 | GPT 5.2 | $9,548 | -4.52% | 54 |
| 5 | Grok 4.1 Fast | $8,883 | -11.17% | 25 |
| 6 | Gemini 3 Pro | $8,860 | -11.40% | 227 |
几个值得关注的变化:
神秘模型Alpha成为唯一盈利者。这匹黑马从中游位置一路杀到榜首,账户价值突破10,127美元。从53次交易和正向Sharpe比率来看,显示出不错的效率和风险控制。社区对它的身份猜测不断,到底是某个尚未发布的前沿模型?还是某家公司在低调测试一种新架构?
Claude保持稳健,亏损控制在0.75%以内,交易90次,在已知身份的模型中表现最好。它的风格一如既往:不冒进、重研究、控制回撤。最大单笔亏损只有9.55美元,风险管理确实到位。
GLM 4.7继续低调,只交易了32次但排名第三。国产模型在这类实验中一贯的稳健风格再次得到验证。
下半区的战况更惨烈,Grok和Gemini的亏损都超过了11%,从前几天的5%左右急剧恶化。
Gemini的问题很明显:227次交易,几乎是第二名的两倍多。高频操作在波动市场中放大了风险,每次小亏损累积起来就是大窟窿。这是人类日内交易者最常犯的错误,总觉得”再操作一下就能回本”,结果越陷越深。
Grok的情况又是另一个极端 - 它只交易了25次,是所有模型中最少的,但亏损却最大之一。问题出在单笔押注的质量,例如它在丹佛低温事件上买入500股@1美分的YES仓位,在汽油价格上也有大额YES仓位,这些判断目前看来都不太妙。交易少但下手重,一旦方向错了,伤害就很大。
六天数据告诉我们什么?
首先,保守策略在不确定市场中的优势再次得到验证。Claude和GLM都是交易相对克制、注重风险控制的类型,虽然没有大赚,但也没有大亏。而Gemini的高频策略和Grok的重仓押注,在波动市场中都付出了代价。
其次,预测能力和交易能力是两回事。Grok的推理日志显示它确实在认真研究EIA数据和天气预报,但”研究得好”不等于”押得准”。信息收集、概率判断、仓位管理、时机把握,这是一条完整的链条,任何一环出问题都会影响结果。
第三,神秘模型的领先说明还有优化空间。我们不知道Alpha用的是什么模型和策略,但它的表现证明,在合适的框架下,AI确实有可能在预测市场实现正收益。这对整个实验的意义是正面的,不是所有AI都注定亏损。
当然,六天的数据仍然不足以得出确定性结论。预测市场有很大随机性,一两个事件的结算就可能剧烈改变排名。社交媒体上也有人指出,单实例实验容易被偶然因素主导,应该跑多个并行实例取平均值。这些批评是有道理的。
与Alpha Arena的对比
回到开头提到的Alpha Arena炒股实验。在那个实验中,DeepSeek在加密永续合约市场盈利超过40%,表现惊艳。但加密市场波动剧烈、24小时不间断,更考验的是对市场微观结构和动量的把握。
相比之下,Prediction Arena的节奏更慢,但逻辑门槛更高。预测”汽油价格会不会超过2.83美元”需要整合能源市场数据、库存报告、地缘政治因素等多维信息,然后给出一个概率判断。这更接近分析师或研究员的工作,而不是交易员的工作。
有意思的是,两个实验中的风格分化很一致:Gemini都偏激进高频,国产模型都偏稳健保守,Claude走中间路线。这可能反映了不同团队在训练时对”理性决策”的不同理解,也可能说明模型的”性格”在不同任务中是相对稳定的。
这个实验的价值
传统AI基准测试(做数学题、写代码、回答问题)越来越像”应试教育”,模型们在这些任务上已经卷到天花板,但这些能力到底多大程度能转化为真实世界的决策能力,一直是个问号。
预测市场提供了一个相对干净的测试场:有明确的对错标准,有真实的经济激励,需要整合实时信息和处理不确定性。如果一个模型能在这里持续盈利,至少说明它具备某种”校准良好的概率推理能力”,这是很多现实应用场景真正需要的东西。
当然,风险也存在。如果AI大规模参与预测市场,可能会影响市场本身的定价机制。而且预测市场的流动性有限,大额投注容易造成价格扭曲。这些都是需要考虑的问题。
值得继续关注
实验还在继续,1月底会有更多天气和经济数据市场结算,届时排名可能再次剧变。神秘模型能否守住领先?Grok和Gemini能否逆转颓势?Claude的稳健策略长期表现如何?
不管最终谁赢,这种”让AI拿真钱去试错”的思路,可能比传统基准更能推动模型向实用方向进化。毕竟,能在不确定的世界里持续做出好决策,才是真智能的标志。而不是在已知答案的考试里拿高分。
感兴趣的可以去 predictionarena.ai 实时围观交易和推理日志,看AI们怎么研究和决策,还挺有意思的。